QlikView Direct Discovery – Working & QlikView Data Query
Job-ready Online Courses: Knowledge Awaits – Click to Access!
In our last tutorial, we talked about QlikView T-Test. Here, we will learn about What is QlikView Direct Discovery.
Moreover, we will discuss field types and variables of Direct Discovery in QlikView. In addition, we study the QlikView Direct Query and QlikView Direct Discovery Data Model Vs In-Memory.
The term Big Data has been creating a buzz since quite some time now and all the new Business Intelligence tools focus on analyzing big data.
In QlikView also, big data or large amounts of data from external data sources can analyze along with other kinds of data through a script-based feature known as Direct Discovery.
So, let’s start QlikView Direct Discovery.
QlikView Direct Discovery – Working & QlikView Data Query
What is QlikView Direct Discovery?
Direct Discovery is a unique concept of hybrid data analysis. Traditionally, in QlikView, in-memory data is the main source of data to use for business analytics.
However, we know that having only in-memory data as the main source of data is not enough. This inefficiency of the software counter by Direct Discovery feature which lets the user access the ocean of information in the form of data.
Also, what enhances the business of an enterprise is how well are they able to keep up with the new trends in business and maintain their market value.
Direct Discovery achieves by analysing as much relevant data as possible in order to get closest to what is happening in the real world.
QlikView enables this by the Direct Discovery feature through which a user can fetch data from both in-memory and external databases (big data) and use this data as a single data set in a document.
The QlikView Direct Discovery follows a query model and both, in-memory data and external database data follows the associative model of QlikView once loaded.
However, one common challenged faced every time a software gets to deal with big data is its volume and variety.
Do you know what is the best practice for Data Modeling in QlikView?
This problem solves as direct discovery is a query-based approach where queries send to retrieve and store only some part of the big data into the QlikView’s memory keeping the rest at the source.
QlikView Direct Discovery provides a great deal of transparency and lets any type of user get access to the big data along with in-memory data to use them together for business analysis.
This also alleviates the issue of data silos.
QlikView Direct Discovery Field Types
The QlikView Direct Discovery table structure has data fields of three types;
a. Dimension Fields
The Dimension fields have the descriptive texts defining the values contained in that field. The dimension fields load and define by the keyword DIMENSION in the script.
These fields are the only fields that load in memory during direct discovery from the external database and also use in establishing associations between in-memory data fields/field values and direct discovery fields and values.
b. Measure Fields
Entirely different from the dimension field, the Measure fields only contain numeric values upon which calculations are to perform using aggregation functions.
Aggregation functions like Sum, Min, Max, Avg, Count use on the data values in measure fields. The measure fields do not load into in-memory indirect discovery tables.
This is because the aggregate functions apply at the database level and do not occupy the in-memory in applying aggregation on data.
c. Detail Fields
The detail fields are simple fields that contain descriptive and important comments or remarks on the data being used.
The data in detail fields do not use as dimension or measure. Hence, in any expression. Any field can designate as a Detail field using the keyword DETAIL.
The table given below shows some characteristics of the three field types.
| Field Type | In-Memory? | Forms Association? | Used in Chart Expressions |
| DIMENSION | Yes | Yes | Yes |
| MEASURE | No | No | Yes |
| DETAIL | No | No | No |
QlikView Direct Discovery Variables
There are certain dedicate variables use in direct discovery statements. In this section, we are going to learn different types of QlikView direct discovery variables based on the purpose of the action they perform.
a. QlikView Direct Discovery System Variables
- DirectCacheSeconds
The caching limit in charts can be set using this variable. The results clear once this time limit reaches.
SET DirectCacheSeconds=1800
- DirectConnectionMax
Using this variable you can invoke pooling capabilities in QlikView direct discovery i.e. parallel calls can be made requesting data from the database at a time. By default, the limit is set at 1.
SET DirectConnectionMax=10
- DirectUnicodeStrings
This variable enables the ANSI standard wide character extended Unicode string literals (N’<extended string>’). The value of the variable DirectUnicodeStrings is turned ‘True’.
Usually, this feature is not supported but it can be invoked through this variable in QlikView direct discovery statement.
SET DirectUnicodeStrings=‘True’
- DirectDistinctSupport
The queries sent to the database can group by deactivating or setting the DISTINCT variable to false. That is why the variable DirectDistinctSupport is set as False so that queries can group using GROUP BY.
