What is Spark – Apache Spark Tutorial for Beginners
1. Objective – Spark Tutorial
What is Spark? Why there is a serious buzz going on about this technology? I hope this Spark introduction tutorial will help to answer some of these questions.
Apache Spark is an open-source cluster computing system that provides high-level API in Java, Scala, Python and R. It can access data from HDFS, Cassandra, HBase, Hive, Tachyon, and any Hadoop data source. And run in Standalone, YARN and Mesos cluster manager.
What is Spark tutorial will cover Spark ecosystem components, Spark video tutorial, Spark abstraction – RDD, transformation, and action in Spark RDD. The objective of this introductory guide is to provide Spark Overview in detail, its history, Spark architecture, deployment model and RDD in Spark.
What is Spark – Apache Spark Tutorial for Beginners
2. What is Spark?
Apache Spark is a general-purpose & lightning fast cluster computing system. It provides a high-level API. For example, Java, Scala, Python, and R. Apache Spark is a tool for Running Spark Applications. Spark is 100 times faster than Bigdata Hadoop and 10 times faster than accessing data from disk.
Spark is written in Scala but provides rich APIs in Scala, Java, Python, and R.
It can be integrated with Hadoop and can process existing Hadoop HDFS data. Follow this guide to learn How Spark is compatible with Hadoop?
It is saying that the images are the worth of a thousand words. To keep this in mind we have also provided Spark video tutorial for more understanding of Apache Spark.
3. History Of Apache Spark
Apache Spark was introduced in 2009 in the UC Berkeley R&D Lab, later it becomes AMPLab. It was open sourced in 2010 under BSD license. In 2013 spark was donated to Apache Software Foundation where it became top-level Apache project in 2014.
4. Why Spark?
After studying Apache Spark introduction lets discuss, why Spark come into existence?
In the industry, there is a need for a general-purpose cluster computing tool as:
- Hadoop MapReduce can only perform batch processing.
- Apache Storm / S4 can only perform stream processing.
- Apache Impala / Apache Tez can only perform interactive processing
- Neo4j / Apache Giraph can only perform graph processing
Hence in the industry, there is a big demand for a powerful engine that can process the data in real-time (streaming) as well as in batch mode. There is a need for an engine that can respond in sub-second and perform in-memory processing.
Apache Spark Definition says it is a powerful open-source engine that provides real-time stream processing, interactive processing, graph processing, in-memory processing as well as batch processing with very fast speed, ease of use and standard interface. This creates the difference between Hadoop vs Spark and also makes a huge comparison between Spark vs Storm.
In this What is Spark tutorial, we discussed a definition of spark, history of spark and importance of spark. Now let’s move towards spark components.
5. Apache Spark Components
Apache Spark puts the promise for faster data processing and easier development. How Spark achieves this? To answer this question, let’s introduce the Apache Spark ecosystem which is the important topic in Apache Spark introduction that makes Spark fast and reliable. These components of Spark resolves the issues that cropped up while using Hadoop MapReduce.
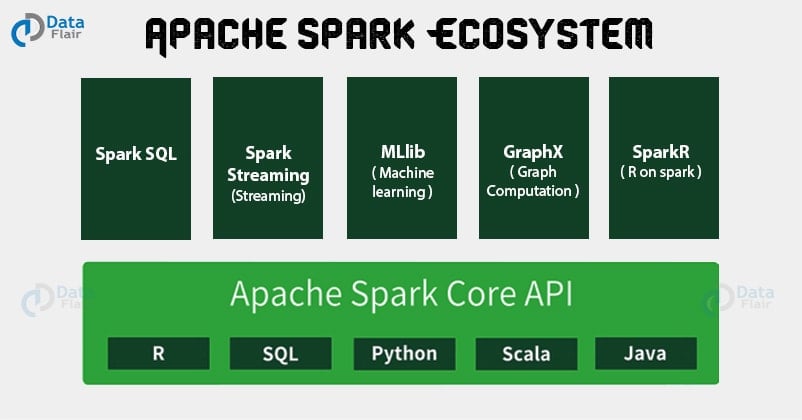
What is Spark – Spark Ecosystem Components
Here we are going to discuss Spark Ecosystem Components one by one
i. Spark Core
It is the kernel of Spark, which provides an execution platform for all the Spark applications. It is a generalized platform to support a wide array of applications.
ii. Spark SQL
It enables users to run SQL/HQL queries on the top of Spark. Using Apache Spark SQL, we can process structured as well as semi-structured data. It also provides an engine for Hive to run unmodified queries up to 100 times faster on existing deployments. Refer Spark SQL Tutorial for detailed study.
iii. Spark Streaming
Apache Spark Streaming enables powerful interactive and data analytics application across live streaming data. The live streams are converted into micro-batches which are executed on top of spark core. Refer our Spark Streaming tutorial for detailed study of Apache Spark Streaming.
iv. Spark MLlib
It is the scalable machine learning library which delivers both efficiencies as well as the high-quality algorithm. Apache Spark MLlib is one of the hottest choices for Data Scientist due to its capability of in-memory data processing, which improves the performance of iterative algorithm drastically.
v. Spark GraphX
Apache Spark GraphX is the graph computation engine built on top of spark that enables to process graph data at scale.
vi. SparkR
It is R package that gives light-weight frontend to use Apache Spark from R. It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. The main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark.
