Train and Test Set in Python Machine Learning – How to Split
Master Python with 70+ Hands-on Projects and Get Job-ready - Learn Python
In our last session, we discussed Data Preprocessing, Analysis & Visualization in Python ML. Now, in this tutorial, we will learn how to split a CSV file into Train and Test Data in Python Machine Learning. Moreover, we will learn the prerequisites and process for splitting a dataset into training data and a test set in Python ML.
We’ve cleaned our data and seen the charts; now it’s time to focus on the ultimate stress test. Splitting your dataset is like an insurance policy for your code; it’s the only way you can prove that a machine learning model actually starts working before you make it work.
So, let’s begin with how to Train & Test Set in Python Machine Learning.
Train and Test Set in Python Machine Learning – How to Split
Training and Test Data in Python Machine Learning
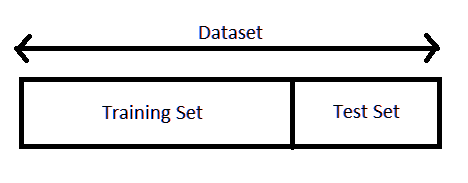
As we work with datasets, a machine learning algorithm works in two stages. We usually split the data around 20%-80% between testing and training stages. Under supervised learning, we split a dataset into training data and test data in Python ML.
Train and Test Set in Python Machine Learning
a. Prerequisites for Train and Test Data
We will need the following Python libraries for this tutorial: pandas and sklearn.
We can install these with pip-
pip install pandas
pip install sklearn
Also, We use pandas to import the dataset and sklearn to perform the splitting. You can import these packages as-
>>> import pandas as pd >>> from sklearn.model_selection import train_test_split >>> from sklearn.datasets import load_iris
Do you Know about Python Data File Formats – How to Read CSV, JSON, XLS
How to Split Train and Test Set in Python Machine Learning?
The following is the process of Train and Test set in Python ML. So, let’s take a dataset first.
How to Split Train and Test Set in Python Machine Learning
a. Loading the Dataset
Let’s load the forestfires dataset using pandas.
>>> data=pd.read_csv('forestfires.csv')
>>> data.head()
Train and Test Set in Python Machine Learning
b. Splitting
Let’s split this data into labels and features. Now, what’s that? Using features, we predict labels. I mean using features (the data we use to predict labels), we predict labels (the data we want to predict).
>>> y=data.temp
>>> x=data.drop('temp',axis=1)Temp is a label to predict temperatures in y; we use the drop() function to take all other data in x. Then, we split the data.
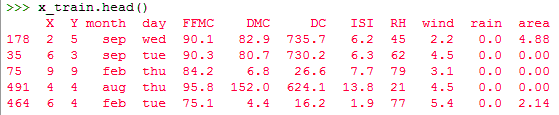
>>> x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2) >>> x_train.head()
Train and Test Set in Python Machine Learning
>>> x_train.shape
(413, 12)
Do you Know How to work with relational databases with Python
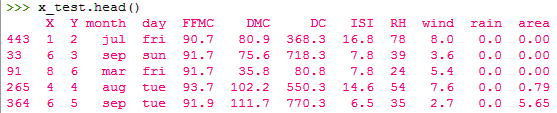
>>> x_test.head()
Train and Test Set in Python Machine Learning
>>> x_test.shape
(104, 12)
The line test_size=0.2 suggests that the test data should be 20% of the dataset and the rest should be train data. With the outputs of the shape() functions, you can see that we have 104 rows in the test data and 413 in the training data.
c. Another Example
Let’s take another example. We’ll use the IRIS dataset this time.
>>> iris=load_iris() >>> x,y=iris.data,iris.target >>> x_train,x_test,y_train,y_test=train_test_split(x,y, train_size=0.5, test_size=0.5, random_state=123) >>> y_test
array([1, 2, 2, 1, 0, 2, 1, 0, 0, 1, 2, 0, 1, 2, 2, 2, 0, 0, 1, 0, 0, 2,
0, 2, 0, 0, 0, 2, 2, 0, 2, 2, 0, 0, 1, 1, 2, 0, 0, 1, 1, 0, 2, 2,
2, 2, 2, 1, 0, 0, 2, 0, 0, 1, 1, 1, 1, 2, 1, 2, 0, 2, 1, 0, 0, 2,
1, 2, 2, 0, 1, 1, 2, 0, 2])
>>> y_train
array([1, 1, 0, 2, 2, 0, 0, 1, 1, 2, 0, 0, 1, 0, 1, 2, 0, 2, 0, 0, 1, 0,
0, 1, 2, 1, 1, 1, 0, 0, 1, 2, 0, 0, 1, 1, 1, 2, 1, 1, 1, 2, 0, 0,
1, 2, 2, 2, 2, 0, 1, 0, 1, 1, 0, 1, 2, 1, 2, 2, 0, 1, 0, 2, 2, 1,
1, 2, 2, 1, 0, 1, 1, 2, 2])
One of the essential approaches when dividing data into training and testing sets is to capture the model’s performance on unseen data. This practice aids in evaluating the model’s performance and potentially recognizing problems such as overfitting or underfitting. We continuously split the dataset in order to check our model’s capabilities of not memorizing the data, yet capable of classifying new instances.
