4 Machine Learning Techniques with Python
Machine Learning courses with 100+ Real-time projects Start Now!!
Master Python with 70+ Hands-on Projects and Get Job-ready - Learn Python
In our last session, we discussed Train and Test Set in Python ML. Here, In this Machine Learning Techniques tutorial, we will see 4 major Machine Learning Techniques with Python: Regression, Classification, Clustering, and Anomaly Detection.
Familiarity with these methods is therefore a prerequisite when it comes to training viable machine learning algorithms. They all relate to separate types of scenarios and input data arrangements. For instance, regression is very relevant when input and output data are continuous variables and when constructing predictive models for future values.
On the other hand, classification is beneficial with regard to categorizing data into categories that are already determined, which is important when it comes to issues like image recognition or the filtering of emails.
So, let’s look at Python Machine Learning Techniques.

4 Machine Learning Techniques with Python
Machine Learning Techniques vs Algorithms
While this tutorial is dedicated to Machine Learning techniques with Python, we will move over to algorithms pretty soon. But before we can begin focusing on techniques and algorithms, let’s find out if they’re the same thing.
A technique is a way of solving a problem. This is quite generic as a term. But when we say we have an algorithm, we mean we have an input, and we desire a certain output from it. We have clearly defined what steps to follow to get there. We will go the lengths to say an algorithm may make use of multiple techniques to get to the output.
Do you know the Applications of Machine Learning
Now that we have distinguished between the two, let’s find out more about Machine Learning techniques.
Machine Learning Techniques with Python
Python Machine Learning Techniques are 4 types, let’s discuss them:
a. Machine Learning Regression
The dictionary will tell you that to regress is to return to a former state- one that is often less developed. In books of statistics, you will find regression to be a measure of how one variable’s mean and corresponding values of other variables relate to each other. But let’s talk about it, so you will see it.
Also, Read Python Linear Regression & Chi-Square Test

Python Machine Learning Techniques – Machine Learning Regression
i. Regressing to the Mean
Francis Galton, Charles Darwin’s half-cousin, observed the sizes of sweet peas over generations. What he concluded was that letting nature do its job will result in a range of sizes. But if we selectively breed sweet peas for size, it makes for larger ones. With nature at the steering wheel, even bigger peas begin to produce smaller offspring with time. We have a certain size for peas that varies, but we can map these values to a specific line or curve.
ii. Another Example- Monkeys and Stocks
In 1973, Burton Malkiel, a Princeton University Professor put a claim in his book. A Random Walk Down Wall Street, which was a bestseller, insisted that a blindfolded monkey could do an equally good job as experts at selecting a portfolio by throwing darts at a newspaper’s financial pages. In such stock-picking competitions, monkeys have beaten pros. But this was for once or twice. With enough events, the monkeys’ performance declines; it regresses to the mean.