Refer Spark Ecosystem Guide for detailed study of Spark components.
6. Resilient Distributed Dataset – RDD
In this section of Apache Spark Tutorial, we will discuss the key abstraction of Spark knows as RDD.
Resilient Distributed Dataset (RDD) is the fundamental unit of data in Apache Spark, which is a distributed collection of elements across cluster nodes and can perform parallel operations. Spark RDDs are immutable but can generate new RDD by transforming existing RDD.
There are three ways to create RDDs in Spark:
- Parallelized collections – We can create parallelized collections by invoking parallelize method in the driver program.
- External datasets – By calling a textFile method one can create RDDs. This method takes URL of the file and reads it as a collection of lines.
- Existing RDDs – By applying transformation operation on existing RDDs we can create new RDD.
Learn How to create RDD in Spark in detail.
Apache Spark RDDs support two types of operations:
- Transformation – Creates a new RDD from the existing one. It passes the dataset to the function and returns new dataset.
- Action – Spark Action returns final result to driver program or write it to the external data store.
Refer this link to learn RDD Transformations and Actions APIs with examples.
7. Spark Shell
Apache Spark provides an interactive spark-shell. It helps Spark applications to easily run on the command line of the system. Using the Spark shell we can run/test our application code interactively. Spark can read from many types of data sources so that it can access and process a large amount of data.
So, this was all in the tutorial explaining what is Spark. Hope you like our tutorial.
8. Conclusion – What is Spark?
What is Spark tutorial, provides a collection of technologies that increase the value of big data and permits new Spark use cases. It gives us a unified framework for creating, managing and implementing Spark big data processing requirements. Spark video tutorial provides you a detailed information about Spark.
In addition to the MapReduce operations, one can also implement SQL queries and process streaming data through Spark, which were the drawbacks for Hadoop-1. With Spark, developers can develop with Spark features either on a stand-alone basis or, combine them with MapReduce programming techniques.
See Also
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Super article that has covered complete Spark details in 1 post itself. Please share some real life use cases of Apache Spark to learn this technology further.
Hi Shandy,
We are happy that our “Spark Tutorial for Beginners” helped you to learn spark. You can read use cases of Spark from our website or visit this link Apache Spark Use Cases
Regard, Data-Flair
I must say it’s one place to learn completely about Apache Spark. Wonderful guide for Apache Spark. Thanks
Thank you for taking part in our journey!
We appreciate your feedback on “Apache Spark Tutorial”. We hope you visit other spark tutorials like components of Spark like Spark Core, Spark MLlib Etc.
Regard,
Data-Flair
Complete guide and introduction to spark. I enjoyed it and was very easy to understand and consume.
Hi Bhaskar Lakshmikanth,
Words can’t describe how grateful we are for your appreciation. This blog is specially designed for Spark Beginners. Keep learning Keep Liking
Regards,
Data-Flair
Wow.. great theoretical explanation for each and every concept in Spark. I enjoyed it
Hi Prasad Palli,
It’s our Pleasure that you like the “Apache Spark Tutorial”. If you learned Apache Spark completely you can move towards other technologies like Apache Kafka, Apache Avro from Data-Flair. These are the latest & trendy technologies in Big Data World.
Regards,
Data-Flair
Very indepth Spark tutorial this is. Do share similar tutorial on Apache Flink as well as my company in Europe needs me to learn Apache Flink now as Flink is the most demanding technology of 2017.
Hope you will help soon.
Hi Smith,
Thank you for Appreciating our blog.
YES, Apache Flink is very hot and trendy technology in Big Data World. you can explore our Apache Flink Tutorials, where we daily post our new blogs on Apache Flink.
Refer this link Apache Flink Tutorial
Regards,
Data-Flair
PLEASE SOME ONE EXPLAIN ME .
for example
1) HDFS is kind of many system connected to each other to store data.
2)pig or hive is used to get that data or say process that data to get the required output.
Now i am confuse,
is spark an application kind of hive or pig which get dta from the same cluster of machine(hdfs)
or some thing different.
It has been many dats to figure this thing.
kindly help
wallmart or amazons page will have less products and advertisement then yours. leave this e learnings business and start e shopping business.