Data Science Project – Detect Credit Card Fraud with Machine Learning in R
Job-ready Online Courses: Click for Success - Start Now!
This is the 3rd part of the R project series designed by DataFlair. Earlier we talked about Uber Data Analysis Project and today we will discuss the Credit Card Fraud Detection Project using Machine Learning and R concepts. In this R Project, we will learn how to perform detection of credit cards. We will go through various algorithms like Decision Trees, Logistic Regression, Artificial Neural Networks and finally, Gradient Boosting Classifier. To detect credit card fraud, we will make use of the Card Transactions dataset that contains a mix of fraud as well as non-fraudulent transactions.
Machine Learning Project – How to Detect Credit Card Fraud
The aim of this R project is to build a classifier that can detect credit card fraudulent transactions. We will use a variety of machine learning algorithms that will be able to discern fraudulent from non-fraudulent one. By the end of this machine learning project, you will learn how to implement machine learning algorithms to perform classification.
The dataset used in this project is available here – Fraud Detection Dataset
1. Importing the Datasets
We are importing the datasets that contain transactions made by credit cards-
Code:
library(ranger)
library(caret)
library(data.table)
creditcard_data <- read.csv("/home/dataflair/data/Credit Card/creditcard.csv")Input Screenshot:

Before moving on, you must revise the concepts of R Dataframes
2. Data Exploration