Python Machine Learning Techniques – Monkeys and Stocks
iii. What is Machine Learning Regression?
In this plot, the line best fits all the data marked by the points. Using this line, we can predict what values we will find for x=70 (with a degree of uncertainty).
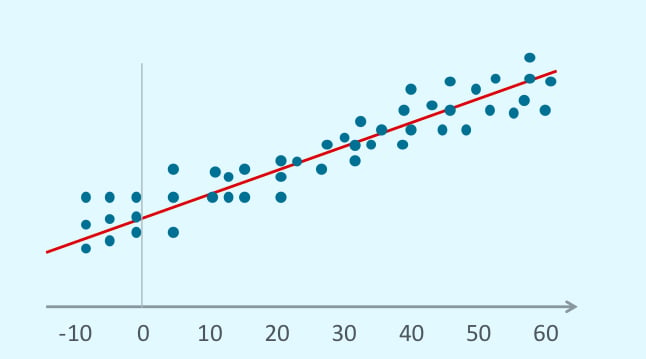
Machine Learning Techniques with Python – What is Machine Learning Regression
As a Machine Learning technique, regression finds its foundation in supervised learning. We use it to predict a continuous and numerical target and begin by working on the data set values we already know. It compares known and predicted values and labels the difference between the expected and predicted values as the error/residual.
iv. Types of Regression in Machine Learning
We generally observe two kinds of regression-
Linear Regression- When we can denote the relationship between a target and a predictor in a straight line, we use linear regression-
y=P1x+P2+e
Non-Linear Regression- When we observe a non-linear relationship between a target and a predictor, we cannot denote it as a straight line.
b. Machine Learning Classification
i. What is Machine Learning Classification?
Classification is a data mining technique that lets us predict group membership for data instances. This uses labelled data in advance and falls under supervised learning. This means we train data and expect to predict its future. By ‘prediction’, we mean we classify data into the classes it can belong to. We have two kinds of attributes available-
- Output Attribute- Aka Dependent attribute.
- Input Attribute- Aka Independent attribute.
ii. Methods of Classification
- Decision Tree Induction- We build a decision tree from the class-labelled tuples. This has internal nodes, branches, and leaf nodes. The internal nodes denote the test on an attribute, the branches- the test outcome, and the leaf nodes- the class label. The two steps involved are learning and testing, and these are fast.
- Rule-based Classification- This classification is based on a set of IF-THEN rules. A rule is denoted as-
IF condition THEN conclusion
- Classification by Backpropagation- Neural network learning, often called connectionist learning, builds connections. Backpropagation is a neural-network learning algorithm, one of the most popular ones. It iteratively processes data and compares the target value with the results to learn.
- Lazy Learners- In a lazy learner approach, the machine stores the training tuple and waits for a test tuple. This supports incremental learning. This contrasts with the early learner approach.
iii. ML Classification Example
Let’s take an example. Consider we’re here to teach you about different kinds of codes. We present to you ITF Barcodes, Code 93 Barcodes, QR codes, Aztecs, and data matrices, among others.
Once through most of the examples, it is now your turn to identify the kind of code it is when we show you one. This is supervised learning, and we use parts of the examples of both training and testing.
Notice how some stars of each type end up on the other side of the curve.
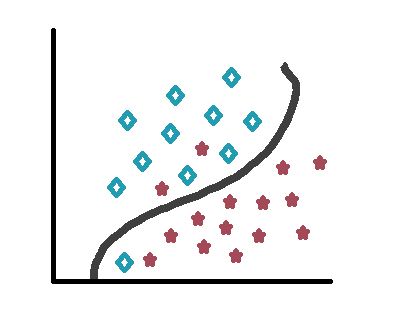
Machine Learning Techniques with Python – ML Classification Example
c. Clustering
Clustering is an unsupervised classification. This is an exploratory data analysis with no labelled data available. With clustering, we separate unlabeled data into finite and discrete sets of data structures that are natural and hidden. We observe two kinds of clustering-
- Hard Clustering- One object belongs to a single cluster.
- Soft Clustering- One object may belong to multiple clusters.
In clustering, we first select features, then design the clustering algorithm, and then validate the clusters. Finally, we interpret the results.
In clustering algorithms, data points are grouped based on distances, which are measures used by most algorithms. Clustering approaches include k-means, hierarchical clustering, and density-based clustering such as DBSCAN. All the methods used in data analysis have their advantages, and each is applicable in different situations depending on the data collected and the analysis required.
For instance, k-means clustering can be useful while clustering a large dataset, but it has a constraint that you need to specify the number of clusters in advance, while, on the other hand, there is hierarchical clustering does not require this specification; it rather gives a dendrogram that shows the relationship of clusters.
a. Example
Recall the example in section b.iii. You could group these codes. QR code, Aztec, and Data Matrix would be in a group; we could call this 2D Codes. ITF Barcodes and Code 39 Barcodes would group into a ‘1D Codes’ category. This is what a cluster looks like-
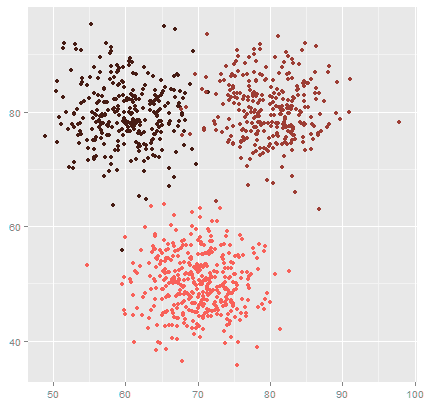
Machine Learning Techniques with Python – Clustering
b. Anomaly Detection
An anomaly is something that deviates from its expected course. With machine learning, sometimes, we may want to spot an outlier. One such example would be to detect a dentist bill 85 fillings per hour. This amounts to 42 seconds per patient. Another would be to find a particular dentist’s bill only on Thursdays. Such situations raise suspicion, and anomaly detection is a great way to highlight these anomalies since this isn’t something we’re looking for specifically.
Benefits of using Anomaly Detection:
- It helps in detecting and preventing problems at an early stage
- It has improved operational efficiencies.
- Advanced security
- Data backups and easier decision-making
- It promotes seamless growth
So, this was all about Machine Learning Techniques with Python. Hope you like our explanation.
Conclusion
Hence, in this tutorial, we learned about four techniques of machine learning with Python: Regression, Classification, Clustering, and Anomaly Detection. Furthermore, if you have any queries, feel free to ask in the comment box.
Related Topic- Data Preprocessing, Analysis & Visualization in Python ML
For reference
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Thanks for this post!