Fault tolerance in Apache Spark – Reliable Spark Streaming
1. Objective
In this Spark fault tolerance tutorial, we will learn what do you mean by fault tolerance and how Apache Spark handles fault tolerance. We will see fault-tolerant stream processing with Spark Streaming and Spark RDD fault tolerance. We will also learn what is Spark Streaming write ahead log, Spark streaming driver failure, Spark streaming worker failure to understand how to achieve fault tolerance in Apache Spark.
Fault tolerance in Apache Spark – Reliable Spark Streaming
2. Introduction to Fault Tolerance in Apache Spark
Before we start with learning what is fault tolerance in Apache Spark, let us revise concepts of Apache Spark for beginners.
Now let’s understand what is fault and how Spark handles fault tolerance.
Fault refers to failure, thus fault tolerance in Apache Spark is the capability to operate and to recover loss after a failure occurs. If we want our system to be fault tolerant, it should be redundant because we require a redundant component to obtain the lost data. The faulty data recovers by redundant data.
3. Spark RDD Fault Tolerance
Let us firstly see how to create RDDs in Spark? Spark operates on data in fault-tolerant file systems like HDFS or S3. So all the RDDs generated from fault tolerant data is fault tolerant. But this does not set true for streaming/live data (data over the network). So the key need of fault tolerance in Spark is for this kind of data. The basic fault-tolerant semantic of Spark are:
- Since Apache Spark RDD is an immutable dataset, each Spark RDD remembers the lineage of the deterministic operation that was used on fault-tolerant input dataset to create it.
- If due to a worker node failure any partition of an RDD is lost, then that partition can be re-computed from the original fault-tolerant dataset using the lineage of operations.
- Assuming that all of the RDD transformations are deterministic, the data in the final transformed RDD will always be the same irrespective of failures in the Spark cluster.
To achieve fault tolerance for all the generated RDDs, the achieved data replicates among multiple Spark executors in worker nodes in the cluster. This results in two types of data that needs to recover in the event of failure:
- Data received and replicated – In this, the data gets replicated on one of the other nodes thus the data can be retrieved when a failure.
- Data received but buffered for replication – The data is not replicated thus the only way to recover fault is by retrieving it again from the source.
Fault tolerance in Apache Spark – Reliable Spark Streaming
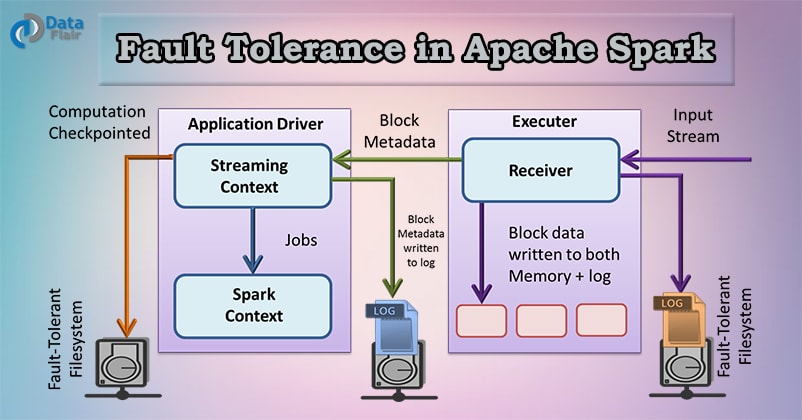
Failure also occurs in worker as well as driver nodes.
- Failure of worker node – The node which runs the application code on the Spark cluster is Spark worker node. These are the slave nodes. Any of the worker nodes running executor can fail, thus resulting in loss of in-memory If any receivers were running on failed nodes, then their buffer data will be lost.
- Failure of driver node – If there is a failure of the driver node that is running the Spark Streaming application, then SparkContent losses and all executors lose their in-memory data.