In this section of the fraud detection ML project, we will explore the data that is contained in the creditcard_data dataframe. We will proceed by displaying the creditcard_data using the head() function as well as the tail() function. We will then proceed to explore the other components of this dataframe –
Code:
dim(creditcard_data) head(creditcard_data,6)
Output Screenshot:
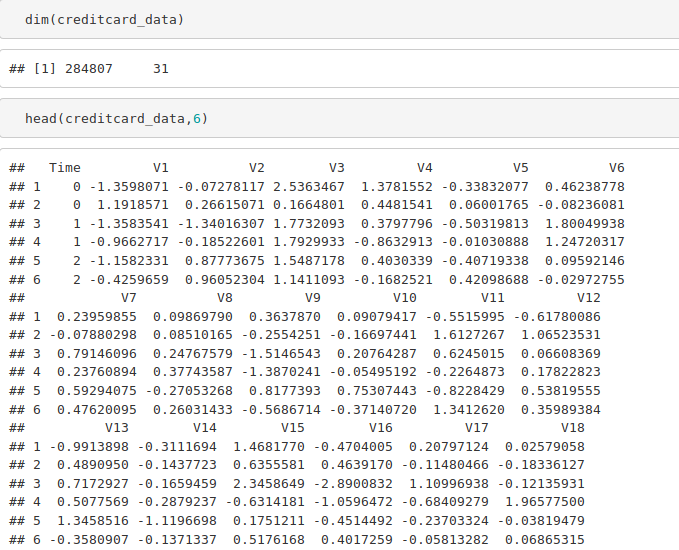
Code:
tail(creditcard_data,6)
Output Screenshot:
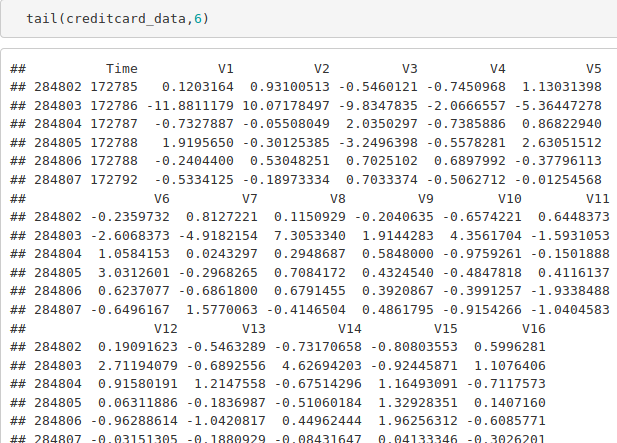
Code:
table(creditcard_data$Class) summary(creditcard_data$Amount) names(creditcard_data) var(creditcard_data$Amount)
Output Screenshot:
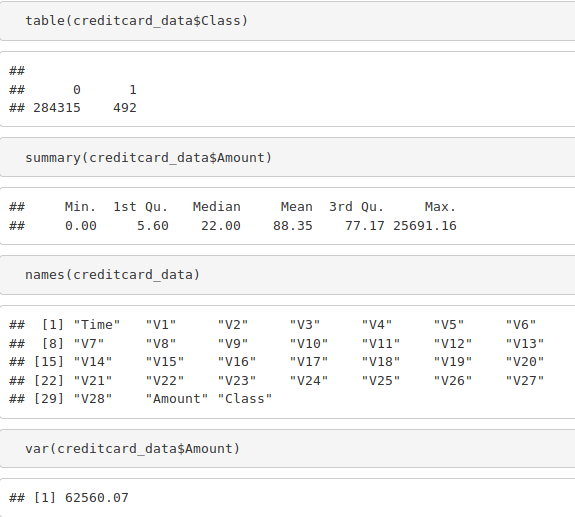
Code:
sd(creditcard_data$Amount)
Output Screenshot:
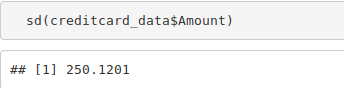
Learn everything about R for FREE and master the technology
3. Data Manipulation
