Identifiers in Python – Naming Rules and Best Practices
Master Python with 70+ Hands-on Projects and Get Job-ready - Learn Python
Today, in this Python tutorial, we will learn about identifiers in Python and how to name them.
Moreover, we will see the rules, best practices, reserved classes in Python Identifiers. Also, we will test the validity of identifiers in Python.
So, let’s start Identifiers in Python.
What are Identifiers in Python?
We can define identifiers in Python in few ways:
- An identifier is a user-defined name to represent a variable, a function, a class, a module, or any other object.
- It is a programmable entity in Python- one with a name.
- It is a name given to the fundamental building blocks in a program.
Python Identifier Naming Rules
1. Rules for naming Identifiers in Python
So we know what a Python Identifier is. But can we name it anything? Or do certain rules apply?
Well, we do have five rules to follow when naming identifiers in Python:
a. A Python identifier can be a combination of lowercase/ uppercase letters, digits, or an underscore. The following characters are valid:
- Lowercase letters (a to z)
- Uppercase letters (A to Z)
- Digits (0 to 9)
- Underscore (_)
Some valid names are:
- myVar
- var_3
- this_works_too
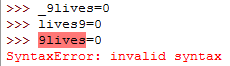
b. An identifier in python cannot begin with a digit. It must start with a letter or underscore.
Some valid names:
- _9lives
- lives9
An invalid name:
- 9lives
Identifiers in Python – Naming Rules
c. We cannot use spaces or special symbols in the identifier name. Some of these are:
!
@
#
$
%
.
Identifiers in Python – Naming Rules in Python
d. We cannot use a keyword as an identifier.
Keywords are reserved names in Python, and using one of those as a name for an identifier will result in a SyntaxError.
Identifiers in Python – Identifiers Naming Rules
Naming Rules in Python Identifiers
e. An identifier in python can be as long as you want. According to the docs, you can have an identifier of infinite length.
However, the PEP-8 standard sets a rule that you should limit all lines to a maximum of 79 characters.
2. Lexical Definitions in Python Identifiers
To sum those rules up lexically, we can say:
- identifier ::= (letter | “_”) (letter | digit | “_”)* #It has to begin with a letter or an underscore; letters, digits, or/and underscores may follow
- letter ::= lowercase | uppercase #Anything from a-z and from A-Z
- lowercase ::= “a” … “z” #Lowercase letters a to z
- uppercase ::= “A” … “Z” #Uppercase letters A to Z
- digit ::= “0” … “9” #Integers 0 to 9
Best Practices for Identifiers in Python
While it’s mandatory to follow the rules, it is also good to follow some recommended practices:
- Begin class names with an uppercase letter, begin all other identifiers with a lowercase letter
- Begin private identifiers with an underscore (_); Note that this doesn’t make a variable private, but discourages the user from attempting to access it
- Put __ around names of magic methods (use leading and trailing double underscores), avoid doing this to anything else.
- Use leading double underscores only when dealing with mangling.
- Prefer using names longer than one character- index=1 is better than i=1
- Use underscores to combine words in an identifier, like in this_is_an_identifier
- Since Python is case-sensitive, name and Name are two different identifiers.
- Use camel case for naming. Let’s just clear the air here by saying camel case is myVarOne and Pascal case is MyVarOne.
- Some words are reserved by Python, like for, while, or class. You cannot use these keywords as identifiers.
Testing the Validity of Identifiers in Python
While it is great to follow the rules and guidelines, we can test an identifier’s validity just to be sure. For this, we make use of the keyword.iskeyword() function.
The keyword module lets us determine whether a string is a keyword. It has two functions:
- keyword.iskeyword(s)- If s is a Python keyword, return true
- Keyword.kwlist- Return a sequence holding all keywords the interpreter understands. This includes even those that are active only when certain __future__ statements are in effect.
Coming back to iskeyword(s), it returns True if the string s is a reserved keyword. Else, it returns False. Let’s import this module.
>>> import keyword
>>> keyword.iskeyword('_$$_')Output
>>> keyword.iskeyword('return')Output
Also, the str.isidentifier() function will tell us if a string is a valid identifier. This is available since Python 3.0.