SET DirectDistinctSupport=‘False’
- DirectEnableSubquery
In larger tables and script setups, sub-queries send to the database instead of sending proper queries. It can enable in QlikView direct discovery statement by setting the value True.
SET DirectEnableSubquery=‘True’
b. QlikView Direct Discovery Character Variables
- DirectFieldColumnDelimiter
This variable defines the character that will use as the field delimiter. For example,
SET DirectFieldColumnDelimiter=‘|’
- DirectStringQuoteChar
The character that will use to enclose strings in the queries define by this variable.
SET DirectStringQuoteChar=‘”’
- DirectIdentifierQuoteStyle
This variable is used to change the quoting style from ANSI (default) to a non-ANSI style. The only non-ANSI style in use is GoogleBQ.
SET DirectIdentifierQuoteStyle=‘GoogleBQ’
We recommend you to read – How to Apply QlikView Layout Themes?
- DirectIndentifierQuoteChar
Using this variable, you can define a character (single or in pair) which will control the quoting of identifiers in the query.
SET DirectIndentifierQuoteChar=’[]’
- DirectTableBoxListThreshold
Using this variable you can set the threshold limit for the number of rows in a table chart created using direct discovery in QlikView. This threshold is set to 1000 by default. You can increase or decrease it accordingly.
SET DirectTableBoxListThreshold=6000
c. QlikView Direct Discovery Number Interpretation Variables
- DirectMoneyDecimalSep
This defines the decimal money separator.
Set DirectMoneyDecimalSep=’.’;
- DirectMoneyFormat
Sets the currency format.
Set DirectMoneyFormat=’#.0000’;
- DirectTimeFormat
Sets the time format and replaced that defined by the SQL statement.
Set DirectTimeFormat=’hh:mm:ss’;
- DirectDateFormat
Sets and replaced the SQL statement for date format.
Set DirectDateFormat=’DD/MM/YYYY’;
- DirectTimeStampFormat
This variable is used to define the date and time stamp and replaces the SQL one.
Set DirectTimeStampFormat=’D/M/YY hh:mm:ss[.fff];
d. Teradata Banding Query Variables
The Teradata banding query variables are used by the enterprises to connect to the Teradata databases. There are two variables used for this purpose.
- SQLSessionPrefix
A string containing this variable is sent when a session or connection with Teradata database is initiated.
SET SQLSessionPrefix = ‘SET QUERY_BAND = ‘ & Chr(39) & ‘Who=’ & OSuser() & ‘;’ & Chr(39) & ‘ FOR SESSION;’;
- SQLQueryPrefix
This variable containing string is used before every single query.
SET SQLSessionPrefix = ‘SET QUERY_BAND = ‘ & Chr(39) & ‘Who=’ & OSuser() & ‘;’ & Chr(39) & ‘ FOR TRANSACTION;’;
Do you know How to Create & Import Bookmarks in QlikView?
QlikView Direct Query
Direct Query is the statement that defines and initiates direct discovery in QlikView. The QlikView direct query is written in the script editor along with the main document script where in-memory data is also loaded.
The external database tables can access through ODBC and OLE-DB connections using the direct query statement.
The syntax for the QlikView direct query statement is,
DIRECT QUERY DIMENSION fieldlist [MEASURE fieldlist] [DETAIL fieldlist] FROM tablelist [WHERE where_clause]
Where, the ‘fieldlist’ is the comma-separated fieldnames to consider as Dimension, Measure ad Detail.
The ‘tablelist’ is the name of the table in the database from which data is being extracted and the ‘where_clause’ is a type where statement defining a condition.
In this statement, the order of dimension, measure and query not define. But, every direct query statement must have a Dimension and From keywords (FROM coming after DIMENSION).
The image given below shows an example of the QlikView direct query statement.