In this section of the R data science project, we will scale our data using the scale() function. We will apply this to the amount component of our creditcard_data amount. Scaling is also known as feature standardization. With the help of scaling, the data is structured according to a specified range. Therefore, there are no extreme values in our dataset that might interfere with the functioning of our model. We will carry this out as follows:
Code:
head(creditcard_data)
Output Screenshot:

Code:
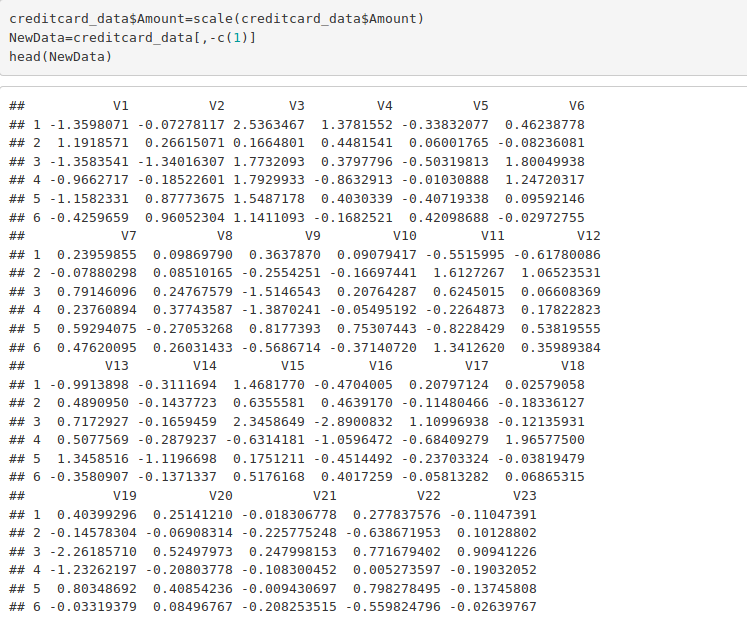
creditcard_data$Amount=scale(creditcard_data$Amount) NewData=creditcard_data[,-c(1)] head(NewData)
Output Screenshot:
4. Data Modeling
After we have standardized our entire dataset, we will split our dataset into training set as well as test set with a split ratio