Featurization in Apache Spark MLlib Algorithms
1. Objective
In this blog, we will learn a tool Featurization in Apache Spark MLlib. We will also learn spark Machine Learning Algorithms to understand well.

Apache Spark Machine Learning – Featurization
2. Featurization in Apache Spark MLlib
Apache Spark MLlib includes algorithms for working with Spark features. Moreover, it divided into these groups:
- Extraction: Extracting features from “raw” data.
- Transformation: Scaling, converting, or modifying features.
- Selection: Selecting a subset of a larger set of features.
- Locality Sensitive Hashing (LSH): This class of algorithms combines aspects of feature transformation with other algorithms.
Let’s learn all Apache Spark MLlib Featurization in detail:
a. Extraction in Featurization of Apache Spark MLlib
Here, we have 3 types of MLlib in Apache Spark Extractions:
i. TF-IDF
There is a feature vectorization method widely used in text mining to reflect the importance of a term to a document in the corpus. That is what we call a Term Frequency-Inverse Document Frequency (TF-IDF). Here we are denoting a term by t, also a document by d, whereas the corpus by D. Moreover, Term frequency TF(t,d) is the number of times that term t appears in document d. While document frequency DF(t, D)DF(t, D) is the number of documents that contain term t.
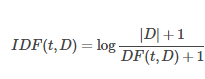
Extraction in Featurization of Apache Spark MLlib
ii. Word2Vec
An estimator that takes sequences of words representing documents and trains a Word2VecModel is Word2Vec. It is the model that maps each word to a unique fixed-size vector. Moreover, Word2VecModel helps to transform each document into a vector using the average of all words in the document. Afterward, this vector can then be used as features for prediction, document similarity calculations and many more.
Have a look at Spark RDD
iii. CountVectorizer
To convert a collection of text documents to vectors of token counts, we use CountVectorizer and CountVectorizerModel. We can use CountVectorizer as an estimator to extract the vocabulary when an a-priori dictionary is not available. Also generates a CountVectorizerModel. In addition, this model produces sparse representations for the documents over the vocabulary. Also, that can be passed to other algorithms like LDA.
b. Feature Transformers in Featurization of Apache Spark MLlib
i. Tokenizer
The process of taking the text (such as a sentence) and breaking it into individual terms (usually words), is known as Tokenization. Although, it is a functionality which is offered by a simple Tokenizer class.
ii. StopWordsRemover
There are some words which are Stop words. It is a compulsion that these words should be excluded from the input. Since the words appear frequently. Also, don’t carry as much meaning.
iii. n-gram
A sequence of n tokens (typically words) for some integer n is an n-gram. Moreover, we use N-Gram class to transform input features into n-grams.
iv. Binarizer
The process of thresholding numerical features to binary (0/1) features, is Binarization.
Do you know about Structured Streaming in SparkR
Basically, it takes the common parameters. Such as inputCol, outputCol, and the threshold for binarization. Moreover, the feature values greater than the threshold are binarized to 1.0. Whereas, values equal to or less than the threshold are binarized to 0.0. Although, inputCol support both vector and double types.
v. PCA
Basically, it is a statistical procedure. It uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables, that is called as principal components. Moreover, it trains a model to project vectors to a low-dimensional space.
vi. PolynomialExpansion
Basically, a process of expanding features into a polynomial space is Polynomial expansion. In addition, it is formulated by an n-degree combination of original dimensions. Moreover, a Polynomial expansion class offers this functionality.
vii. StringIndexer
Basically, StringIndexer encodes a string column of labels to a column of label indices. Moreover, the indices are in [0, numLabels), ordered by label frequencies. Hence, the most frequent label gets index 0.
viii. IndexToString
As same as StringIndexer, it also maps a column of label indices back to a column containing the original labels as strings.
ix. OneHotEncoder
Basically, it maps a column of label indices to a column of binary vectors, with at most a single one-value. Moreover, this encoding allows algorithms. That expect continuous features, such as Logistic Regression, to use categorical features.
x. VectorIndexer
In datasets of vectors, VectorIndexer helps index categorical features. Basically, it can both automatically decide which features are categorical. Also, converts original values to category indices. More specifically, it does all this following:
Have a look at data type mapping between R and Spark
- It takes an input column of type vector and a parameter maxCategories.
- Basically, it decides which features should be categorical. On the basis of the number of distinct values, where features with at most maxCategories are declared categorical.
- Also, compute 0-based category indices for each categorical feature.
- Moreover, index categorical features and transforms original feature values to indices.
xi. Interaction
It is a type of transformer that takes vector or double-valued columns. Afterwards generates a single vector column. Basically, that contains the product of all combinations of one value from each input column.
xii. Normalizer
It is a type of transformer that transforms a dataset of vector rows, normalizing each vector to have unit norm. Basically, it takes parameter p, that specifies the p-norm used for normalization.
xiii. StandardScaler
Basically, StandardScaler transforms a dataset of vector rows. Also, normalizes each feature to have unit standard deviation and/or zero mean.
xiv. withStd
It is true by default. Moreover, it Scales the data to a unit standard deviation.
xv. withMean
It is false by default. Basically, it centers the data with mean before scaling. Also builds a dense output, so take care when applying to sparse input.
xvi. MinMaxScaler
Basically, it transforms a dataset of vector rows. Also, rescales each feature to a specific range (often [0, 1]). It takes parameters:

MinMaxScaler
- Min
It takes 0.0 by default. Lower bound after transformation, shared by all features.
