Apache Spark Ecosystem – Complete Spark Components Guide
1. Objective
In this tutorial on Apache Spark ecosystem, we will learn what is Apache Spark, what is the ecosystem of Apache Spark. It also covers components of Spark ecosystem like Spark core component, Spark SQL, Spark Streaming, Spark MLlib, Spark GraphX and SparkR. We will also learn the features of Apache Spark ecosystem components in this Spark tutorial.
Apache Spark Ecosystem – Complete Spark Components Guide
2. What is Apache Spark?
Apache Spark is general purpose cluster computing system. It provides high-level API in Java, Scala, Python, and R. Spark provide an optimized engine that supports general execution graph. It also has abundant high-level tools for structured data processing, machine learning, graph processing and streaming. The Spark can either run alone or on an existing cluster manager. Follow this link to Learn more about Apache Spark.
3. Introduction to Apache Spark Ecosystem Components
Apache Spark Ecosystem – Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX, SparkR.
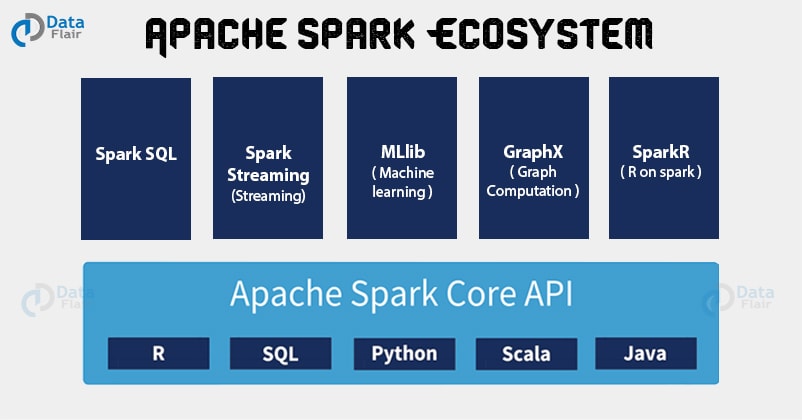
Following are 6 components in Apache Spark Ecosystem which empower to Apache Spark- Spark Core, Spark SQL, Spark Streaming, Spark MLlib, Spark GraphX, and SparkR.
Let us now learn about these Apache Spark ecosystem components in detail below:
3.1. Apache Spark Core
All the functionalities being provided by Apache Spark are built on the top of Spark Core. It delivers speed by providing in-memory computation capability. Thus Spark Core is the foundation of parallel and distributed processing of huge dataset.
The key features of Apache Spark Core are:
- It is in charge of essential I/O functionalities.
- Significant in programming and observing the role of the Spark cluster.
- Task dispatching.
- Fault recovery.
- It overcomes the snag of MapReduce by using in-memory computation.
Spark Core is embedded with a special collection called RDD (resilient distributed dataset). RDD is among the abstractions of Spark. Spark RDD handles partitioning data across all the nodes in a cluster. It holds them in the memory pool of the cluster as a single unit. There are two operations performed on RDDs: Transformation and Action-
- Transformation: It is a function that produces new RDD from the existing RDDs.
- Action: In Transformation, RDDs are created from each other. But when we want to work with the actual dataset, then, at that point we use Action.
Refer these guides to learn more about Spark RDD Transformations & Actions API and Different ways to create RDD in Spark.
3.2. Apache Spark SQL
The Spark SQL component is a distributed framework for structured data processing. Using Spark SQL, Spark gets more information about the structure of data and the computation. With this information, Spark can perform extra optimization. It uses same execution engine while computing an output. It does not depend on API/ language to express the computation.
Spark SQL works to access structured and semi-structured information. It also enables powerful, interactive, analytical application across both streaming and historical data. Spark SQL is Spark module for structured data processing. Thus, it acts as a distributed SQL query engine.
Features of Spark SQL include:
- Cost based optimizer. Follow Spark SQL Optimization tutorial to learn more.
- Mid query fault-tolerance: This is done by scaling thousands of nodes and multi-hour queries using the Spark engine. Follow this guide to Learn more about Spark fault tolerance.
- Full compatibility with existing Hive data.
- DataFrames and SQL provide a common way to access a variety of data sources. It includes Hive, Avro, Parquet, ORC, JSON, and JDBC.
- Provision to carry structured data inside Spark programs, using either SQL or a familiar Data Frame API.
3.3. Apache Spark Streaming
It is an add-on to core Spark API which allows scalable, high-throughput, fault-tolerant stream processing of live data streams. Spark can access data from sources like Kafka, Flume, Kinesis or TCP socket. It can operate using various algorithms. Finally, the data so received is given to file system, databases and live dashboards. Spark uses Micro-batching for real-time streaming.
