Machine Learning Tutorial – All the Essential Concepts in Single Tutorial
Machine Learning courses with 100+ Real-time projects Start Now!!
This being a beginner’s tutorial of Machine Learning, I will try to make it as simple as it could be.
Have you ever went for grocery shopping? What do you do before going to the market?
I always prepare a list of ingredients beforehand. Also, I make the decision according to the previous purchasing experience. Then, I go and purchase the items. But, with the rising inflation, it’s not too easy to work in the budget. I have observed that my budget gets deviated a lot of times.
This happens because the shopkeeper changes the quantity and price of a product very often. Due to such factors, I have to modify my shopping list. It takes a lot of effort, research and time to update the list for every change.
This is where Machine Learning can come to your rescue. Still confused?
Don’t worry! Read this DataFlair’s latest Machine learning tutorial to get deep insight and understand why machine learning is trending. So let’s start the Machine Learning tutorial.
What is Machine Learning?
Machine Learning is the most popular technique of predicting the future or classifying information to help people in making necessary decisions.
Machine Learning algorithms are trained over instances or examples through which they learn from past experiences and also analyze the historical data.
Therefore, as it trains over the examples, again and again, it is able to identify patterns in order to make predictions about the future.
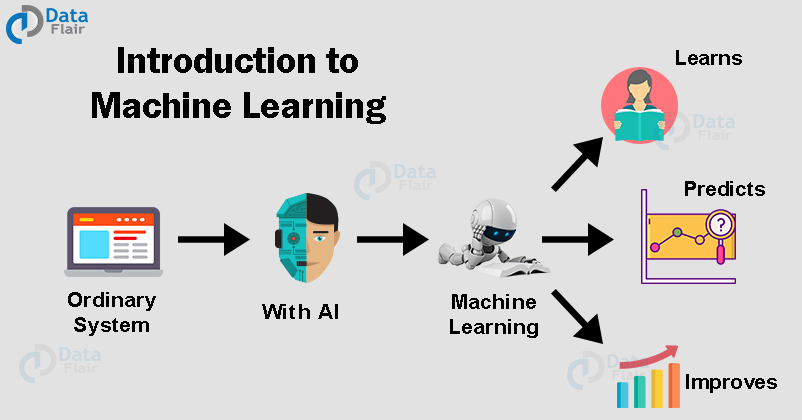
Machine Learning Tutorial: Introduction to Machine Learning
After knowing what machine learning is, let’s take a quick introduction to machine learning and start the tutorial.
With the help of Machine Learning, we can develop intelligent systems that are capable of taking decisions on an autonomous basis. These algorithms learn from the past instances of data through statistical analysis and pattern matching. Then, based on the learned data, it provides us with the predicted results.
Data is the core backbone of machine learning algorithms. With the help of the historical data, we are able to create more data by training these machine learning algorithms.
For example, Generative Adversarial Networks are an advanced concept of Machine Learning that learns from the historical images through which they are capable of generating more images. This is also applied towards speech and text synthesis.
Therefore, Machine Learning has opened up a vast potential for data science applications. Machine Learning combines computer science, mathematics, and statistics. Statistics is essential for drawing inferences from the data.
Mathematics is useful for developing machine learning models and finally, computer science is used for implementing algorithms.
However, simply building models is not enough. You must also optimize and tune the model appropriately so that it provides you with accurate results. Optimization techniques involve tuning the hyperparameters to reach an optimum result.
Machine Learning is used in every domain. It is being used to impart intelligence to static systems. With the knowledge acquired from the data, it is used to build intelligent products.
The use of machine learning is well-supported by innovations such as cloud computing that offer facilities for efficient processing of large amounts of data. This has made it possible for businesses of any size to adopt machine learning without digging deep into their pockets to acquire hardware.
Why Machine Learning?
The world today is evolving and so are the needs and requirements of people. Furthermore, we are witnessing a fourth industrial revolution of data.
In order to derive meaningful insights from this data and learn from the way in which people and the system interface with the data, we need computational algorithms that can churn the data and provide us with results that would benefit us in various ways.
Machine Learning has revolutionized industries like medicine, healthcare, manufacturing, banking, and several other industries. Therefore, Machine Learning has become an essential part of modern industry.
Data is powerful and in order to harness the power of this data, added by the massive increase in computation power, Machine Learning has added another dimension to the way we perceive information.
