Apache Spark Executor for Executing Spark Tasks
1. Objective
In Apache Spark, some distributed agent is responsible for executing tasks, this agent is what we call Spark Executor. This document aims the whole concept of Apache Spark Executor. Also, we will see the method to create executor instance in Spark. To learn in depth, we will also see the launch task method in Spark Executor.

Apache Spark Executor for Executing Spark Tasks
You must test your Spark Learning
2. What is Spark Executor
Basically, we can say Executors in Spark are worker nodes. Those help to process in charge of running individual tasks in a given Spark job. Moreover, we launch them at the start of a Spark application. Then it typically runs for the entire lifetime of an application. As soon as they have run the task, sends results to the driver. Executors also provide in-memory storage for Spark RDDs that are cached by user programs through Block Manager.
In addition, for the complete lifespan of a spark application, it runs. That infers the static allocation of Spark executor. However, we can also prefer for dynamic allocation.
Moreover, with the help of Heartbeat Sender Thread, it sends metrics and heartbeats. One of the advantage we can have as many executors in Spark as data nodes. Moreover also possible to have as many cores as you can get from the cluster. The other way to describe Apache Spark Executor is either by their id, hostname, environment (as SparkEnv), or classpath.
The most important point to note is Executor backends exclusively manage Executor in Spark.
Have a look at top Spark Certifications

