Relationship of Hadoop and QlikView – QlikView integration with Hadoop
Job-ready Online Courses: Click for Success - Start Now!
In the realm of data science, there are many evolving technologies to fetch, process, manage, analyze, visualize, store and administer the huge amounts of data present overall. Two such popular data-oriented tools in the market are Hadoop and QlikView.
Although, their roles are fundamentally different from one another. Users have been inquisitive about the relation between the two and their possibility of integration.
Well, we have made an attempt in putting your curiosities to rest and answer your questions in this article.
Here, we will talk about the relationship between Hadoop and QlikView and the flow of big data from Hadoop to QlikView. At last, we will learn QlikView integration with Hadoop.
Hadoop and QlikView
To begin with, let us discuss how Hadoop and QlikView are different from one another and what purpose do they serve.
i. What is Hadoop?
Hadoop is a collection of multiple software/hardware utilities which serve as a framework for big data distributed storage and processing. Hadoop Distributed File System (HDFS) is the distributed storage system of Hadoop and the processing of big data is conducted as per the MapReduce programming module.
ii. What is QlikView?
QlikView is a data analysis and data visualization platform. It is a data analysis and reporting tool which uses graphical aids like charts, graphs, and tables to represent data in different ways for the analysts to draw meaningful insights from.
Important business decisions are taken on the basis of insights drawn from the data reports.
iii. The Relationship of Hadoop and QlikView
Users have always been curious about the intersection or combination of these two tools as for Hadoop is efficient in fetching, storing and managing the massive amounts of data (big data) and QlikView is able to display the relations between data elements perform aggregations on it.
So, coming together of these two is for sure an interesting thing.
QlikView can work as a front-end interactive platform which shows the associations of facts or aggregation of data objects in the data silos distributed under the Hadoop Distributed File System (HDFS).
But a major concern here is that QlikView is an in-memory data analysis tool which means that it keeps the data in memory.
Whereas, Hadoop is a tool which works with big data and accommodating as much data as the size of big data (several terabytes) is a tough task.
Qlik has been trying to make it work by breaking the big data into smaller chunks so that it could be used by the QlikView Engine. This is done by following the MapReduce model of Hadoop.
So, to put it differently, business users use the big data from Hadoop systems to make it meaningful information in QlikView. That is, big data flows from the source to the analysis tool.
A Flow of Big data from Hadoop to QlikView
Let us understand the flow of data from the storage silos to the analytics tool and understand the role of Hadoop and QlikView in this process. Initially, semi or unstructured data (raw) from various origins such as machine data, transaction data, cloud data, etc. is taken.
Such data is defined as big data as it has a high volume, high velocity, and high variety.
Because of the magnitude of data, it is copied to the Hadoop ecosystem, where it is distributed according to the HDFS deployed on commodity hardware and processed by data manipulation and aggregation operations. This marks the first-level of raw data processing.
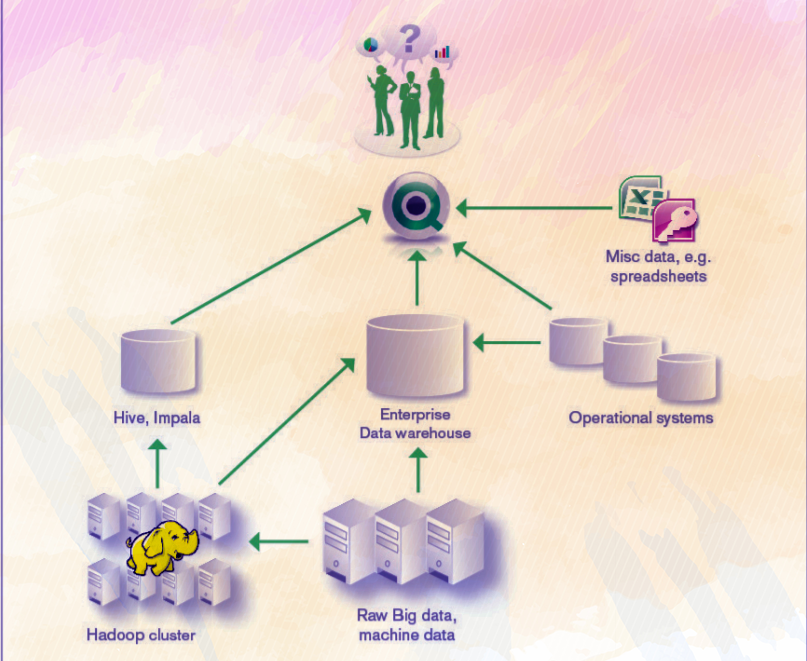
The flow of Big data from Hadoop to QlikView
In the Hadoop ecosystem lies Apache Hive and Cloudera Impala which serves as open source platforms for external tools like QlikView to access and process data from Hadoop.