Machine Learning is being utilized everywhere.
The electronic devices you use, the applications that are part of your everyday life are powered by powerful machine learning algorithms.
Machine Learning example – Google is able to provide you with appropriate search results based on browsing habits.
Similarly, Netflix is capable of recommending the films or shows that you would want to watch based on the machine learning algorithms that perform predictions based on your watch history.
Furthermore, machine learning has facilitated the automation of redundant tasks that have taken away the need for manual labor. All of this is possible due to the massive amount of data that you generate on a daily basis.
Machine Learning facilitates several methodologies to make sense of this data and provide you with steadfast and accurate results.
How does Machine Learning Work?
With an exponential increase in data, there is a need for having a system that can handle this massive load of data.
Machine Learning models like Deep Learning allow the vast majority of data to be handled with an accurate generation of predictions.
Machine Learning has revolutionized the way we perceive information and the various insights we can gain out of it.
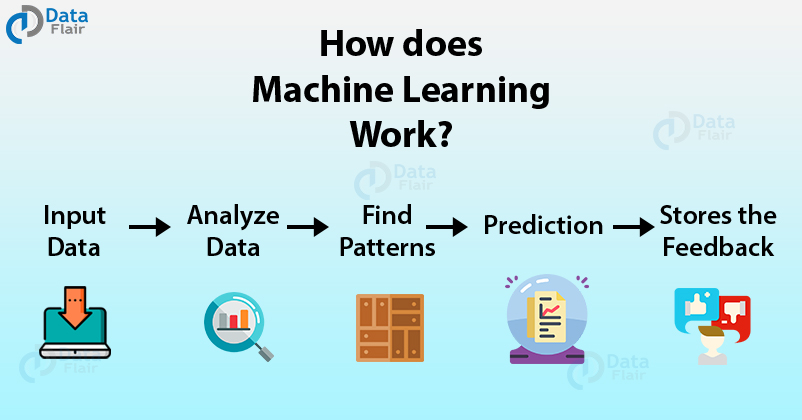
These machine learning algorithms use the patterns contained in the training data to perform classification and future predictions. Whenever any new input is introduced to the ML model, it applies its learned patterns over the new data to make future predictions. Based on the final accuracy, one can optimize their models using various standardized approaches.
In this way, Machine Learning model learns to adapt to new examples and produce better results. Next in Machine Learning tutorial is its types. Have a look –
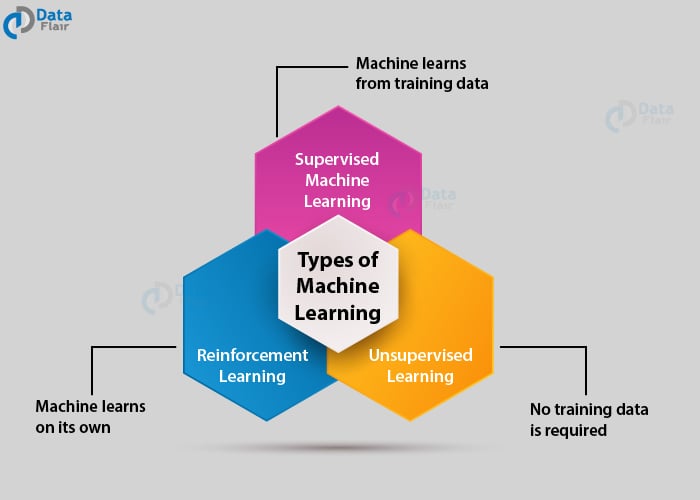
Types of Machine Learning
Machine Learning Algorithms can be classified into 3 types as follows –
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised learning
Supervised learning is that the machine learning task of learning a function that maps an input to an output supported example input-output pairs.
In Supervised Learning, the dataset on which we train our model is labeled. There is a clear and distinct mapping of input and output. Based on the example inputs, the model is able to get trained in the instances.
An example of supervised learning is spam filtering.
Based on the labeled data, the model is able to determine if the data is spam or ham. This is an easier form of training.
Spam filtering is an example of this type of machine learning algorithm.
Unsupervised Learning
Unsupervised Learning may be a machine learning technique during which the users don’t got to supervise the model. Instead, it allows the model to figure on its own to get patterns and knowledge that was previously undetected. It mainly deals with the unlabeled data.