of 0.80. This means that 80% of our data will be attributed to the train_data whereas 20% will be attributed to the test data. We will then find the dimensions using the dim() function –
Code:
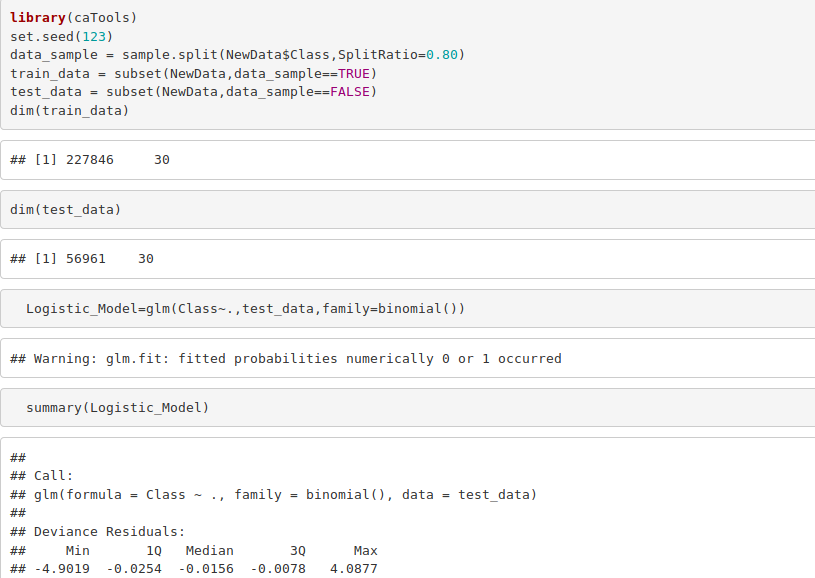
library(caTools) set.seed(123) data_sample = sample.split(NewData$Class,SplitRatio=0.80) train_data = subset(NewData,data_sample==TRUE) test_data = subset(NewData,data_sample==FALSE) dim(train_data) dim(test_data)
Output Screenshot:
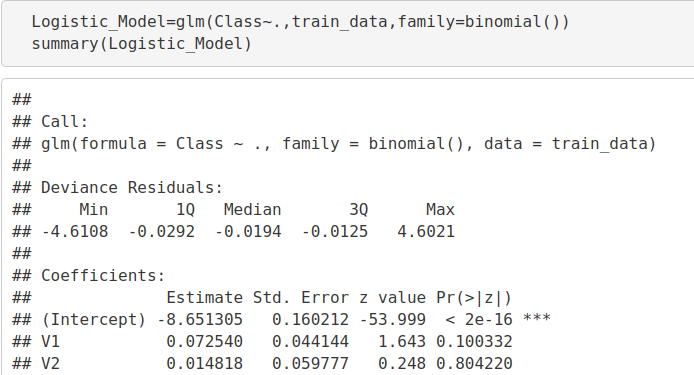
5. Fitting Logistic Regression Model
In this section of credit card fraud detection project, we will fit our first model. We will begin with logistic regression. A logistic regression is used for modeling the outcome probability of a class such as pass/fail, positive/negative and in our case – fraud/not fraud. We proceed to implement this model on our test data as follows –