Heartbeat Receiver’s Heartbeat Message Handler – Spark Executor
3. Conditions to Create Spark Executor
Some conditions in which we create Executor in Spark is:
- When CoarseGrainedExecutorBackend receives RegisteredExecutor message. Only for Spark Standalone and YARN.
- While Mesos’s MesosExecutorBackend registered on Spark.
- When LocalEndpoint is created for local mode.
4. Creating Spark Executor Instance
By using the following, we can create the Spark Executor:
- From Executor ID.
- By using SparkEnv we can access the local MetricsSystem as well as BlockManager. Moreover, we can also access the local serializer by it.
- From Executor’s hostname.
- To add to tasks’ classpath, a collection of user-defined JARs. By default, it is empty.
- By flag whether it runs in local or cluster mode (disabled by default, i.e. cluster is preferred)
You must read Spark SQL Features
Moreover, when creation is successful, the one INFO messages pop up in the logs. That is:
INFO Executor: Starting executor ID [executorId] on host [executorHostname]
5. Heartbeater — Heartbeat Sender Thread
Basically, with a single thread, heartbeater is a daemon ScheduledThreadPoolExecutor.
We call this thread pool a driver-heartbeater.
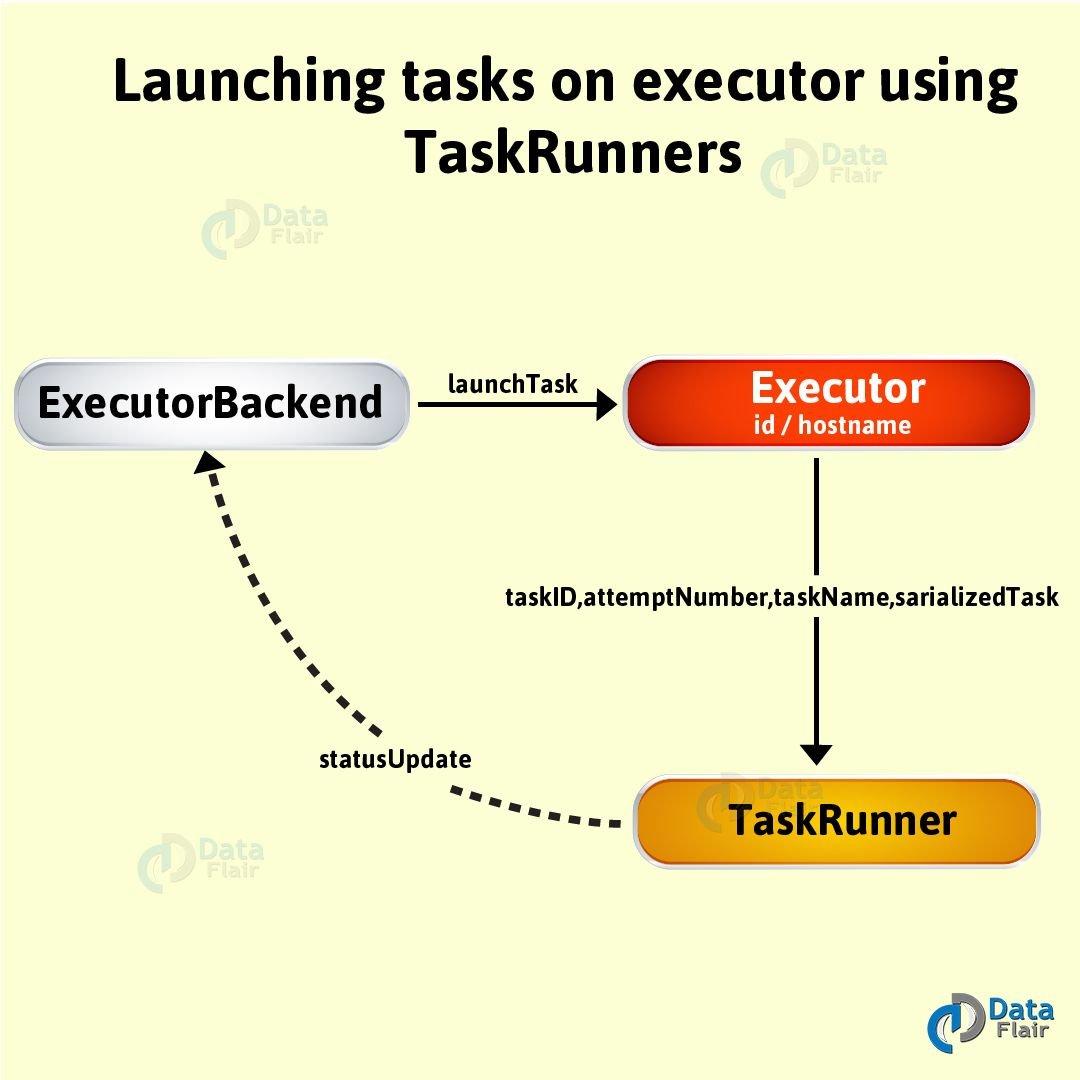
6. Launching Task — launchTask Method
By using this method, we execute the input serializedTask task concurrently.
Spark Executor- Launching Tasks on Executor Using TaskRunners
Let’s revise the Spark Machine Learning Algorithm
launchTask( context: ExecutorBackend, taskId: Long, attemptNumber: Int, taskName: String, serializedTask: ByteBuffer): Unit
Moreover, by using launchTask we use to create a TaskRunner, internally. Then, with the help of taskId, we register it in the runningTasks internal registry. Afterwards, we execute it on “Executor task launch worker” thread pool.
7. “Executor Task Launch Worker” Thread Pool — ThreadPool Property
Basically, To launch, by task launch worker id. It uses threadPool daemon cached thread pool. Moreover, at the same time of creation of Spark Executor, threadPool is created. Also, shuts it down when it stops.
You must read about Structured Streaming in SparkR
8. Conclusion
As a result, we have seen, the whole concept of Executors in Apache Spark. Moreover, we have also learned how Spark Executors are helpful for executing tasks. The major advantage we have learned is, we can have as many executors we want. Therefore, Executors helps to enhance the Spark performance of the system. We have covered each aspect about Apache Spark Executor above. However, if any query occurs feel free to ask in the comment section.
See also –
List of Best Apache Spark Books
For Reference
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





HOW TO CHOOSE Number of EXECUTOR and RAM MEMORY for better performance in SPARK?