From the Hadoop cluster, data goes to the Enterprise Data Warehouse (EDW) which acts as the central repository storing and processing structured data for analysis. EDWs complement the Hadoop system very well because they not only stores data but are is also capable of conducting robust ETL (Extract, Transform and Load) process upon the structured data.
It is convenient for the analytical tools to fetch and process structured hence, more meaningful data from the EDWs. EDWs can fetch data either from the data source (raw data) or from the Hadoop ecosystem.
Thus, the structured and organized data from EDWs or the data from supporting tools such Hive and Impala is consumed by the analytical tools such as QlikView, Qlik Sense etc. for respective purposes.
From these tools, users create well structured and informative data reports and dashboards.
QlikView integration with Hadoop
You can configure and integrate Hadoop with QlikView in two ways. Firstly, by loading data directly into a QlikView In-memory associative data store. Secondly by conducting direct data discovery on top of Hadoop.
In the first method, data is compressed and loaded into QlikView in-memory from Hadoop only at the time of requirement.
Another method is to build a hybrid QlikView solution which conducts direct data discovery on top of Hadoop. Which means that data resides in Hadoop and all the processing related queries are sent down to Hadoop from QlikView. To connect QlikView with Hadoop tools. Follow the procedure given below.
Step. 1
Download and install QlikView in your desktop.
Step. 2
Download a JDBC connector. Through the JDBC connector, you can connect with Hadoop tools such as, Hadoop HDFS, Hive, HiveServer2 (Cloudera, MapR, Amazon, EMR), Cloudera Impala, Apache HBase and Apache Cassandra.
Step. 3
Install the JDBC set up file on your device (extract the zip file).
Step. 4
Now, go to File > New File > Edit Script > Data and select JDBCConnector.dll option from the drop-down menu.
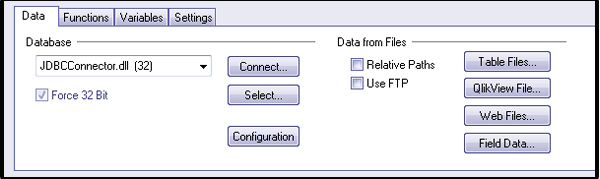
Step. 4 QlikView integration with Hadoop
Step. 5
We will connect Cloudera Hadoop Hive from this JDBC connector. You can download the latest version of Cloudera Hive JDBC drivers.
Step. 6
If the files are zipped, then extract them under the name Cloudera_HiveJDBC_2.5.4.1006.zip. Also, keep a few useful jar files as mentioned below.
- HiveJDBC4.jar
- hive_metastore.jar
- hive_service.jar
- libfb303-0.9.0.jar
- libthrift-0.9.0.jar
- log4j-1.2.14.jar
- ql.jar
- slf4j-api-1.5.8.jar
- slf4j-log4j12-1.5.8.jar
- TCLIServiceClient.jar
Step. 7
Follow the given path and add the mentioned jar files in into the JDBC library. Path: Edit Script > Data > (JDBCConnector) Configuration > JDBC drivers > Add Library > Browse the jar files and add them to library.
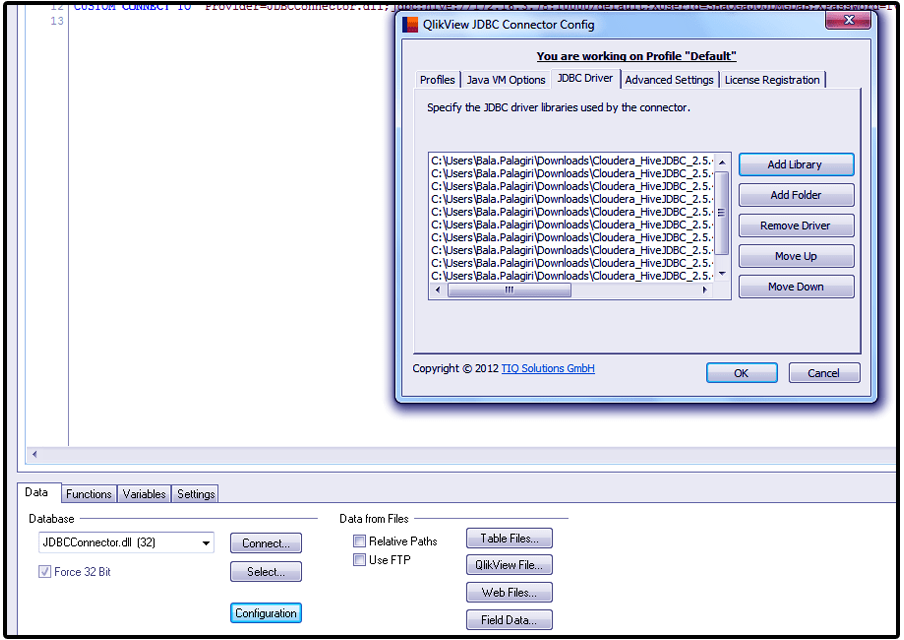
Step. 7 QlikView integration with Hadoop
Step. 8
Next, we give the name to the JDBC driver class according to the Hive server you are using. If you are using Cloudera Hive Server 1 or Hive Server 2 then driver class name should be one of the below two class names given. It is possible that you find org.apache.hive.jdbc.HiveDriver as the default class name. You must change it.
