Gradient Boosting Algorithm – Working and Improvements
Machine Learning courses with 100+ Real-time projects Start Now!!
In this Machine Learning Tutorial, we will study Gradient Boosting Algorithm. Also, we will learn Boosting Algorithm history & purpose. Along with this, we will also study the working of Gradient Boosting Algorithm, at last, we will discuss improvements to Gradient Boosting Algorithm.
What is Gradient Boosting in Machine Learning?
- Gradient Boosting,
- XGBoost,
- AdaBoost,
- Gentle Boost etc.
History of Boosting Algorithm
Purpose of Boosting Algorithm
Stagewise Additive Modeling
AdaBoost
Gradient Boosting Algorithm
What is Gradient Boosting Algorithm
a. Loss Functions and Gradients
Stochastic Gradient Boosting Algorithm
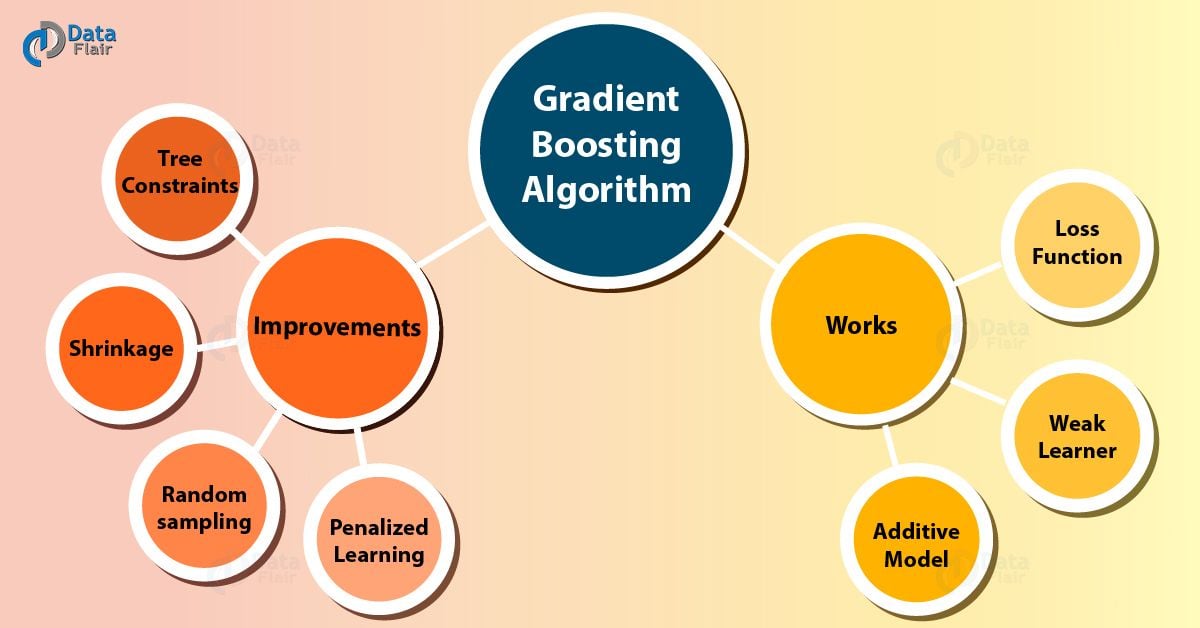
How is the Gradient Boosting Algorithm Works?
Gradient boosting Algorithm involves three elements:
- A loss function to be optimized.
- Weak learner to make predictions.
- An additive model to add weak learners to minimize the loss function.
a. Loss Function
- The loss function used depends on the type of problem being solved.
- It must be differentiable. Although, many standard loss functions are supported and you can define your own.
b. Weak Learner
- We use decision trees as the weak learner in gradient boosting algorithm.
- Specifically, we use regression tree that output real values for splits. And whose output can be added together. It allows next models outputs to be added and “correct” the residuals in the predictions.
- Trees need to construct in a greedy manner. It helps in choosing the best split points based on purity scores like Gini or to cut the loss.
- Initially, such as in the case of AdaBoost. Also, we use very short decision trees that only had a single split, called a decision stump.
- Generally, we use larger trees with 4-to-8 levels.
- It is common to constrain the weak learners in specific ways. Such as a maximum number of layers, nodes, splits or leaf nodes.
- This is to ensure that the learners remain weak, but can still need to construct in a greedy manner.
Furthermore, every tree built with a big size can accommodate more complicated details of the data and make the model work well in the subsequent application. However, this also implies that the model is subjected to over-fitting and sometimes cross-validation is needed in order to test the right tree size and number of iterations.
c. Additive Model
- Trees need to add one at a time, and existing trees in the model need not change.
- We use a gradient descent procedure to minimize the loss when adding trees.
- Traditionally, we use gradient tree to cut a set of parameters. Such as the coefficients in a regression equation or weights in a neural network. After calculating error or loss, the weights need to be update to minimize that error.
- Instead of parameters, we have weak learner sub-models or more specifically decision trees. After calculating the loss, to perform the gradient descent procedure. We must add a tree to the model that reduces the loss.
- We do this by parameterizing the tree. Then change the parameters of the tree and move in the right direction by (reducing the residual loss.
Learn about Pros And Cons of Machine Learning
Improvements to Basic Gradient Boosting Algorithm
- Tree Constraints
- Shrinkage
- Random sampling
- Penalized Learning
a. Tree Constraints
- It is important that the weak learners have skill but remain weak.
- There are many ways that the trees need to be a constraint.
b. Weighted Updates
- The predictions of each tree have to add together sequentially.
- The contribution of each tree to this sum needs to be weight to slow down the learning by the algorithm. This weighting is referred as a shrinkage or a learning rate.
c. Stochastic Gradient Boosting algorithm
- A big insight into bagging ensembles. Also, the random forest was allowing trees to create.
- This same benefit can be used to reduce the correlation between the trees.
- This variation of boosting is referred as stochastic gradient boosting.
d. Penalized Gradient Boosting algorithm
- L1 regularization of weights.
- L2 regularization of weights.
Also, L1 and L2 norms are used in regularization so that the coefficients are not large and hence there be no overfitting. This is especially important when applying the algorithm to high-dimensional data since there is higher possibility of over-fitting.
Conclusion
Gradient Boosting is a machine learning technique used for building strong models by combining many weak ones. It works by creating decision trees one at a time. Each new tree tries to fix the mistakes made by the trees before it. This step-by-step correction process helps the model learn better and give more accurate results. It’s especially good for handling messy or complicated data that doesn’t follow clear patterns.
Furthermore, if you have any queries, feel free to ask in the comment section.
For reference
Your opinion matters
Please write your valuable feedback about DataFlair on Google





I got 97.82% of accuracy while using the credit card dataset with oversampling using adasyn and applied to GBTClassifier(gradient Boost) in python. how can I improve the accuracy