ODBC CONNECT To AdWorks;
DIRECT QUERY
DIMENSION
CustomerID,
SalesPersonID,
SalesOrderID,
OrderDate,
NATIVE('Month ([OrderDate])') as OrderMonth,
NATIVE ('Year ([OrderDate])') as OrderYear
MEASURE
SubTotal,
TaxAmt,
TotalDue
DETAIL
DueDate,
ShipDate,
AccountNumber,
CreditCardApprovalCode,
rowguid,
ModifiedDate
FROM AdventureWorks.Sales.SalesOrderHeader;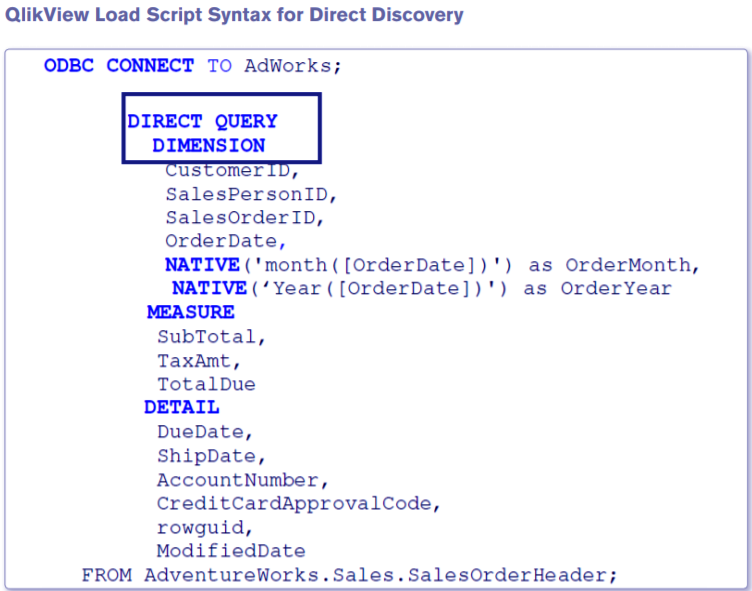
Qlikview Direct Discovery – QlikView Direct Query
How Qlikview Direct Discovery Works?
Now let us see how this direct discovery approach works in QlikView. As we know that through Direct Discovery data discovery and visual analysis using big data along with in-memory data has become easily possible.
Users are connecting to multiple platforms like Facebook, SAP, Teradata etc. using direct discovery. A significant advantage of this kind of QlikView direct discovery is gaining transparency through varied data silos.
In tradition design of BI tools, with QlikView in focus, the user can either connect to an in-memory data or to an external database but not both.
Through QlikView direct discovery doing both together is possible. Another advantage is that the software still follows its associative model and so, relationships between data values of in-memory and direct discovery can see giving opportunities of new and fresh insights into data.
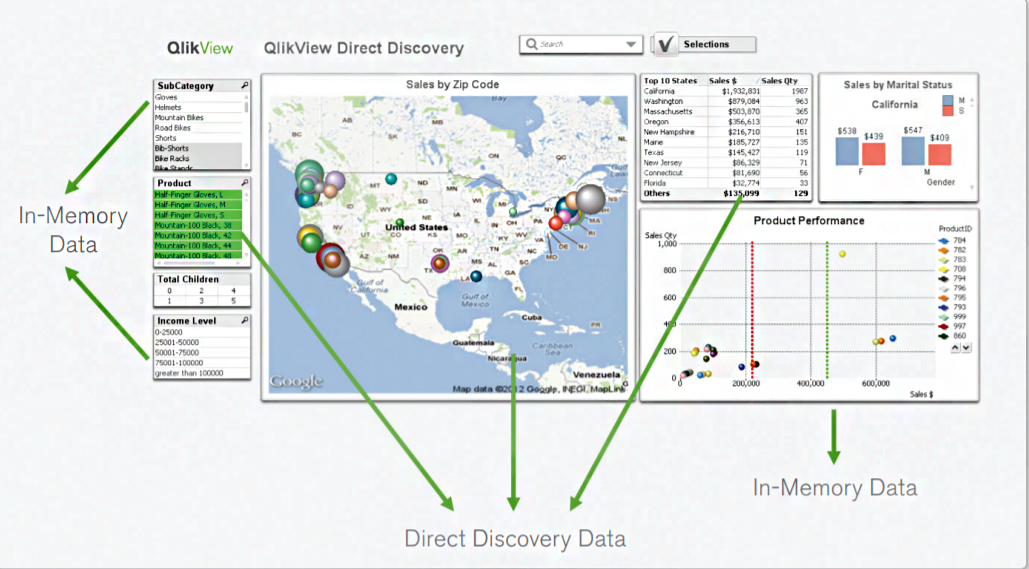
QlikView direct discovery Working
The QlikView direct discovery feature can invoke simply by adding the Direct Query statement calling data from the desired external data source through the script.
This statement decides what is to load into QlikView’s in-memory (Dimensions) and what should keep in the database at source destination (Measures).