>>> '__$$__'.isidentifier()
Output
>>> '__99__'.isidentifier()
Output
>>> '9lives'.isidentifier()
Output
>>> '9.5okay'.isidentifier()
Output
Reserved Classes of Python Identifiers
Let us talk about classes of identifiers in Python. Some classes have special meanings, and to identify them, we use patterns of leading and trailing underscores:
1. Single Leading Underscore (_*)
We use a Single Leading Underscore (_*) identifier to store the result of the last evaluation in the interactive interpreter.
This result is stored in the __builtin__ module. Importing a module as from module import * does not import such private variables.
A single underscore means that the method, variable, or function is meant for internal use only. The names that start with a single underscore are usually not imported from a module import in Python.
2. Leading and Trailing Double Underscores (__*__)
These are system-defined names (by the interpreter).
A class can implement operations to be invoked by special syntax using methods with special names.
Consider this an attempt at operator overloading in a Pythonic fashion. One such special/ magic method is __getitem__(). Then, x[i] is equivalent to x.__getitem__(i).
In the near future, the set of names of this class in Python may be extended.
3. Leading Double Underscores (__*)
These are class-private names. Within a class definition, the interpreter rewrites (mangles) such a name to avoid name clashes between the private attributes of base and derived classes.
When you have completed the learning now, do not forget to take Quiz on Python Identifiers to check your knowledge. Also, attempt Interview Questions as below.
Python Interview Questions on Identifiers in Python
1. What are identifiers in Python?
2. What is a valid identifier in Python?
3. Explain identifiers with example.
4. What are reserved classes of Python Identifiers?
5. Explain some of the rules for naming identifiers in Python.
Conclusion
Hence, in this Python Identifiers, we discussed the meaning of Identifiers in Python.
Moreover, we learned naming rules and best practices in Python Identifiers. Also, we discussed reserved classes in Python Identifier.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





>>> keyword.iskeyword(‘if’)
True
>>> ‘if’.isidentifier()
True
I have copied from Python IDLE and pasted …howcome it is showing true in both cases
Hi Pushkar
‘if’.isidentifier() gives us True because keywords are indeed valid identifiers. You can test this with other keywords like ‘def’ and ‘for’.
Hope, it helps.
Hello,
import keyword
keyword.iskeyword(“print”) it says False, but It must be True as I know.
“print”.isidentifier() “this says True
So whats different?
Hello Semih,
Thanks, for asking query regrading Python Identifiers.
print() is a built-in function in Python 3. If you import keyword and check the list of available keywords:
keyword.kwlist
You get this:
[‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘async’, ‘await’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
This is why iskeyword() returns False for names like print and eval, but isidentifier() returns True, because they are indeed valid identifiers and we can actually use them as identifier names:
print=32
Hope, it helps!
Hello,
Thank you a lot, it really helped! 🙂
We are glad to see that you like Python Identifiers tutorial. So not forget to check Python String article now as it will be useful to you.
Hello Semih,
Currenlty I am working on python 2.7.5 version.
As You said, keyword.iskeyword(‘print’) is returning True.
Can you please let me know on which version you checked.
sir,how to use leading and trailing double underscores in program
__var__: It’s a convention, so that python system names that won’t conflict with user names.
_var: It’s a convention used for private variables.
__var: the interpreter replaces this name with _classname__var so that the name will not conflict with a similar name in different class.
No other form of underscores have meaning in the Python.
can you explain with an example
Sure I will give a couple of examples for you to help identify valid and invalid identifiers:
1. var1 is a valid one as it starts with an alphabet and contains only alphanumeric characters
2. Similarly, var_2 is also valid as underscore is allowed to use in an identifier
3. 3var is not valid as it starts with a number, not an alphabet
4. var@4 is not valid as the character @ is not allowed to be used.
5. Also class cannot be an identifier as it is a keyword
Hope these examples help you understand the concept of identifiers.
SirPython ke notes provide nhi honge kya mujhe bnana ta
guys , i am confused how come “if” is a keyword and can be an identifier at the same time?
a= ‘if’
print(a,keyword.iskeyword(a))
print(a.isidentifier())
Output:
if True
True
Process finished with exit code 0