In Unsupervised Learning, there is no labeled data. The algorithm identifies the patterns within the dataset and learns them. The algorithm groups the data into various clusters based on their density. Using it, one can perform visualization on high dimensional data.
One example of this type of Machine learning algorithm is the Principle Component Analysis.
Furthermore, K-Means Clustering is another type of Unsupervised Learning where the data is clustered in groups of a similar order. The learning process in Unsupervised Learning is solely on the basis of finding patterns in the data.
After learning the patterns, the model then makes conclusions.
Reinforcement Learning
Reinforcement learning is one among three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
It is an emerging and most popular type of Machine Learning Algorithm. It is used in various autonomous systems like cars and industrial robotics. The aim of this algorithm is to reach a goal in a dynamic environment. It can reach this goal based on several rewards that are provided to it by the system.
This is most heavily used in programming robots to perform autonomous actions. It is also used in making intelligent self-driving cars.
Let us consider the case of robotic navigation.
Furthermore, the efficiency can be improved with further experimentation with the agent in its environment. This the main principle behind reinforcement learning.
There are similar sequences of action in a reinforcement learning model.
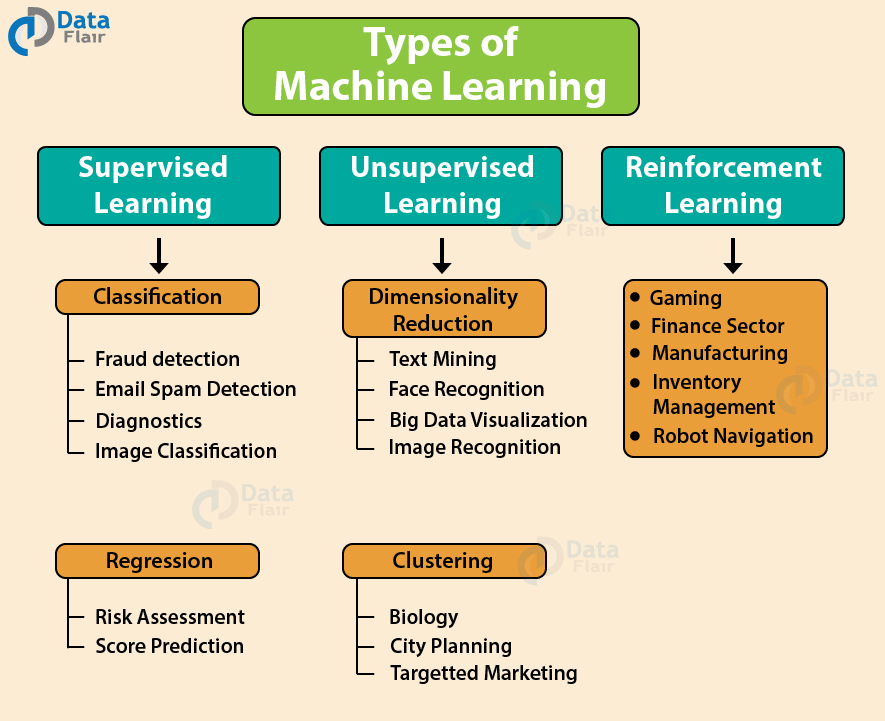
Machine Learning Algorithms
Let us see some most common machine learning approaches:
1. Regression
Regression models are used extensively to predict values based on the variables that are dependent on several factors.
The most common example of regression is Linear Regression where there is a linear relationship or correlation between the predictor variable and the response variable.
There are also other types of regression such as ARIMA regression that makes use an auto-correlation regression model to forecast continuous values provided by the time-series data.
They are used in forecasting the stock prices and other values that are based on time.
2. Decision Tree Learning
Decision Trees are a supervised type of machine learning algorithms. These trees are mainly used for predictive modeling. We create a decision tree that is able to take decisions based on user input.
Decision Trees can be used for both regressions as well as classification. These trees are used to provide graphical outputs to the user based on several independent variables.
3. Support Vector Machines
Support Vector Machines or SVMs are machine learning algorithms that are used to classify data into two categories or classes.
It is a type of supervised learning algorithms that makes use of several types of kernels to classify the data. Based on the prediction performed, it can categorize whether it falls into one class or any other class.
With the help of SVMs, one can perform both linear as well as non-linear classification. An SVM classifier divides the data into two classes using a hyperplane.