However, the fields left at the database can call through queries.
When QlikView Direct Discovery structure gets established, both the data from in-memory and from direct discovery source can join and use in associative data analysis and visualization.
a. Data Source Supporting Direct Discovery
QlikView Direct Discovery used ODBC and OLE DB connections to connect with the external data sources and for that data sources must support the connections.
There are several data sources that support discovery connections. The list given below has the name of the data sources that support direct discovery.
MS SQL Server
Teradata
Oracle
SAP
Google Big Query
MySQL
Microsoft Access
DB2
PostgreSQL
Sybase
Have a look – QlikView Data Structure (Table & Fields)
QlikView Direct Discovery Data Model Vs In-Memory
Although, both in-memory and direct discovery data use along with each other in direct discovery method. Both have distinct data models that are fundamentally different from each other in some ways.
By combining, all the storage and speed limitations in storing and processing a large amount of data have been overcome.
Some differences between the two data models and their functioning are;
In the case of in-memory data loading, in a table field structure, all the corresponding field data values are loaded along with the associations the field shares.
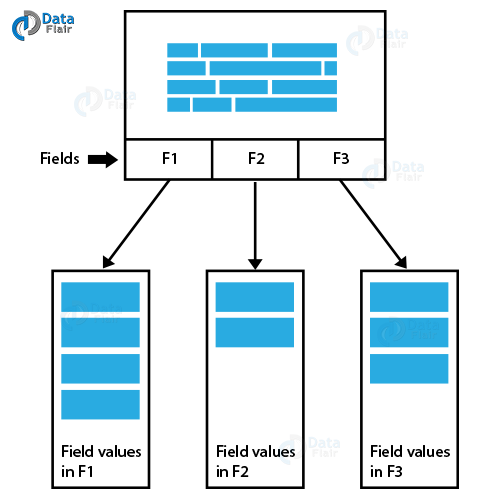
QlikView Direct Discovery Data Model Vs In-Memory
Also, if another table loads having some fields in common with the existing table will share the common values as shown in the image below.
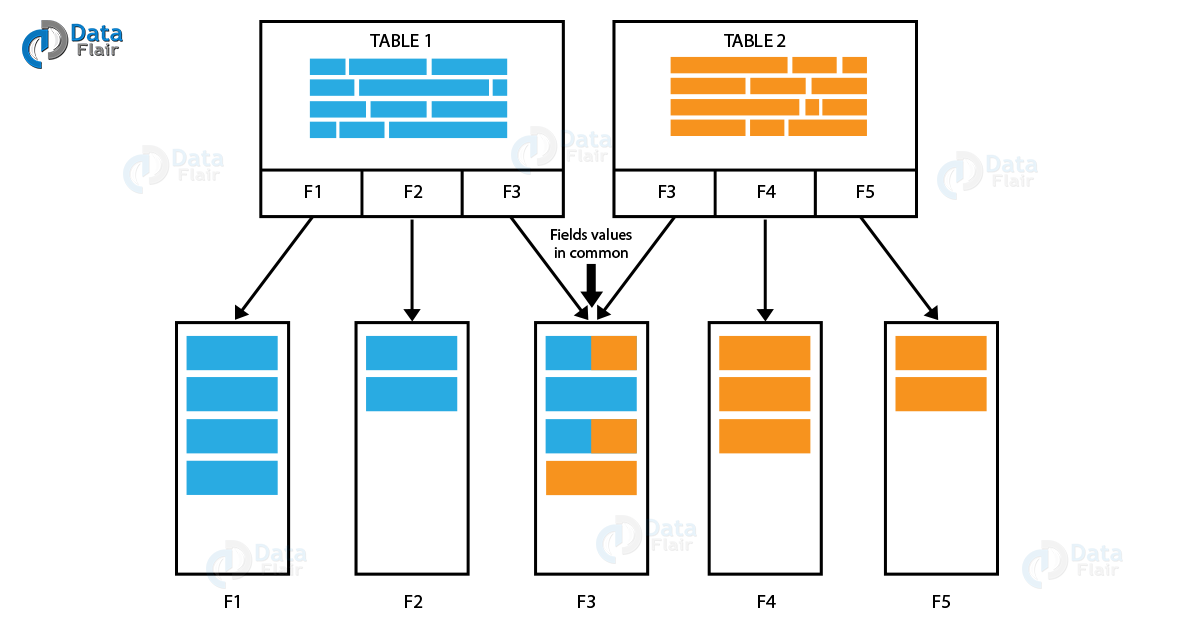
QlikView Direct Discovery Data Model Vs In-Memory
Now, in the case of a QlikView direct discovery data model. The fields of the table which are the Dimensions load using the QlikView Direct Query.