Furthermore, it should be noted that setting the random_state parameter in train_test_split makes the dataset creation repeatable. This parameter is set to a fixed integer to make sure that the same splitting of data is achieved every time a specific model is tested; thus is essential during the testing of the model.
Let’s explore Python Machine Learning Environment Setup
Plotting of Train and Test Set in Python
We fit our model on the training data to make predictions on it. Let’s import the linear_model from sklearn, apply linear regression to the dataset, and plot the results.
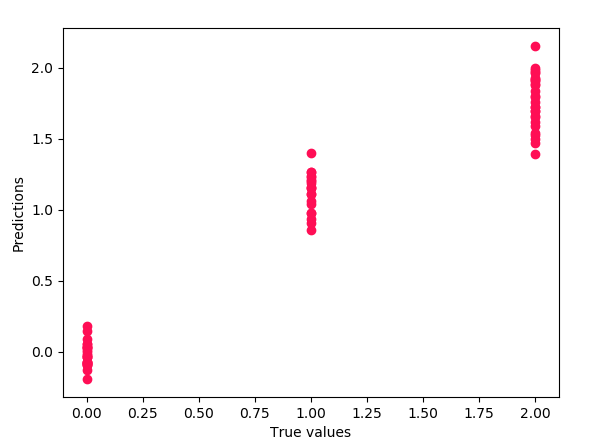
>>> from sklearn.linear_model import LinearRegression as lm >>> model=lm().fit(x_train,y_train) >>> predictions=model.predict(x_test) >>> import matplotlib.pyplot as plt >>> plt.scatter(y_test,predictions)
<matplotlib.collections.PathCollection object at 0x0651CA30>
>>> plt.xlabel('True values')Text(0.5,0,’True values’)
>>> plt.ylabel('Predictions')Text(0,0.5,’Predictions’)
Read about Python NumPy – NumPy ndarray & NumPy Array
>>> plt.show()
Train and Test Set in Python Machine Learning
0.9396299518034936
So, this was all about Train and Test Set in Python Machine Learning. Hope you like our explanation.
Conclusion
Today, we learned how to split a CSV or a dataset into two subsets- the training set and the test set in Python Machine Learning. We usually let the test set be 20% of the entire data set, and the rest 80% will be the training set. Furthermore, if you have a query, feel free to ask in the comment box.
Related Topic- Python Geographic Maps & Graph Data
For reference
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





In item 4, it’s missing
from sklearn.linear_model import LinearRegression
Hello Jeff,
Thanks for connecting us with Train & Test set in Python Machine Learning. We have made the necessary changes. Hope, you are enjoying our other Python tutorials.
Keep learning and keep sharing
DataFlair
>>> model=lm.fit(x_train,y_train)
>>> predictions=lm.predict(x_test)
What is “lm” use for?
Hey Amilcar
Thanks for the query. In this Python Train and Test, article lm stands for Linear Model. You’ll need to import it from sklearn:
>>> from sklearn import linear_model as lm
Hope, it will help you!
Regards
DataFlair
in spider need
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
Hi Carlos,
That’s right, we have made the changes to the code. Now, you can learn the train test set in Python ML easily.
‘module’ object has no attribute ‘fit’
on running lm.fit i am getting following error.
Hello Simran,
Thanks for connecting us through this query. We have made the necessary changes. Now, you can enjoy your learning.
is it possible to set the test and training set with the same pattern
Eg: if training test has weight ranging from 50kg to 70kg and that too with a certain frequency distribution, is it possible to have a similar distribution in the test set too
I just found the error in you post.
i learn from this post.
model=lm.fit(x_train,y_train)
there is an error in this model.
we have to use lm().fit(x_train,y_train)
>>> model=lm.fit(x_train,y_train)
it is error to use lm in this predict here
>>> predictions=lm.predict(x_test)
we should write the code
predictions=model.predict(x_test)
i had fixed like this to get our output correctly
Thank you for this post
Hi Kun Thaung
Thank you for pointing it out! Careful readers like you help make our content accurate and flawless for many others to follow. We have made the necessary corrections in the text.