4. Association Rule Learning
Association rule learning is a type of learning technique that checks the dependency of one data item on another and maps accordingly to make it more profitable.
This is used for finding relationships between several variables that are present in the database. It is a type of data mining technique through which you can discover association between several items. It applied in sale industries mostly to predict if the customer will buy item Y if he has purchased the item X.
5. Artificial Neural Networks (ANN)
An Artificial Neural Network is an advanced form of machine learning technique. These neural networks are modeled after the human nervous system and are therefore called neural networks.
There is a connection of several neurons which compute the information. These neurons capture the statistical structure and are therefore able to create a joint probability distribution over the input variables. These neural networks are apt at finding patterns over large datasets.
Neural Networks can perform classification as well as regression tasks with high accuracy.
Furthermore, they eliminate the requirement for doing heavy statistical tasks in pre-processing as they are quite adequate in realizing patterns on their own.
6. Inductive Logic Programming
In this, logic programming forms the core part to produce a rule-like learning model.
Inductive Logic Programming or ILP presents the input information, hypothesis as well as the background contextual knowledge in the form of several rules that have to be followed with logic.
It makes use of functional programs to carry out inductive programming to process hypothesis in part rules.
Training models are quite often used for developing this model which is then used to forge relationships between several variables.
7. Reinforcement Learning
The aim of Reinforcement Learning is to direct the agent towards maximizing rewards and reach its goal. This takes place in a dynamic environment where the agent has to chart its way to the goal through a series of trials and errors. Each time it takes a correct route, its profit is maximized and when it encounters a wrong approach, its profit is minimized.
Reinforcement Learning is widely used in self-driving cars and autonomous robotics that require self-decision making capability.
These are experimental in nature and through a series of trials are able to reach their goals with maximum accuracy (or rewards).
8. Clustering
In clustering, the observations are divided into groups or clusters. These clusters are formed based on similar data and have similar criteria. These criteria can be density or similar structure of the data.
There are several clustering techniques that make use of different criteria to cluster the data.
For instance, the distance between the data, the density of the data and graph connectivity are some of the criteria that define techniques for clustering in machine learning.
Since there are no labeled data or input-output mapping, this type of technique is an unsupervised machine learning procedure.
9. Similarity and Metric Learning
Similarity determination is one of the key functions of machine learning. In this form of learning, the ML model is provided a mix of similar as well as dissimilar data objects.
The machine learning model learns to map similar objects together and learns a similarity function that allows it to group similar objects together in the future.
10. Bayesian Networks
A Bayesian Network is an acyclic directed graphical model. This model is also called DAG which represents the probability of several independent conditioned variables.
One can illustrate the relationship between disease and symptoms. It can be used to compute the probabilities of various diseases. They can be used to find the diagnosis of several diseases through a calculated approach of listing probabilities of various factors that could have contributed towards it.
More advanced forms of Bayesian Networks are Deep Bayesian Networks.
The basic principle behind the Bayesian Network is the Bayes theorem which is the most important part of the probability theory. With the help of Bayes Theorem, we determine the conditional probability of an event. This conditional probability is of a known event.
The conditional probability itself is the hypothesis. And, we calculate this probability based on the previous evidence.
P (A/B) = P (B/A)*P (A)/P (B)
Using a well-defined network of a connected graph, a user can make a DAG to model conditional dependencies
11. Representation Learning
In order to represent the data in a more structured format, we make use of representation learning. This formats the data efficiently so that the model can train better to provide accurate results.
The representation of data is one of the key factors that can affect the performance of the machine learning method. This allows the algorithm to learn better from the data.
Using representation learning, algorithms are able to preserve the input data and essential information. Therefore, a model is able to capture most of the information during pre-processing.
Furthermore, the inputs present in pre-processing are able to gather data generating a defined distribution.
12. Sparse Dictionary Learning
In the method of Sparse Dictionary, a linear combination of basis functions as well as sparse coefficients are assumed.
The elements of a sparse dictionary are called atoms. These atoms altogether compose a dictionary. It is an extension of representation learning. It is used most widely in compressed sensing and signal recovery.
In this method, we represent a datum as a linear combination of basis functions and then assume the coefficients to be sparse.
So, this was all in the latest Machine learning tutorial for beginners. Many of you might find the umbrella terms Machine learning, Deep learning, and AI confusing.