- max
Featurization It takes 1.0 by default. Upper bound after transformation, shared by all features.
xvii. MaxAbsScaler
It transforms a dataset of vector rows. Also, rescales each feature to the range [-1, 1] by dividing by the maximum absolute value in each feature. Moreover, it does not shift/center the data. Therefore, it does not destroy any sparsity.
Let’s revise Spark machine Learning with R
xviii. Bucketizer
Basically, it transforms a column of continuous features to a column of feature buckets. However, the buckets are specified by users.
xix. ElementwiseProduct
By using element-wise multiplication, it multiplies each input vector by a provided “weight” vector. Also, we can define it as it scales each column of the dataset by a scalar multiplier. Moreover, this shows the Hadamard product between the input vector, v and transforming vector, w. Thus it yields a result vector.
xx. SQLTransformer
Basically, it implements the transformations those are defined by SQL statement. Although, recently we only support SQL syntax like “SELECT … FROM __THIS__ …” where “__THIS__”.
xxi. VectorAssembler
It is also a transformer. Basically, it combines a given list of columns into a single vector column. Although, it is useful for combining raw features. Also with features generated by different feature transformers into a single feature vector.
xxii. Imputer
Basically, the Imputer transformer completes missing values in a dataset. Either using the mean or the median of the columns in which the missing values are located. Moreover, the input columns should be of DoubleType or FloatType.
c. Feature Selectors in Featurization Apache Spark MLlib
i. VectorSlicer
It is nothing but a transformer, that takes a feature vector and outputs a new feature vector. Even with a sub-array of the original features. Moreover, it is beneficial for extracting features from a vector column.
Have a look at Spark RDD features
In addition, VectorSlicer accepts a vector column with specified indices. Afterwards, it outputs a new vector column. Basically, whose values are selected via those indices. Moreover, we have two types of indices, such as:
- Integer indices
It represents the indices into the vector, setIndices().
- String indices
It represents the names of features in the vector, setNames(). Also, requires the vector column to have an AttributeGroup. Since the implementation matches on the name field of an Attribute.
ii. RFormula
By an R model formula, RFormula selects columns. Basically, we support a limited subset of the R operators. It includes ‘~’, ‘.’, ‘:’, ‘+’, and ‘-‘. Let’s discuss all the basic operators:
1. ~ separate target and terms
2. + concat terms, “+ 0” means removing intercept
3. – remove a term, “- 1” means removing intercept
4. : interaction (multiplication for numeric values, or binarized categorical values)
5. . all columns except the target
iii. ChiSqSelector
ChiSqSelector refers to Chi-Squared feature selection. Basically, it operates on labeled data with categorical features. Moreover, it uses the Chi-Squared test of independence to decide which features to choose. Also supports five selection methods, such as numTopFeatures, percentile, fpr, fdr, fwe. Lets discuss all one by one:
Do you know about Spark SQL Optimization
- numTopFeatures –
It chooses a fixed number of top features according to a chi-squared test. This is akin to yielding the features with the most predictive power.
- percentile
It is similar to numTopFeatures but chooses a fraction of all features instead of a fixed number.
- fpr
It chooses all features whose p-values are below a threshold, thus controlling the false positive rate of selection.
- fdr
It uses the Benjamini-Hochberg procedure to choose all features whose false discovery rate is below a threshold.
- fwe
It chooses all features whose p-values are below a threshold.
d. Locality Sensitive Hashing in Featurization in Apache Spark MLlib
An important class of hashing techniques is Locality Sensitive Hashing (LSH). Basically, we use it in following. Such as clustering, approximate nearest neighbor search and outlier detection with large datasets.
i. LSH Operations
LSH can be used for the major types of operations. Basically, for each of these operations, a fitted LSH model has methods.
Feature Transformation
To add hashed values as a new column it is the basic functionality. Moreover, it is very useful for dimensionality reduction. Also, by setting inputCol and outputCol, users can specify input and output column names.
Test yourself with Spark Quiz
Approximate Similarity Join
Basically, it takes two datasets and approximately returns pairs of rows in the datasets whose distance is smaller than a user-defined threshold. Also, supports both joining two different datasets and self-joining. Moreover, self-joining will produce some duplicate pairs also.
Approximate Nearest Neighbor Search
Basically, it takes a dataset and a key then returns a specified number of rows in the dataset that are closest to the vector.
ii. LSH Algorithms
Bucketed Random Projection for Euclidean Distance
For Euclidean distance, Bucketed Random Projection is an LSH family. We can define Euclidean distance as follows:
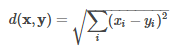
Bucketed Random Projection for Euclidean Distanc
MinHash for Jaccard Distance
For Jaccard distance, MinHash is an LSH family. Where input features are sets of natural numbers. Moreover, Jaccard distance of two sets is the cardinality of their intersection & union
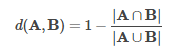
MinHash for Jaccard Distance
Basically, MinHash applies a random hash function g to each element in the set. Also take the minimum of all hashed values:
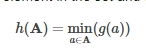
LSH Algorithms
3. Conclusion
As a result, we have seen all Featurization methods in Apache Spark MLlib. However, if any query occurs, please ask in the comment section. We will definitely get back to You.
For reference
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google