- com.cloudera.hive.jdbc4.HS1Driver
- com.cloudera.hive.jdbc4.HS2Driver
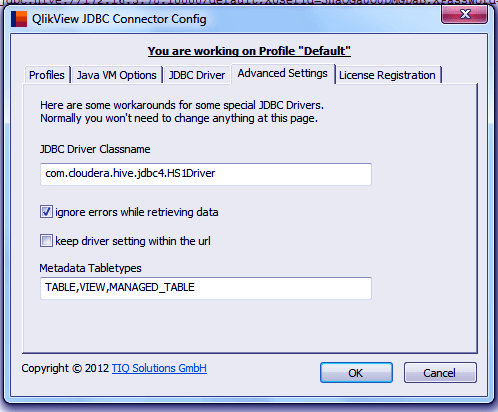
Step.8 QlikView integration with Hadoop
Step. 9
Use the commands $ hive — service metastore & and $ hive—service hiveserver & to initiate the services like Hive metastore and hive server.
Step. 10
Provide the connection string details like URL, username, and password to connect to the Hadoop database.
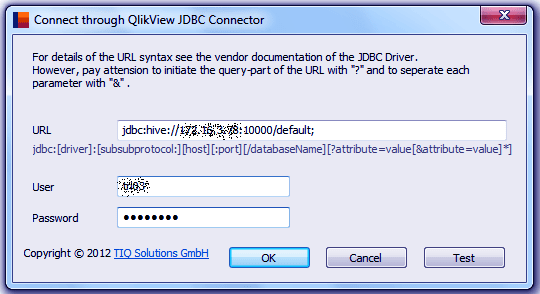
Step. 10 QlikView integration with Hadoop
Step. 11
Select tables and columns from the selected Hadoop database.
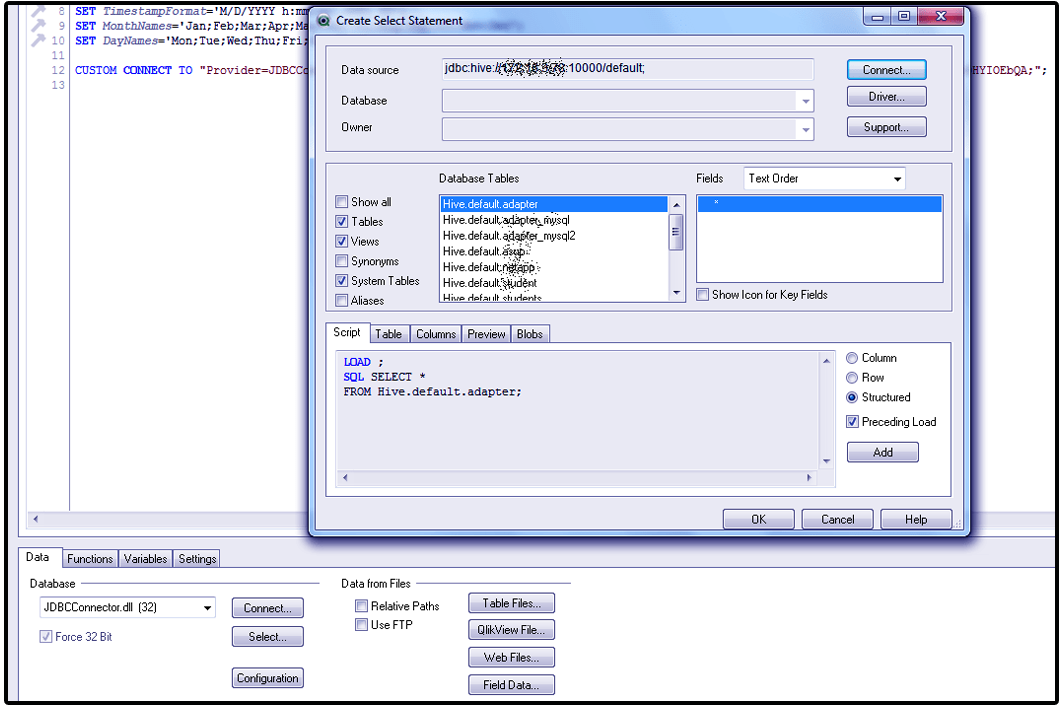
Step. 11a QlikView integration with Hadoop
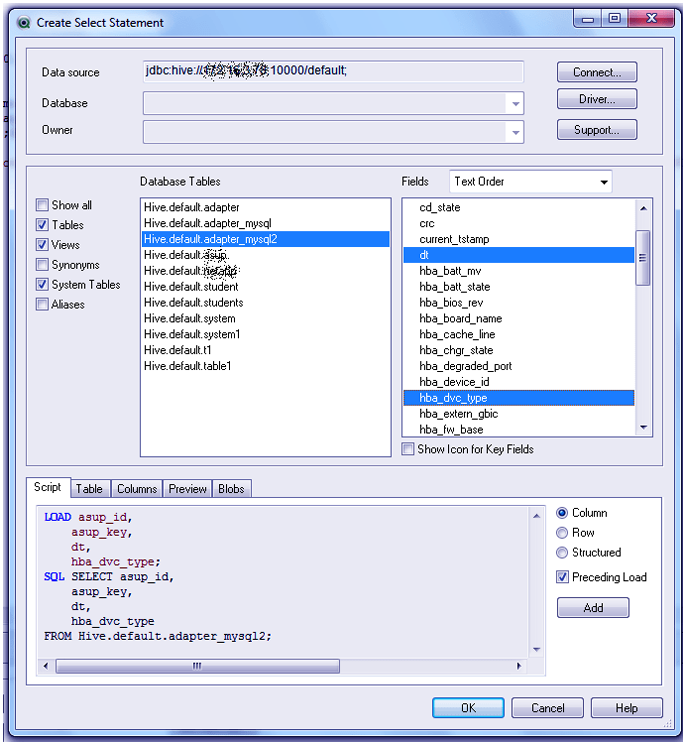
Step. 11b QlikView integration with Hadoop
Step. 12
Click on OK and execute the QlikView script.
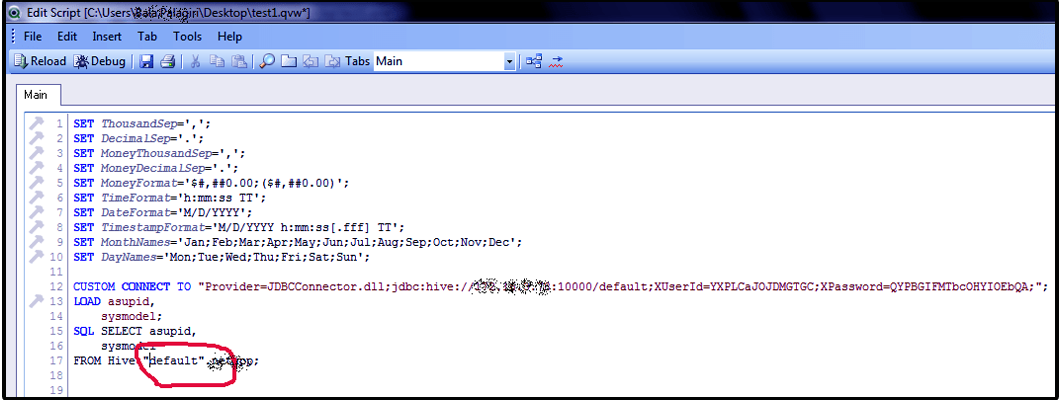
Step. 12 QlikView integration with Hadoop
Step. 13
Once the connection is established. You can add all the files into QlikView by right-clicking on the sheet and clicking on Select fields. You can use the loaded data fields in the visualizations in QlikView.
Step. 13a QlikView integration with Hadoop
Step. 13b QlikView integration with Hadoop
Conclusion
Hence, you can connect to similar Hadoop tools by downloading their corresponding drives and use their data into QlikView. We hope this article helped you in the right ways and answered your queries regarding the relation of QlikView and Hadoop. If you have any other query, feel free to share with us.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





It is god article. Can you explain how we can do join using in Hadoop since the concept of primary key does not exist.