So, here is some additional help; below is the difference between machine learning, deep learning, and AI in simple terms.
Machine Learning vs Deep Learning vs AI
Machine Learning
It is a method of knowledge analysis that automates analytical model building. It’s a branch of AI supported the thought that systems can learn from data, identify patterns and make decisions with minimal human intervention.
Machine Learning is a part of Artificial Intelligence that involves implementing algorithms that are able to learn from the data or previous instances and are able to perform tasks without explicit instructions.
The procedure for learning from the data involves statistical recognition of patterns and fitting the model so as to evaluate the data more accurately and provide us with precise results.
Deep Learning
Deep learning is a component of a broader family of machine learning methods supported artificial neural networks with representation learning.
Learning is often supervised, semi-supervised or unsupervised. Deep Learning is a part of Machine Learning that involves the usage of artificial neural networks.
Deep Learning machine learning algorithms are the most popular choice in many industries due to the ability of neural networks to learn from large data more accurately and provide steadfast results to the user.
Artificial Intelligence
AI is the greater pool that contains an amalgamation of all the above-discussed technologies. Artificial Intelligence is still under research and involves imparting sentient intelligence to the machines.
However, Artificial General Intelligence is still far fetched and will require years of research before we can have even a basic version of it.
Machine Learning Applications
Machine Learning is useful in many areas. Some prominent applications include:
1. Healthcare: Artificial intelligence used to anticipate the epidemics, identify endemics and develop individual care regimen. Diagnosis models help in the early detection of diseases like cancer; this has a positive impact on the health of the patient and the health care system.
2. Finance: In the field of finance, the application of machine learning includes credit rating, fraud, and algorithmic trading. Applying machine learning on transactional data, one is able to detect the various anomalous activities and therefore, prevent unauthorized transactions.
3. Natural Language Processing (NLP): Real-life applications of NLP are in areas such as language translation, opinion mining, and chatbots. With ML algorithms, text based data can be processed for its context, emotions and real time responses.
4. Cybersecurity: Applications of machine learning in intrusion detection include threat identification, intrusion prevention, and anomaly detection. Using machine learning algorithms, security researchers monitor network traffic and learn from it to counter cyber threats.
5. Transportation: Machine Learning finds many applications in transportation field like in autonomous vehicles
Summary
Machine Learning is a branch of computer science where machines are trained to learn from data and improve over time without being clearly programmed. Instead of writing code for every task, we give data to the machine and it finds patterns, makes decisions, and gives results. This is helpful in tasks like predicting prices, recognizing faces, translating languages, and more. With the right data, even a basic model can start learning and give smart outputs.
Hope you enjoyed the article.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





DataFlair team your article is a great help for beginners. You have briefly introduced the Machine learning your team has covered all the important point very sequential manner. Thank you for this great blog.
Great post indeed.
Information in the article are excellent for beginners.
Most of the term are simple but difficult to grasp maybe due to complexity of Machine Learning Algorithms.
I have started but afraid, about how I will be able to remember all these concepts.
Don’t be afraid, we have covered all the major concepts of machine learning in easy to understand language. Just start completing the machine learning tutorials sequentially from the sidebar. And, if you face any difficulty, you can ask us freely.
It has some very basic info giving distorted viewing concepts, it could have been much better
it is so useful
please send me all the tutorial to machine learning with science
Hello,
We are happy to help you. Here DataFlair is providing you with 90+ Free Machine Learning tutorials. Please refer them to know more about this technology.
Will, there be an emphasis on the hands-on project here?
It is very useful for beginners like me.
Thanks !
Thanks.
the article that you make is very helpful for beginners like me. thank you
I feel like I’m reaching my destination faster than I expected, thank you!!
This is usual for any subject one is beginning to learn but with determination and consistency after a while you’ll get well acquainted and even become a master.
Hello, Thanks for sharing the helpful article with us, and you sharing such great information about Machine Learning It’s easy to understand the content. thanks for sharing with us.
Hello DataFlair World! This was a great read. Like many, I am overawed by the sheer bulk of it and I’ve to admit this isn’t my first encounter with machine learning/AI concepts yet it still sounds and feels like pure Greek to me:-). All the more reason for me to find that quintessential reason to self-motivate my brain into a master of this all too important technology! Thanks a million, times!
The article is outstanding…..
Tqqqqq