Code:
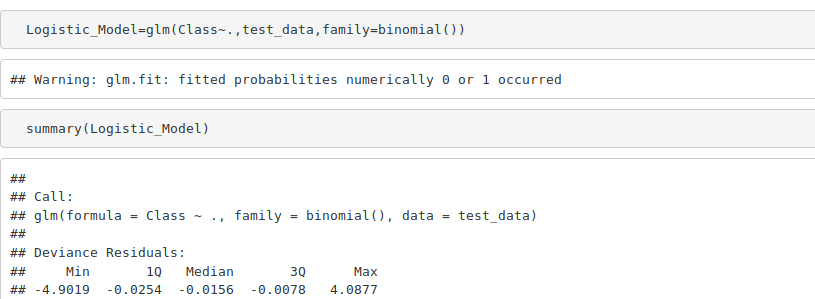
Logistic_Model=glm(Class~.,test_data,family=binomial()) summary(Logistic_Model)
Output Screenshot:
After we have summarised our model, we will visual it through the following plots –
Code:
plot(Logistic_Model)
Input Screenshot:
![]()
Output:
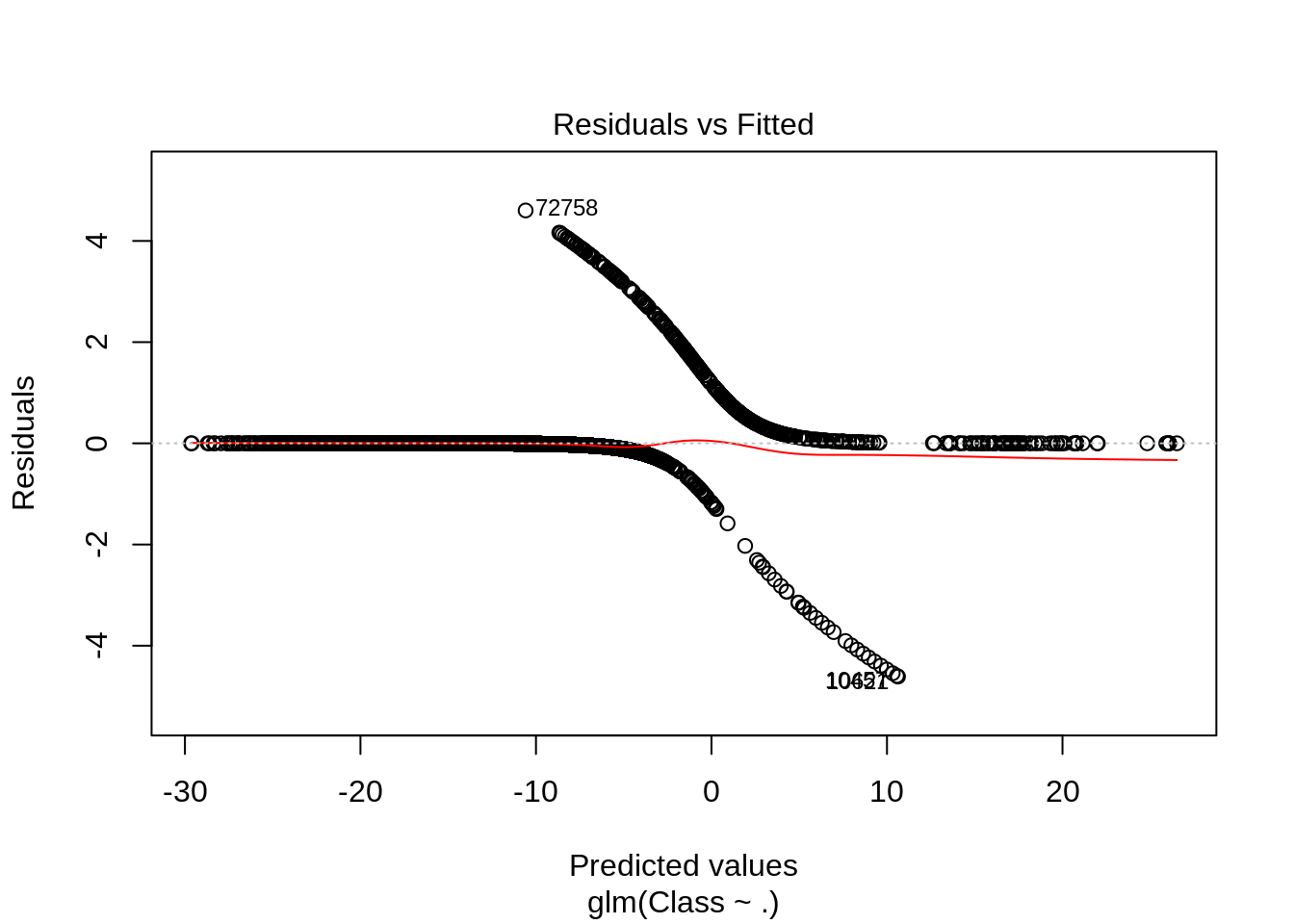
Next Output:
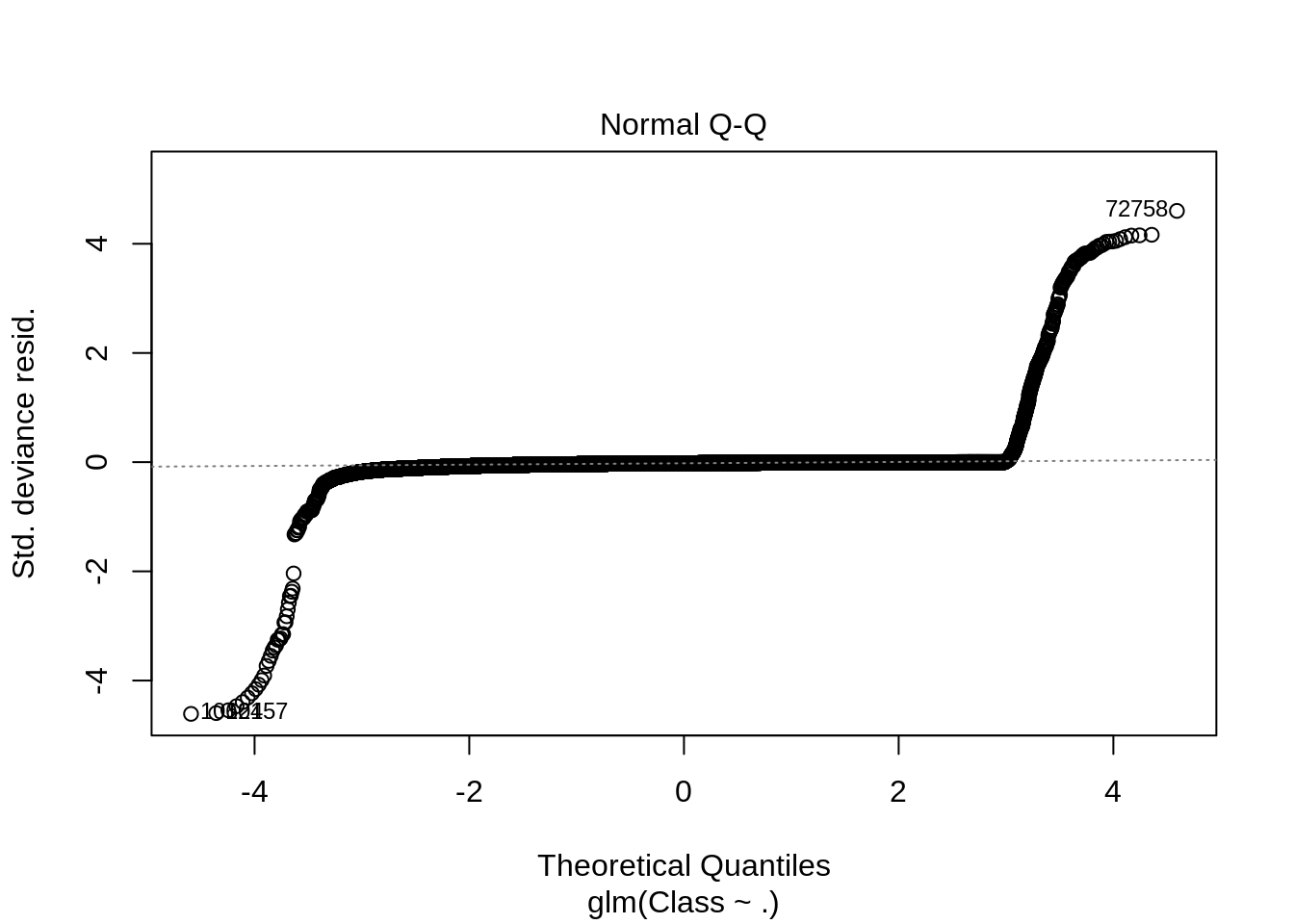
Output:
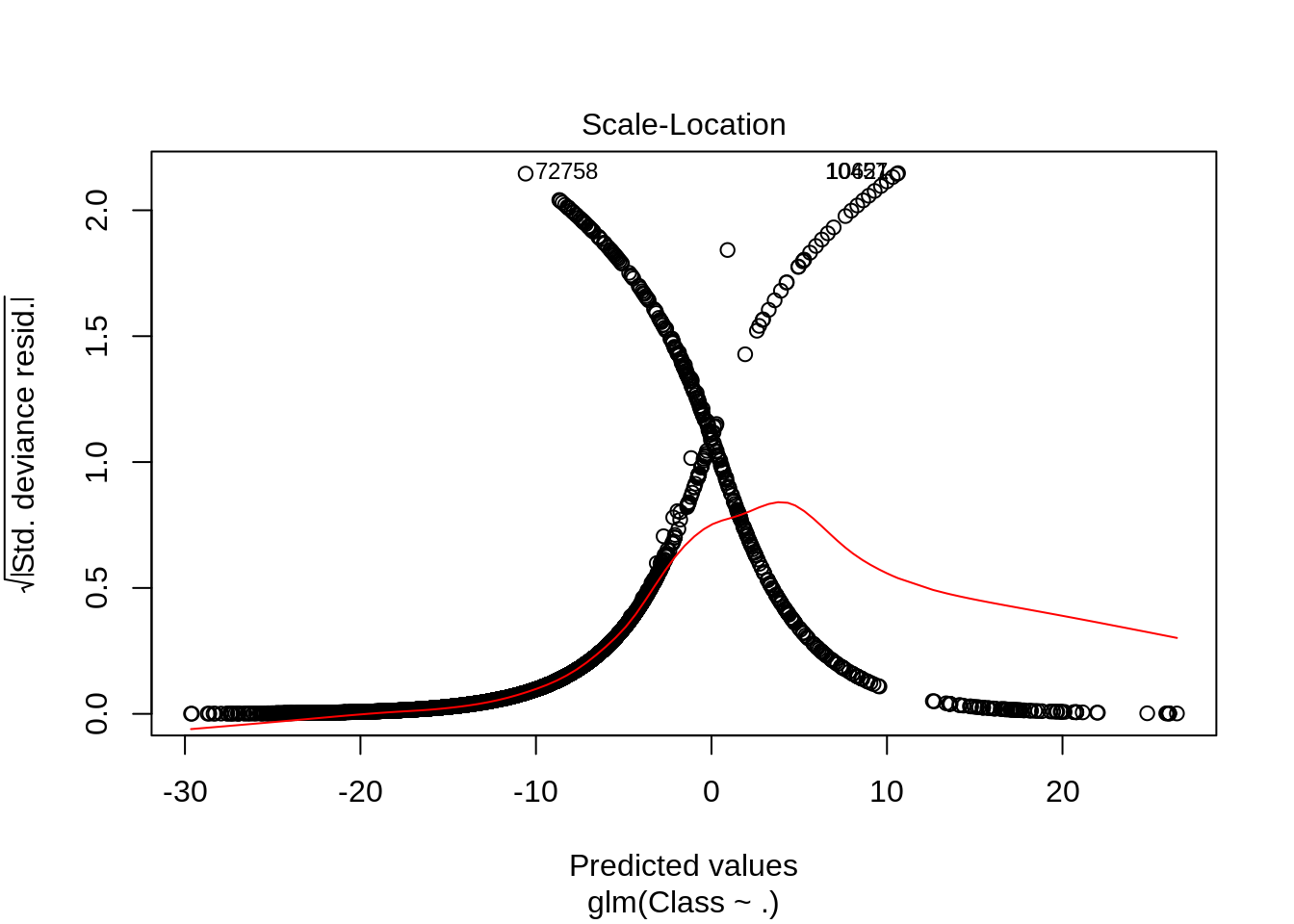
Output:

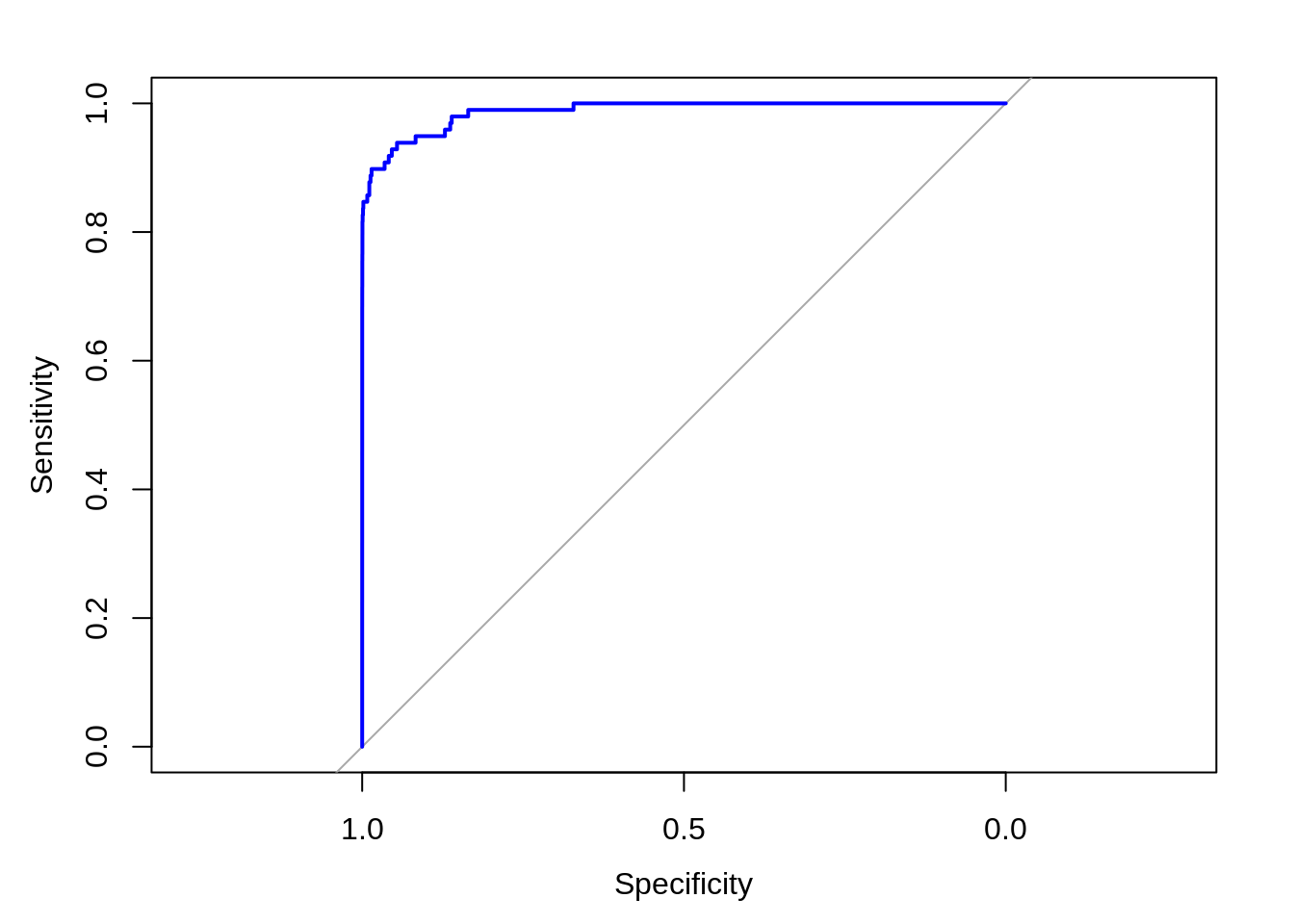
In order to assess the performance of our model, we will delineate the ROC curve. ROC is also known as Receiver Optimistic Characteristics. For this, we will first import the ROC package and then plot our ROC curve to analyze its performance.