Micro-batching is a technique that allows a process or task to treat a stream as a sequence of small batches of data. Hence Spark Streaming, groups the live data into small batches. It then delivers it to the batch system for processing. It also provides fault tolerance characteristics. Learn Spark Streaming in detail from this Apache Spark Streaming Tutorial.
How does Spark Streaming Works?
There are 3 phases of Spark Streaming:
a. GATHERING
The Spark Streaming provides two categories of built-in streaming sources:
- Basic sources: These are the sources which are available in the StreamingContext API. Examples: file systems, and socket connections.
- Advanced sources: These are the sources like Kafka, Flume, Kinesis, etc. are available through extra utility classes. Hence Spark access data from different sources like Kafka, Flume, Kinesis, or TCP sockets.
b. PROCESSING
The gathered data is processed using complex algorithms expressed with a high-level function. For example, map, reduce, join and window. Refer this guide to learn Spark Streaming transformations operations.
c. DATA STORAGE
The Processed data is pushed out to file systems, databases, and live dashboards.
Spark Streaming also provides high-level abstraction. It is known as discretized stream or DStream.
DStream in Spark signifies continuous stream of data. We can form DStream in two ways either from sources such as Kafka, Flume, and Kinesis or by high-level operations on other DStreams. Thus, DStream is internally a sequence of RDDs.
3.4. Apache Spark MLlib (Machine Learning Library)
MLlib in Spark is a scalable Machine learning library that discusses both high-quality algorithm and high speed.
The motive behind MLlib creation is to make machine learning scalable and easy. It contains machine learning libraries that have an implementation of various machine learning algorithms. For example, clustering, regression, classification and collaborative filtering. Some lower level machine learning primitives like generic gradient descent optimization algorithm are also present in MLlib.
In Spark Version 2.0 the RDD-based API in spark.mllib package entered in maintenance mode. In this release, the DataFrame-based API is the primary Machine Learning API for Spark. So, from now MLlib will not add any new feature to the RDD based API.
The reason MLlib is switching to DataFrame-based API is that it is more user-friendly than RDD. Some of the benefits of using DataFrames are it includes Spark Data sources, SQL DataFrame queries Tungsten and Catalyst optimizations, and uniform APIs across languages. MLlib also uses the linear algebra package Breeze. Breeze is a collection of libraries for numerical computing and machine learning.
3.5. Apache Spark GraphX
GraphX in Spark is API for graphs and graph parallel execution. It is network graph analytics engine and data store. Clustering, classification, traversal, searching, and pathfinding is also possible in graphs. Furthermore, GraphX extends Spark RDD by bringing in light a new Graph abstraction: a directed multigraph with properties attached to each vertex and edge.
GraphX also optimizes the way in which we can represent vertex and edges when they are primitive data types. To support graph computation it supports fundamental operators (e.g., subgraph, join Vertices, and aggregate Messages) as well as an optimized variant of the Pregel API.
3.6. Apache SparkR
SparkR was Apache Spark 1.4 release. The key component of SparkR is SparkR DataFrame. DataFrames are a fundamental data structure for data processing in R. The concept of DataFrames extends to other languages with libraries like Pandas etc.
R also provides software facilities for data manipulation, calculation, and graphical display. Hence, the main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark. It is R package that gives light-weight frontend to use Apache Spark from R.
There are various benefits of SparkR:
- Data Sources API: By tying into Spark SQL’s data sources API SparkR can read in data from a variety of sources. For example, Hive tables, JSON files, Parquet files etc.
- Data Frame Optimizations: SparkR DataFrames also inherit all the optimizations made to the computation engine in terms of code generation, memory management.
- Scalability to many cores and machines: Operations that executes on SparkR DataFrames get distributed across all the cores and machines available in the Spark cluster. As a result, SparkR DataFrames can run on terabytes of data and clusters with thousands of machines.
4. Conclusion
Apache Spark amplifies the existing Bigdata tool for analysis rather than reinventing the wheel. It is Apache Spark Ecosystem Components that make it popular than other Bigdata frameworks. Hence, Apache Spark is a common platform for different types of data processing. For example, real-time data analytics, Structured data processing, graph processing, etc.
Therefore Apache Spark is gaining considerable momentum and is a promising alternative to support ad-hoc queries. It also provide iterative processing logic by replacing MapReduce. It offers interactive code execution using Python and Scala REPL but you can also write and compile your application in Scala and Java.
Got a question about Apache Spark ecosystem component? Notify us by leaving a comment and we will get back to you.
See Also-
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google




