Apache Spark RDD vs DataFrame vs DataSet
1. Objective
This Spark tutorial will provide you the detailed feature wise comparison between Apache Spark RDD vs DataFrame vs DataSet. We will cover the brief introduction of Spark APIs i.e. RDD, DataFrame and Dataset, Differences between these Spark API based on various features. For example, Data Representation, Immutability, and Interoperability etc. We will also illustrate, where to use RDD, DataFrame API, and Dataset API of Spark.
Learn easy steps to Install Apache Spark on the single node and on Multi-node cluster.
Apache Spark RDD vs DataFrame vs DataSet
2. Apache Spark APIs – RDD, DataFrame, and DataSet
Before starting the comparison between Spark RDD vs DataFrame vs Dataset, let us see RDDs, DataFrame and Datasets in Spark:
- Spark RDD APIs – An RDD stands for Resilient Distributed Datasets. It is Read-only partition collection of records. RDD is the fundamental data structure of Spark. It allows a programmer to perform in-memory computations on large clusters in a fault-tolerant manner. Thus, speed up the task. Follow this link to learn Spark RDD in great detail.
- Spark Dataframe APIs – Unlike an RDD, data organized into named columns. For example a table in a relational database. It is an immutable distributed collection of data. DataFrame in Spark allows developers to impose a structure onto a distributed collection of data, allowing higher-level abstraction. Follow this link to learn Spark DataFrame in detail.
- Spark Dataset APIs – Datasets in Apache Spark are an extension of DataFrame API which provides type-safe, object-oriented programming interface. Dataset takes advantage of Spark’s Catalyst optimizer by exposing expressions and data fields to a query planner. Follow this link to learn Spark DataSet in detail.
3. RDD vs Dataframe vs DataSet in Apache Spark
Let us now learn the feature wise difference between RDD vs DataFrame vs DataSet API in Spark:
3.1. Spark Release
- RDD – The RDD APIs have been on Spark since the 1.0 release.
- DataFrames – Spark introduced DataFrames in Spark 1.3 release.
- DataSet – Spark introduced Dataset in Spark 1.6 release.
3.2. Data Representation
- RDD – RDD is a distributed collection of data elements spread across many machines in the cluster. RDDs are a set of Java or Scala objects representing data.
- DataFrame – A DataFrame is a distributed collection of data organized into named columns. It is conceptually equal to a table in a relational database.
- DataSet – It is an extension of DataFrame API that provides the functionality of – type-safe, object-oriented programming interface of the RDD API and performance benefits of the Catalyst query optimizer and off heap storage mechanism of a DataFrame API.
3.3. Data Formats
- RDD – It can easily and efficiently process data which is structured as well as unstructured. But like Dataframe and DataSets, RDD does not infer the schema of the ingested data and requires the user to specify it.
- DataFrame – It works only on structured and semi-structured data. It organizes the data in the named column. DataFrames allow the Spark to manage schema.
- DataSet – It also efficiently processes structured and unstructured data. It represents data in the form of JVM objects of row or a collection of row object. Which is represented in tabular forms through encoders.
3.4. Data Sources API
- RDD – Data source API allows that an RDD could come from any data source e.g. text file, a
database via JDBC etc. and easily handle data with no predefined structure. - DataFrame – Data source API allows Data processing in different formats (AVRO, CSV, JSON, and storage system HDFS, HIVE tables, MySQL). It can read and write from various data sources that are mentioned above.
- DataSet – Dataset API of spark also support data from different sources.
3.5. Immutability and Interoperability
- RDD – RDDs contains the collection of records which are partitioned. The basic unit of parallelism in an RDD is called partition. Each partition is one logical division of data which is immutable and created through some transformation on existing partitions. Immutability helps to achieve consistency in computations. We can move from RDD to DataFrame (If RDD is in tabular format) by toDF() method or we can do the reverse by the .rdd method. Learn various RDD Transformations and Actions APIs with examples.
- DataFrame – After transforming into DataFrame one cannot regenerate a domain object. For example, if you generate testDF from testRDD, then you won’t be able to recover the original RDD of the test class.
- DataSet – It overcomes the limitation of DataFrame to regenerate the RDD from Dataframe.
Datasets allow you to convert your existing RDD and DataFrames into Datasets.
3.6. Compile-time type safety
- RDD – RDD provides a familiar object-oriented programming style with compile-time type safety.