Code:
library(pROC) lr.predict <- predict(Logistic_Model,train_data, probability = TRUE) auc.gbm = roc(test_data$Class, lr.predict, plot = TRUE, col = "blue")
Output Screenshot:
Output:
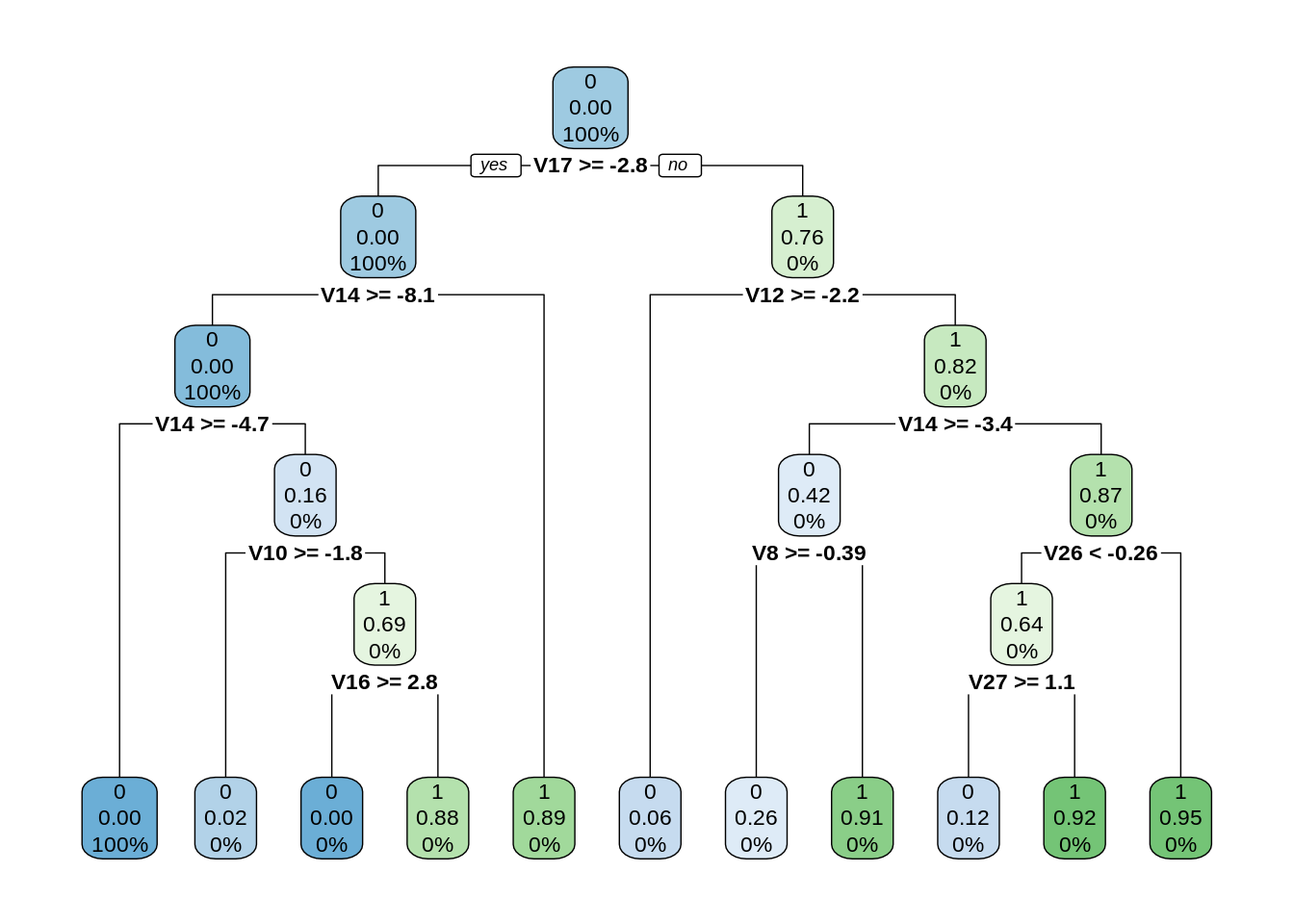
6. Fitting a Decision Tree Model
In this section, we will implement a decision tree algorithm. Decision Trees to plot the outcomes of a decision. These outcomes are basically a consequence through which we can conclude as to what class the object belongs to. We will now implement our decision tree model and will plot it using the rpart.plot() function. We will specifically use the recursive parting to plot the decision tree.