Apache Mesos helps in making the Spark master fault tolerant by maintaining the backup masters. It is open source software residing between the application layer and the operating system. It makes easier to deploy and manage applications in large-scale clustered environment. Executors are relaunched if they fail. Post failure, executors are relaunched automatically and spark streaming does parallel recovery by recomputing Spark RDD’s on input data. Receivers are restarted by the workers when they fail.
4. Fault Tolerance with Receiver-based sources
For input sources based on receivers, the fault tolerance depends on both- the failure scenario and the type of receiver. There are two types of receiver:
- Reliable receiver – Once we ensure that the received data replicates, the reliable sources are acknowledged. If the receiver fails, the source will not receive acknowledgment for the buffered data. So, the next time restarts the receiver, the source will resend the data. Hence, no data will lose due to failure.
- Unreliable Receiver – Due to the worker or driver failure, the data can loss sincethe receiver does not send an acknowledgment.
If the worker node fails, and the receiver is reliable there will be no data loss. But in the case of unreliable receiver data loss will occur. With the unreliable receiver, data received but not replicated can be lost.
5. Spark Streaming write ahead logs
If the driver node fails, all the data that was received and replicated in memory will be lost. This will affect the result of the stateful transformation. To avoid the loss of data, Spark 1.2 introduced write ahead logs, which save received data to fault-tolerant storage. All the data received is written to write ahead logs before it can be processed to Spark Streaming.
Write ahead logs are used in database and file system. It ensure the durability of any data operations. It works in the way that first the intention of the operation is written down in the durable log. After this, the operation is applied to the data. This is done because if the system fails in the middle of applying the operation, the lost data can be recovered. It is done by reading the log and reapplying the data it has intended to do.
| Deployment Scenario | Worker Failure | Driver Failure |
| Spark 1.1 or earlier | Buffered data lost with unreliable receivers | Buffered data lost with the unreliable receiver. |
| Spark 1.2 or later without write ahead logs | Zero data loss with reliable receivers, At-least-once semantics | Past data lost with all receivers, Undefined semantics |
| Spark 1.2 or later with write ahead logs | Zero data loss with reliable receivers, At-least-once semantics | Zero data loss with reliable receivers and files, At-least-once semantics |
6. High Availability
We can say any system highly available if its downtime is tolerable. This time depends on how critical the application is. Zero down time is an imaginary term for any system. Consider any machine has an uptime of 97.7%, so its probability to go down will be 0.023. If we have similar two machines, then the probability of both of them going down will be (0.023*0.023). in most high availability environment we have three machines in use, in that case, the probability of going down is (0.023*0.023*0.023) i.e. 0.000012167, which guarantees an uptime of system to be 99.9987833% which is highly acceptable uptime guarantee. 6. Apache Spark High Availability
7. Conclusion
Hence we have studied Fault Tolerance in Apache Spark. I hope this blog helps you a lot to understand How Apache Spark is Fault Tolerant Framework. if Still you have doubt related to Fault Tolerance in Apache Spark, so leave a comment in a section given below.
See Also-
Your opinion matters
Please write your valuable feedback about DataFlair on Google





in “Failure of driver node” :spark content is lost has written –is n’t it “SparkContext” or “SparkContent” ?
yes Devendra. It is ‘Spark Context’. Must be a typo mistake.
Hello Avinash,
Thank you for answering on this “Spark Fault tolerance”. We appreciate, your observation.
Hi Devendra,
Thanks for Commenting on “Fault Tolerance in Spark”. We must say, you have such a good observation.
Yes it is SparkContext only, it is just a typing mistake. We have corrected it in the article.
Hope it helps!
Keep Visting Data-Flair.
can you tel me diagrammatically
Hello, Abhi,
Glad you like our Spark Tutorial. We hope this tutorial helps you to learn Spark.
SOON we will Update our Content Considering your Feedback.
Thank You for sharing your Opinion.
Regards,
Data-Flair
HI Team,
In case of worker node and Driver failure, how data gets recovered?