Thank you, Kun, for acknowledging our mistake. We have corrected our mistake , and it’s encouraging to hear that you have gained something from our post. Please don’t forget to explore our Python projects.
I have been given a task to predict the missing ratings. I have done that using the cosine similarity and some functions used in collaborative recommendations.
So, now I have two datasets.
1. The training set which was already 80% of the original data.
2. The test data set which is 20% and the non-zero ratings are available.
Now, I want to calculate the RMSE between the available ratings in test set and the predicted ratings in training dataset. Please guide me how should I proceed.
The testdata set and train data set are nothing but the data of user*item matrix. Where indexes of the rows represent the users and indexes of the column represent the items.
hi
am getting the error “ValueError: could not convert string to float: ‘sep'” against the line “model = lm().fit(x_train, y_train)”. Can you pls help . I have imported all required packages, and am using pycharm ide.
Thanks
Hello Yuvakumar R,
Maybe you have issues with your dataset- like missing values. Try downloading the forestfires dataset from Kaggle and run the code again, it should work. Or maybe you’re missing a step?
Hello
Can you please tell me how i can use this sklearn for training python with another language i have the dataset need i am not able to understand how do i split it into test and train dataset.
Hello Sudhanshu,
The above article provides a solution to your query. Please read it carefully. Or you can also enroll for DataFlair Python Course with a flat 50% applying the promo code PYTHON50
thank you for your post, it helps more. but i have a question, why we predict on x_test i think we can predict on y_test? is it the same? please help me .
thanks
Hi Francine
Thanks for commenting. x_test is the test data set and y_test is the set of labels to the data in x_test. We cannot predict on y_test- only on x_test.
give a api for tarining a model
Is the promo still on? And does the enrollment include someone to assist you with?
Hey Anih John,
Please drop a mail on [email protected] regarding your query. Our team will guide you about the course and current offers.
Hi!! AoA!
I am here to request that please also do mention in comments against any function that you used. Lile what is the job of data.shap and what if we write data.shape() and simultaneously for all other functions etc that you have used.
Thank you!
Hi Jeff,
As in your code it randomly assigns the data for training and testing but can it be done sequentially means like first 80 to train data set and remaining 20 to test data set if there are overall 100 observations.
What if I have a data having 200 rows and I want the first 150 rows in the training set and the remaining 50 in the testing set how do I go about it
To make the results reproducable you should we should also define random_state.
Here is a way to divide you data using pandas:
training_data = df.sample(frac=0.75, random_state=25)
testing_data = df.drop(training_data.index)
if there are 3 datasets then how we can create train and test folder please solve my problem
You can divide each dataset for trainng and testing 80:20 is a good ratio. Here’s a way to do it:
training_data = df.sample(frac=0.8, random_state=25)
testing_data = df.drop(training_data.index)
superb explanation suppose if i want to add few more datas and i need to test them what should i do?
You can download the dataset in a similar way and then divide them into training and testing data.
How do i split train and test data w.r.t specific time frame, for example i have a bank data set where i want to use 2 years data as train set and 6 months data as test set, how can i split this and fit it to Logistic Regression Model
2 years and 6 months are in the ratio 80:20, so you can use pandas to split the data. Here’s a way to do it:
training_data = df.sample(frac=0.8, random_state=25)
testing_data = df.drop(training_data.index)
AttributeError: ‘DataFrame’ object has no attribute ‘temp’ this error is showing what shud i do
Temp is a label to predict temperatures in y. You might have dropped this first and then you are using it again which is why you are getting this error. Download the dataset again and you will not face this error.
How to load train and taste date if I have already?
I mean I have m_train and m_test data in xls format?
Please also explain validation set, and how to create it
Validation set is a set of data used to train AI models. It contrasts with training and testing test in that it is an intermediate phase used for choosing the best model and optimizing it. It is created in the same way as the training set. We can also use model.fit to create it. For instance:
model.fit(
x=scaled_train_samples
, y=train_labels
, validation_split=0.1
, batch_size=10
, epochs=30
, verbose=2
)
With 0.1 being the value of validation_split, keras splitts apart 10% of data to be used as validation data