Code:
library(rpart) library(rpart.plot) decisionTree_model <- rpart(Class ~ . , creditcard_data, method = 'class') predicted_val <- predict(decisionTree_model, creditcard_data, type = 'class') probability <- predict(decisionTree_model, creditcard_data, type = 'prob') rpart.plot(decisionTree_model)
Input Screenshot:

Output:
7. Artificial Neural Network
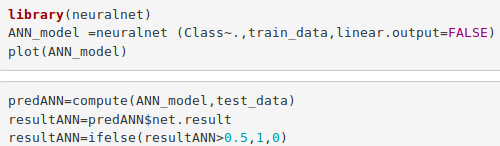
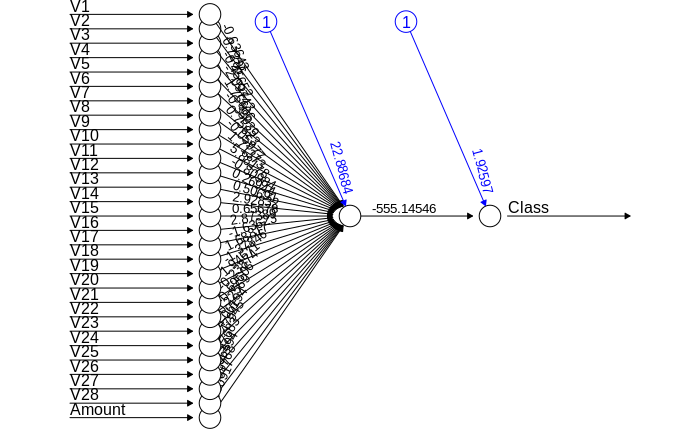
Artificial Neural Networks are a type of machine learning algorithm that are modeled after the human nervous system. The ANN models are able to learn the patterns using the historical data and are able to perform classification on the input data. We import the neuralnet package that would allow us to implement our ANNs. Then we proceeded to plot it using the plot() function. Now, in the case of Artificial Neural Networks, there is a range of values that is between 1 and 0. We set a threshold as 0.5, that is, values above 0.5 will correspond to 1 and the rest will be 0. We implement this as follows –
Code:
library(neuralnet) ANN_model =neuralnet (Class~.,train_data,linear.output=FALSE) plot(ANN_model) predANN=compute(ANN_model,test_data) resultANN=predANN$net.result resultANN=ifelse(resultANN>0.5,1,0)
Input Screenshot:
Output:
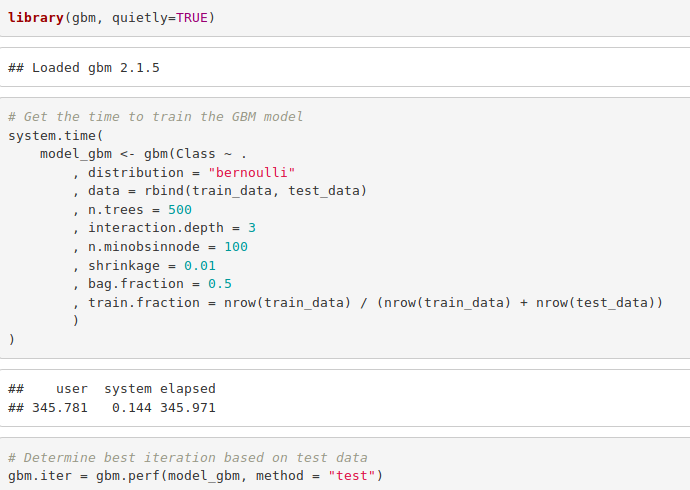
8. Gradient Boosting (GBM)
Gradient Boosting is a popular machine learning algorithm that is used to perform classification and regression tasks. This model comprises of several underlying ensemble models like weak decision trees. These decision trees combine together to form a strong model of gradient boosting. We will implement gradient descent algorithm in our model as follows –
Code:
library(gbm, quietly=TRUE)
# Get the time to train the GBM model
system.time(
model_gbm <- gbm(Class ~ .
, distribution = "bernoulli"
, data = rbind(train_data, test_data)
, n.trees = 500
, interaction.depth = 3
, n.minobsinnode = 100
, shrinkage = 0.01
, bag.fraction = 0.5
, train.fraction = nrow(train_data) / (nrow(train_data) + nrow(test_data))
)
)
# Determine best iteration based on test data
gbm.iter = gbm.perf(model_gbm, method = "test")
Input Screenshot:
Code:
model.influence = relative.influence(model_gbm, n.trees = gbm.iter, sort. = TRUE) #Plot the gbm model plot(model_gbm)
Input Screenshot:

Output:
Output:
 Code:
Code:
# Plot and calculate AUC on test data gbm_test = predict(model_gbm, newdata = test_data, n.trees = gbm.iter) gbm_auc = roc(test_data$Class, gbm_test, plot = TRUE, col = "red")
Output Screenshot:

Code:
print(gbm_auc)
Output Screenshot:

Summary
Concluding our R Data Science project, we learnt how to develop our credit card fraud detection model using machine learning. We used a variety of ML algorithms to implement this model and also plotted the respective performance curves for the models. We learnt how data can be analyzed and visualized to discern fraudulent transactions from other types of data.
Machine learning is an expanding field and there are always different models when it comes to fraud detection, which showcases how the methods implemented in this project include multiple models. This means that after comparing the logistic regression, decision trees, artificial neural networks, and gradient boosting we will be able to see which of the four models is more appropriate for our dataset type as well as the problem domain.
The models should be further developed and improved consistently as the nature of the financial transactions changes with sophisticated frauds. Using a machine learning approach we are able to come up with more enhanced fraud detection systems that have the ability to not only identify existing fraud especially the frequent ones but to also identify new ones.
So, now you are ready to detect the fraud. Machine Learning and R are the important technologies of this decade and will last forever. What are you waiting for? Start learning the machine learning concepts for FREE with the help of DataFlair’s Machine Learning Tutorial Series.
Hope you enjoyed the above R project. Share your experience and queries through comments.
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





The source code is deleted?! Why?!