- DataFrame – If you are trying to access the column which does not exist in the table in such case Dataframe APIs does not support compile-time error. It detects attribute error only at runtime.
- DataSet – It provides compile-time type safety.
Learn: Apache Spark vs. Hadoop MapReduce
3.7. Optimization
- RDD – No inbuilt optimization engine is available in RDD. When working with structured data, RDDs cannot take advantages of sparks advance optimizers. For example, catalyst optimizer and Tungsten execution engine. Developers optimise each RDD on the basis of its attributes.
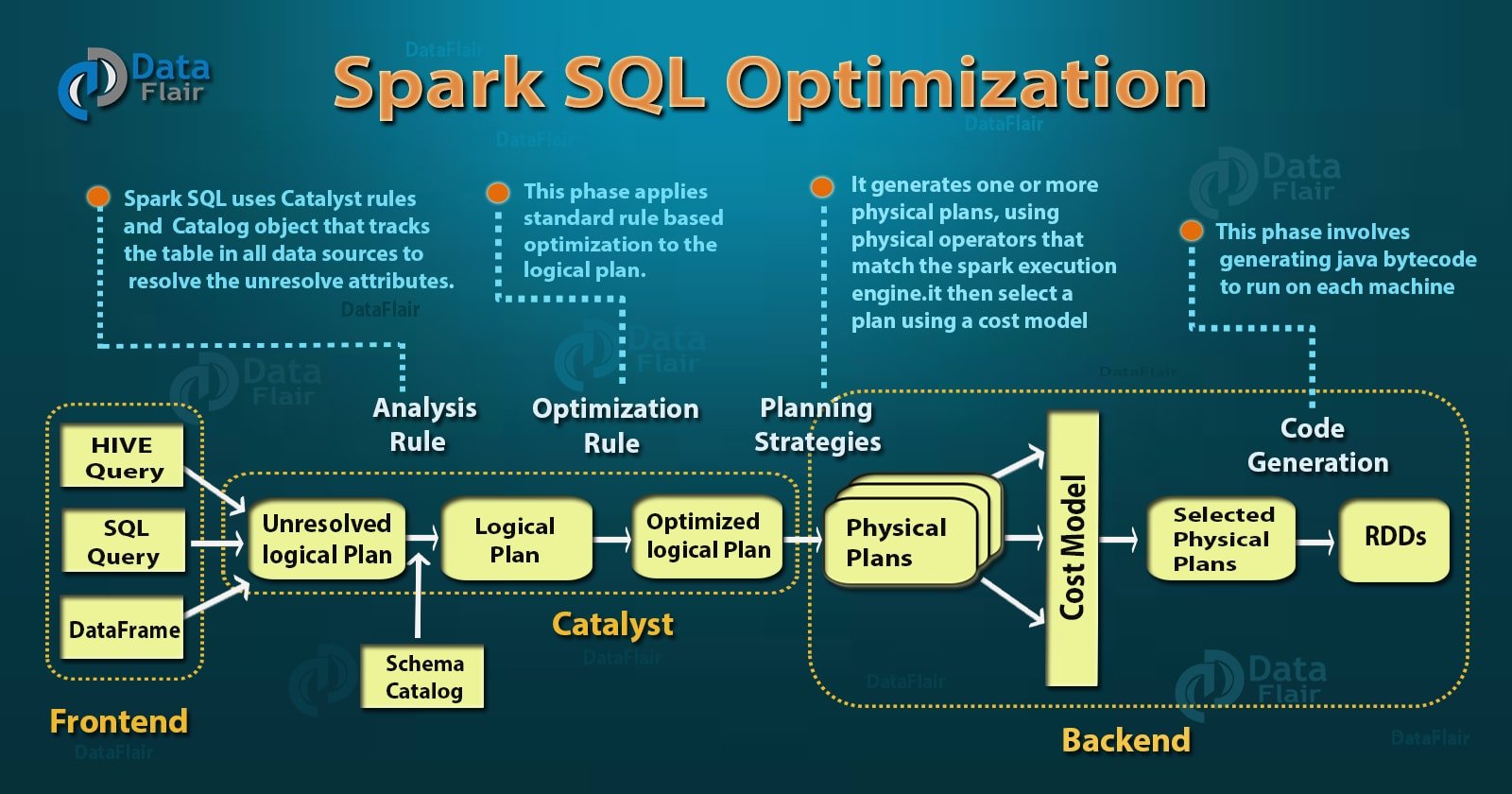
- DataFrame – Optimization takes place using catalyst optimizer. Dataframes use catalyst tree transformation framework in four phases: a) Analyzing a logical plan to resolve references. b) Logical plan optimization. c) Physical planning. d) Code generation to compile parts of the query to Java bytecode. The brief overview of optimization phase is also given in the below figure:
Spark-SQL-Optimization
- Dataset – It includes the concept of Dataframe Catalyst optimizer for optimizing query plan.
