Structured Streaming in SparkR – Example & Programming Model
1. Objective – SparkR Structured Streaming
Basically, SparkR supports Structured Streaming API. In this article, we will learn the whole concept of Structured Streaming in spark R. Moreover, we will also learn the programming model for Structured Streaming, to understand it better. Also, we will see an example of Structured Streaming in SparkR.
So, let’s start the Structured Streaming tutorial.

Structured Streaming in SparkR – Example & Programming Model
2. What is Structured Streaming in SparkR?
Basically, SparkR supports Structured Streaming API.
- It is built on the Spark SQL engine, which is scalable and fault-tolerant in nature.
- It helps to express streaming aggregations, event-time windows, stream-to-batch joins and many more.
- Here it executes computation on the same optimized Spark SQL engine.
Although, as same as we express a batch computation on static data. In the same way, we can express our streaming computation. We can use the Dataset/DataFrame API in Scala, Java, Python or R as well.
In addition, the system ensures end-to-end exactly-once. Also guarantees fault-tolerance through checkpointing and Write-Ahead Logs. Also, provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.
a. Example of Spark Structured Streaming in R
Structured Streaming in SparkR example. If we want to maintain a running word count of text data received from a data server listening on a TCP socket. We can express this using Structured Streaming and create a local SparkSession, the starting point of all functionalities related to Spark.
sparkR.session(appName = "StructuredNetworkWordCount") # Split the lines into words words <- selectExpr(lines, "explode(split(value, ' ')) as word") # Generate running word count wordCounts <- count(group_by(words, "word"))
3. Structure Streaming Programming Model In SparkR
In Structured Streaming, the key idea is to treat a live data stream as a table, that appends continuously. Basically, it leads to a new stream processing model. However, it is very similar to a batch processing model. Also, can express our streaming computation as a standard batch-like query as on a static table. Moreover, Spark runs it as an incremental query on the unbounded input table. Furthermore, let’s understand the detailed description of this model.
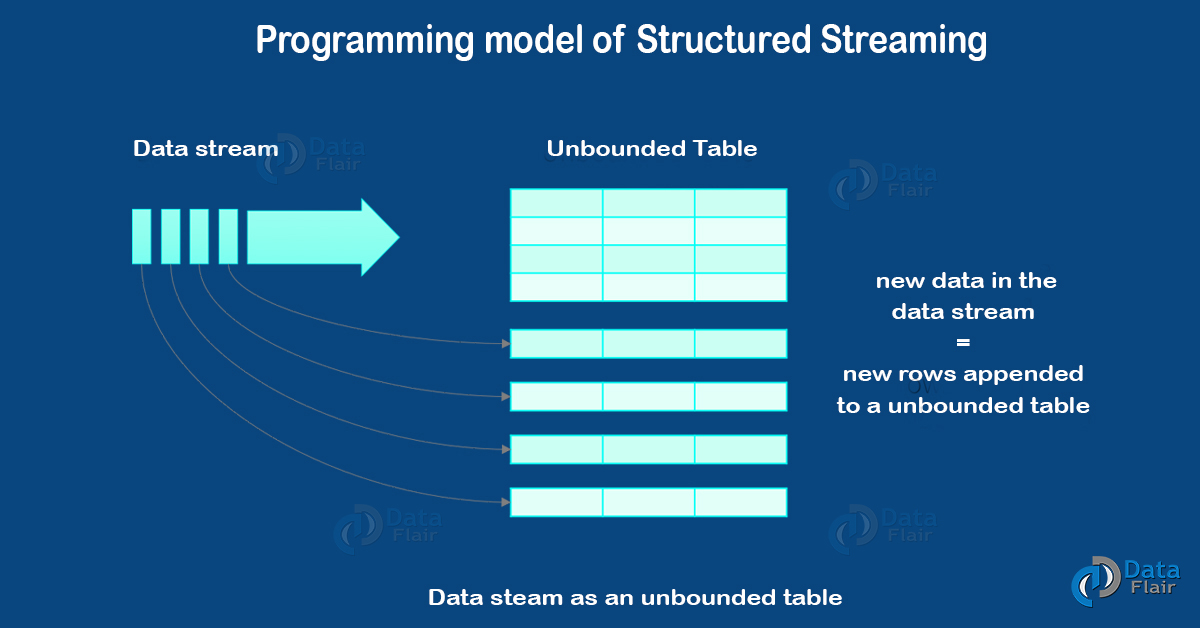
Programming Model Of Structure Streaming in SparkR
a. Basic Concepts Spark Structured Streaming
Let’s consider the input data stream as the “Input Table”. Although, every data item that is arriving on the stream is like a new row being appended to the input table.
b. Stream as a Table
Basically, a query on the input will generate the “Result Table”. Moreover, every trigger interval (say, every 1 second), new rows get appended to the input table. Hence, it eventually updates the result table. Although, the time when we update the result table, it leads us to write the changed result rows to an external sink.
c. Model of Structured Streaming
Basically, we can call an“Output” is what we get written out to the external storage. Although, we can define the output in different modes, for example, Complete Mode, Append Mode, Update Mode. Let’s discuss all in detail.
i. Complete Mode
When updated result table will be written to the external storage, that mode is Complete Mode. Although, it depends on the storage connector only. That decides how to handle the writing of the entire table.
ii. Append Mode
This is the mode where only the new rows appended to the result table since the last trigger. We will write those rows to the external storage. Basically, it is only applicable to the queries where existing rows in the result table are not expected to change.
iii. Update Mode
In this mode, only the rows that were updated in the result table since the last trigger will be written to the external storage. It is available since Spark 2.1.1. It is very important to note that this is different from the complete mode. This mode only outputs the rows that have changed since the last trigger. Moreover, we can say if the query doesn’t contain aggregations, it will be as same as Append mode.
In addition, it is significantly different from many other stream processing engines. Basically, the spark is responsible for updating the result table in this model.
So, this was all in SparkR Structure Streaming. Hope you like our explanation.
4. Conclusion – Structured Streaming
Hence, in this article, we have learned the whole concept of Structured Streaming in SparkR. Also, we have discussed the whole programming model of Structured Streaming in R. Although if any query occurs, feel free to ask in the comment section.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google