The associations and measures are left in the database at the source.
Whenever an aggregation or association is to perform on the external data, an SQL query launch which performs the calculations at the database source and returns only the result. The associations control by the WHERE clause in the direct query in QlikView.
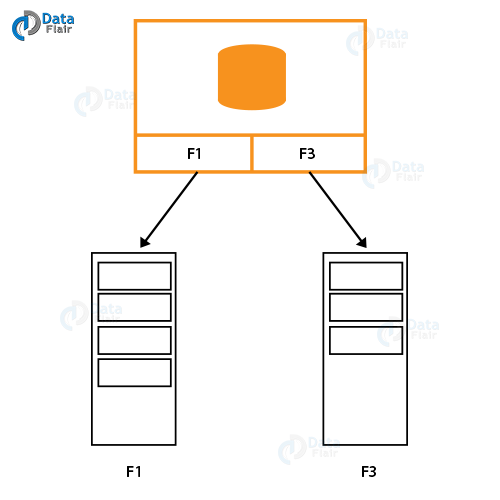
QlikView Direct Discovery Data Model Vs In-Memory
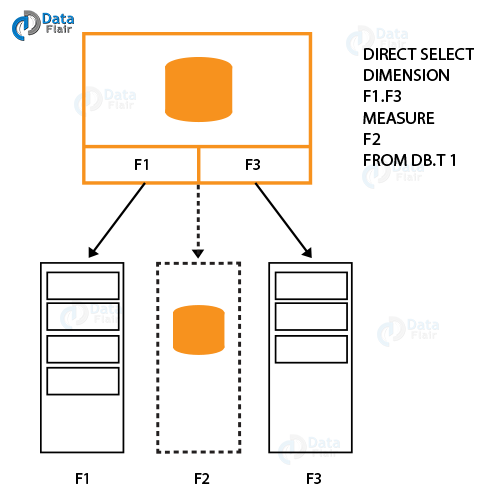
QlikView Direct Discovery Data Model Vs In-Memory
Advantages of QlikView Direct Discovery
QlikView Direct Discovery has many benefits associated with it. Some significant benefits are;
Associative and flexible data discovery for big data that enables a thorough analysis of such large chunks of data giving fresh and fruitful results.
A seamless combination of in-memory and direct discovery supporting data sources without any extra development efforts.
Massive data scalability as the size of data is no more a limitation.
Drilling down to details in the vast ocean of big data is much easier through data association in QlikView.
Using in-memory and direct discovery together makes data analysis much faster and efficient.
Diverse big data sources can use by the users to analyse data trends and patterns and share it with other users (team) as well.
Hidden patterns and associations can reveal in the big data by making selections in the in-memory data that shows the associations that selection has with the external data source data.
Disadvantages of QlikView Direct Discovery
However, following the rule of nature, this feature also has some cons or limitations as discussed below.
Limitations occur in some cases while supporting data types. For some data types, the source data format has to specifically mention using the ‘SET Direct…Format’ (syntax) statement. Like,
SET DirectDateFormat=’YYYY-MM-DD’;
SET DirectMoneyFormat (default ‘#.0000’)
There are a few security-related constrictions like if many users are using a QlikView application which supports direct discovery then authentication services are not supported.
The Set Analysis feature cannot use.
Calculated dimensions are not applicable.
QlikView Direct Discovery does not support Binary Load, Synthetic Key, Loop and Reduce.
QlikView Direct Discovery does not support several other QlikView features and functionalities as it uses only SQL syntax-specific queries.
So, this was all about QlikView Direct Discovery Tutorial. Hope you like our explanation.
Conclusion
Hence, we complete the tutorial on the topic of QlikView Direct Discovery.
This tutorial offers a comprehensive view on the topic as it starts from explaining what direct discovery is and moves to show how to implement and use it in QlikView. Still, had a confusion? Feel free to ask in the comment box.
Related Topic – QliKView Box Plot Wizard
Your opinion matters
Please write your valuable feedback about DataFlair on Google