3.8. Serialization
- RDD – Whenever Spark needs to distribute the data within the cluster or write the data to disk, it does so use Java serialization. The overhead of serializing individual Java and Scala objects is expensive and requires sending both data and structure between nodes.
- DataFrame – Spark DataFrame Can serialize the data into off-heap storage (in memory) in binary format and then perform many transformations directly on this off heap memory because spark understands the schema. There is no need to use java serialization to encode the data. It provides a Tungsten physical execution backend which explicitly manages memory and dynamically generates bytecode for expression evaluation.
- DataSet – When it comes to serializing data, the Dataset API in Spark has the concept of an encoder which handles conversion between JVM objects to tabular representation. It stores tabular representation using spark internal Tungsten binary format. Dataset allows performing the operation on serialized data and improving memory use. It allows on-demand access to individual attribute without desterilizing the entire object.
3.9. Garbage Collection
- RDD – There is overhead for garbage collection that results from creating and destroying individual objects.
- DataFrame – Avoids the garbage collection costs in constructing individual objects for each row in the dataset.
- DataSet – There is also no need for the garbage collector to destroy object because serialization
takes place through Tungsten. That uses off heap data serialization.
Learn: Apache Spark Terminologies and Concepts You Must Know
3.10. Efficiency/Memory use
- RDD – Efficiency is decreased when serialization is performed individually on a java and scala object which takes lots of time.
- DataFrame – Use of off heap memory for serialization reduces the overhead. It generates byte code dynamically so that many operations can be performed on that serialized data. No need for deserialization for small operations.
- DataSet – It allows performing an operation on serialized data and improving memory use. Thus it allows on-demand access to individual attribute without deserializing the entire object.
3.11. Lazy Evolution
- RDD – Spark evaluates RDDs lazily. They do not compute their result right away. Instead, they just remember the transformation applied to some base data set. Spark compute Transformations only when an action needs a result to sent to the driver program. Refer this guide if you are new to the Lazy Evaluation feature of Spark.

Apache Spark Lazy Evaluation Feature.
- DataFrame – Spark evaluates DataFrame lazily, that means computation happens only when action appears (like display result, save output).
- DataSet – It also evaluates lazily as RDD and Dataset.
3.12. Programming Language Support
- RDD – RDD APIs are available in Java, Scala, Python, and R languages. Hence, this feature provides flexibility to the developers.
- DataFrame – It also has APIs in the different languages like Java, Python, Scala, and R.
- DataSet – Dataset APIs is currently only available in Scala and Java. Spark version 2.1.1 does not support Python and R.
Get the Best Books of Scala and R to become a master.
3.13. Schema Projection
- RDD – In RDD APIs use schema projection is used explicitly. Hence, we need to define the schema (manually).
- DataFrame – Auto-discovering the schema from the files and exposing them as tables through the Hive Meta store. We did this to connect standard SQL clients to our engine. And explore our dataset without defining the schema of our files.
- DataSet – Auto discover the schema of the files because of using Spark SQL engine.
3.14. Aggregation
- RDD – RDD API is slower to perform simple grouping and aggregation operations.
- DataFrame – DataFrame API is very easy to use. It is faster for exploratory analysis, creating aggregated statistics on large data sets.
- DataSet – In Dataset it is faster to perform aggregation operation on plenty of data sets.
Learn: Spark Shell Commands to Interact with Spark-Scala
3.15. Usage Area
RDD-
- You can use RDDs When you want low-level transformation and actions on your data set.
- Use RDDs When you need high-level abstractions.
DataFrame and DataSet-
- One can use both DataFrame and dataset API when we need a high level of abstraction.
- For unstructured data, such as media streams or streams of text.
- You can use both Data Frames or Dataset when you need domain specific APIs.
- When you want to manipulate your data with functional programming constructs than domain specific expression.
- We can use either datasets or DataFrame in the high-level expression. For example, filter, maps, aggregation, sum, SQL queries, and columnar access.
- When you do not care about imposing a schema, such as columnar format while processing or accessing data attributes by name or column.
