RDD lineage in Spark: ToDebugString Method
1. Objective
Basically, in Spark all the dependencies between the RDDs will be logged in a graph, despite the actual data. This is what we call as a lineage graph in Spark. This document holds the concept of RDD lineage in Spark logical execution plan. Moreover, we will get to know that how to get RDD Lineage Graph by the toDebugString method in detail. Before all, let’s also learn about Spark RDDs.

Introduction to Spark RDD Lineage
2. Introduction to Spark RDD
Spark RDD is nothing but an acronym for “Resilient Distributed Dataset”. We can consider RDD as a fundamental data structure of Apache Spark. To be very specific, RDD is an immutable collection of objects in Apache Spark. That helps to compute on the different node of the cluster.
On decomposing the name of Spark RDD:
- Resilient
This means fault-tolerant. By using RDD lineage graph(DAG), we can recompute missing or damaged partitions due to node failures.
- Distributed
It means data resides on multiple nodes.
- Dataset
It is nothing but a record of the data you work with. Also, a user can load the dataset externally. For example, JSON file, CSV file, text file or database via JDBC with no specific data structure.
You must read the Spark dataSet Tutorial
3. Introduction to RDD Lineage
Basically, evaluation of RDD is lazy in nature. It means a series of transformations are performed on an RDD, which is not even evaluated immediately.
While we create a new RDD from an existing Spark RDD, that new RDD also carries a pointer to the parent RDD in Spark. That is the same as all the dependencies between the RDDs those are logged in a graph, rather than the actual data. It is what we call as lineage graph.
RDD lineage is nothing but the graph of all the parent RDDs of an RDD. We also call it an RDD operator graph or RDD dependency graph. To be very specific, it is an output of applying transformations to the spark. Then, it creates a logical execution plan.
Also, physical execution plan or execution DAG is known as DAG of stages.
Let’s start with one example of Spark RDD lineage by using Cartesian or zip to understand well. However, we can also use other operators to build an RDD graph in Spark.
For example
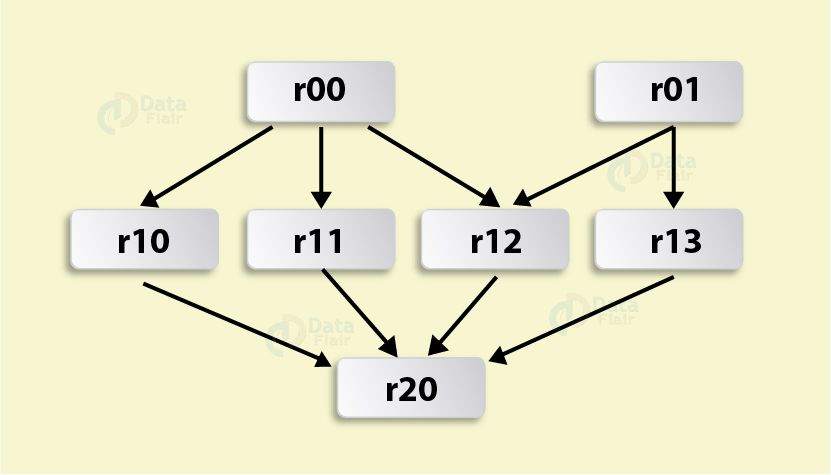
Introduction to RDD lineage in Apache Spark
Above figure depicts an RDD graph, which is the result of the following series of transformations:
Let us revise Lazy evaluation in Spark
val r00 = sc.parallelize(0 to 9)
val r01 = sc.parallelize(0 to 90 by 10)
val r10 = r00 cartesian df01
val r11 = r00.map(n => (n, n))
val r12 = r00 zip df01
val r13 = r01.keyBy(_ / 20)
val r20 = Seq(r11, r12, r13).foldLeft(r10)(_ union _)
After an action has been called, this is a graph of what transformations need to be executed.
In other words, whenever on the basis of the existing RDDs we create new RDDs, using lineage graph spark manage these dependencies. Basically, along with metadata about what type of relationship it has with the parent RDD, each RDD maintains a pointer to one or more parent.
For example,
if we say, on an
RDD val b=a.map().
Hence, RDD b keeps a reference to its parent RDD a. That is a sort of an RDD lineage.
4. Logical Execution Plan for RDD Lineage
Basically, logical execution plan gets initiated with earliest RDDs. Earliest RDDs are nothing but RDDs which are not dependent on other RDDs. To be very specific those are independent of reference cached data. Moreover, it ends with the RDD those produces the result of the action which has been called to execute.
We can also say, it is a DAG that is executed when SparkContext is requested to run a Spark job.
5. ToDebugString Method to get RDD Lineage Graph in Spark
Although there are several methods to get RDD lineage graph in spark, one of the methods is toDebugString method. Such as,
toDebugString: String
Have a look at Spark DStream
Basically, we can learn about an Spark RDD lineage graph with the help of this method.
scala> val wordCount1 = sc.textFile(“README.md”).flatMap(_.split(“\\s+”)).map((_, 1)).reduceByKey(_ + _)
wordCount1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[21] at reduceByKey at <console>:24
scala> wordCount1.toDebugString
res13: String =
(2) ShuffledRDD[21] at reduceByKey at <console>:24 []
+-(2) MapPartitionsRDD[20] at map at <console>:24 []
| MapPartitionsRDD[19] at flatMap at <console>:24 []
| README.md MapPartitionsRDD[18] at textFile at <console>:24 []
| README.md HadoopRDD[17] at textFile at <console>:24 []
Here for indication of shuffle boundary, this method “ toDebugString method” uses indentations.
Basically, here H in round brackets refers, numbers that show the level of parallelism at each stage.
For example, (2) in the above output.
scala> wordCount1.getNumPartitions
res14: Int = 2
The toDebugString method is included when executing an action, With spark.logLineage property enabled.
$ ./bin/spark-shell –conf spark.logLineage=true
scala> sc.textFile(“README.md”, 4).count
…
15/10/17 14:46:42 INFO SparkContext: Starting job: count at <console>:25
15/10/17 14:46:42 INFO SparkContext: RDD’s recursive dependencies:
(4) MapPartitionsRDD[1] at textFile at <console>:25 []
| README.md HadoopRDD[0] at textFile at <console>:25 []
You must read about Spark Performance Tuning
So, this was all about Spark RDD Lineage Tutorial. Hope you like our explanation.
6. Conclusion
Hence, by this blog, we have learned the actual meaning of Apache Spark RDD lineage graph. Moreover, also we have tasted the flavor of the logical execution plan in Apache Spark. However, we have also seen toDebugString method in detail. Therefore, we have covered all the concept of lineage graph in Apache Spark RDD.
Furthermore, if you have any query, please ask in the comment section.
Refer top books to learn Spark.
For reference
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





In “For example” I think is a discrepancy between picture and example: in picture isnot present: df01
what does this mean -flatMap(_.split(“\\s+”))
\\s+ – matches sequence of one or more whitespace characters.
above function will split the file content on the basis of whitespace characters
what is difference between DAG and Lineage