- in addition, If we want a higher degree of type safety at compile time.
4. Conclusion
Hence, from the comparison between RDD vs DataFrame vs Dataset, it is clear when to use RDD or DataFrame and/or Dataset.
As a result, RDD offers low-level functionality and control. The DataFrame and Dataset allow custom view and structure. It offers high-level domain-specific operations, saves space, and executes at high speed. Select one out of DataFrames and/or Dataset or RDDs APIs, that meets your needs and play with Spark.
If you like this post about RDD vs Dataframe vs DataSet so do let me know by leaving a comment.
See also –
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





First thank you for these informations.
Can you please correct the paragraph “Usage Area”:
When to use RDDs?
Consider these scenarios or common use cases for using RDDs when:
– you want low-level transformation and actions and control on your dataset;
– your data is unstructured, such as media streams or streams of text;
– you want to manipulate your data with functional programming constructs than domain
specific expressions;
– you don’t care about imposing a schema, such as columnar format, while processing or accessing data attributes by name or column; and
– you can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
When should I use DataFrames or Datasets?
– If you want rich semantics, high-level abstractions, and domain specific APIs, use DataFrame or Dataset.
– If your processing demands high-level expressions, filters, maps, aggregation, averages, sum, SQL queries, columnar access and use of lambda functions on semi-structured data, use DataFrame or Dataset.
– If you want higher degree of type-safety at compile time, want typed JVM objects, take advantage of Catalyst optimization, and benefit from Tungsten’s efficient code generation, use Dataset.
– If you want unification and simplification of APIs across Spark Libraries, use DataFrame or Dataset.
– If you are a R user, use DataFrames.
– If you are a Python user, use DataFrames and resort back to RDDs if you need more control.
Source: https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
It’s a good article which describes the difference between RDD, Dataframe and Dataset .
Hello, Shashi
Thank you so much for taking the time to write us a feedback on “Spark RDD vs DataFrame vs DataSet” and making our day!
Every feedback helps us to motivate and improve our content day by day.
Regard,
Data-Flair
Hi
Perfect article which shows the differences between all these three things. I loved it
Thank you
Thank you for Appreciating our “Apache Spark RDD vs DataFrame vs DataSet”, your compliment has greatly elevated our spirit. We hope this Spark Tutorial, helps you for Career in Spark.
Regards,
Data-Flair
Very comprehensive article! A lucid explanation!
Thank you for such kind words, we hope you explore our Spark Tutorial and learn Apache Spark. You can refer to our Spark Quiz
to check your Spark Knowledge.
Regards,
Data-Flair
Explanation is really very good. I really appreciate for your efforts. Thank you!!!!
Hi Ajay,
It’s our pleasure that you liked our work on “Spark RDD vs DataFrame vs DataSet” Tutorial. We are glad that you taking the time to share your experience with us.
We refer you to visit more Spark Tutorials, to brush up your Spark knowledge or you can visit our Spark Interview Questions, it will surely help you to crack Spark Interview.
Regards,
Data-Flair
nice post
Hi Fairymaiden,
Thanks for commenting on the differences between Spark RDD, Dataframe and DataSet. Hope you are enjoying other spark tutorials and sharing them with your peer groups.
Regards,
DataFlair
Great information thanks 🙂
Hi Vinay,
We are glad you found our Spark tutorial informative. We have many more tutorials for you, please refer our sidebar for Spark tutorials and main menu for other technologies.
Regards,
DataFlair
Please correct one point under 3.3. Data Formats where it is mentioned that DataFrame works on structured and unstructured which is incorrect as DataFrame works only on Structured and semi-structured data.
Nice Catch Ashok!
Thanks for pointing out a mistake, we have made the necessary changes. Now, you can enjoy your reading – ” Spark RDD vs DataFrame vs dataset”.
Regards,
DataFlair
how we can convert dataframe into RDD
very useful
Usually bore to read but this way of narration bu using simple words make me read everything and cleary undustood the difference.thanks for the excellent article..
RDD is best for When you want low-level transformation and actions on your data set. Can any one tell me what exactly mean low-level transformation and actions with one example
Dataframe and Datasets
One can use both DataFrame and dataset API when we need a high level of abstraction. Can any one tell me what exactly mean high level of abstraction with one example.
very informative explaination.
Pleasae share some examples to understand practially.
Thanks a ton for brilliant sharing! Very informative , nicely sectioned & a very good content