Apache Spark SQL Tutorial – Quick Introduction Guide
1. Objective – Spark SQL
In this Apache Spark SQL tutorial, we will understand various components and terminologies of Spark SQL like what is DataSet and DataFrame, what is SqlContext and HiveContext and What are the features of Spark SQL?
After understanding What is Apache Spark, in this tutorial we will discuss about Apache Spark SQL. Spark SQL is Spark module for structured data processing. It runs on top of Spark Core. It offers much tighter integration between relational and procedural processing, through declarative DataFrame and Datasets API. These are the ways which enable users to run SQL queries over Spark.
So, let’s start Spark SQL Tutorial.

Apache Spark SQL Tutorial – Quick Introduction Guide
2. What is Apache Spark SQL?
Apache Spark SQL integrates relational processing with Sparks functional programming. It is Spark module for structured data processing. Spark SQL blurs the line between RDD and relational table. It also offers much tighter integration between relational and procedural processing, through declarative DataFrame APIs which integrates with Spark code. It thus provides higher optimization. DataFrame API and Datasets API are the ways to interact with Spark SQL. As a result, with Spark SQL, Apache Spark is accessible to more users and improves optimization for current ones.
Spark SQL runs on top of the Spark Core. It allows developers to import relational data from Hive tables and parquet files, run SQL queries over imported data and existing RDDs and easily write RDDs out to Hive tables or Parquet files. As Spark SQL provides DataFrame APIs which performs the relational operation on both external data sources and Sparks built-in distributed collections. Spark SQL introduces extensible optimizer called Catalyst as it helps in supporting a wide range of data sources and algorithms in Bigdata.
3. Apache Spark SQL Interfaces
Let’s discuss the interfaces of Apache Spark SQL in detail –
i. DataFrame
Spark DataFrames evaluates lazily like RDD Transformations in Apache Spark. A DataFrame is equivalent to the relational table in Spark SQL. A DataFrame stores the data into tables. DataFrame is similar/identical to a table in a relational database but with richer optimization. It is a data abstraction and domain-specific language (DSL) applicable on the structure and semi-structured data. It is a distributed collection of data in the form of named column and row. For accessing data frames either SQL Context or Hive Context is needed. Learn about Spark SQL DataFrame in Detail.
ii. SQLContext
It’s the entry point for working with structured data (rows and columns) in Apache Spark. It Allows the creation of DataFrame objects as well as the execution of SQL queries.
iii. Hive Context
Working with Hive tables, a descendant of SQLContext. Hive Context is more battle-tested and provides a richer functionality than SQLContext.
iv. DataSets
A Spark DataSet provides the benefits of RDDs. For example, strongly-typed, immutable collection of objects that map to the relational schema already present (i.e. you can use a field of a row by name naturally row.columnName). Datasets extend the benefit of compile-time type safety (It can analyze the applications for errors before they run). It also allows direct operations over user-defined classes. Learn about Apache Spark DataSet in detail.
v. JDBC Datasource
In Apache Spark, JDBC data source can read data from relational databases using JDBC API. It has preference over the RDD because the data source returns the results as a DataFrame, can be handled in Spark SQL or joined beside other data sources.
vi. Catalyst Optimizer
It is a functional programming construct in Scala. It is the newest and most technical component of Spark SQL. A catalyst is a query plan optimizer. It provides a general framework for transforming trees, which performs analysis/evaluation, optimization, planning, and runtime code spawning. Catalyst supports cost based optimization and rule-based optimization. It makes queries run much faster than their RDD counterparts. A catalyst is a rule-based modular library. Each rule in framework focuses on the distinct optimization. Learn Spark SQL Catalyst Optimizer in detail.
4. Features of Apache Spark SQL
There are several features of Spark SQL which enhance which makes it a key component of Apache Spark framework.
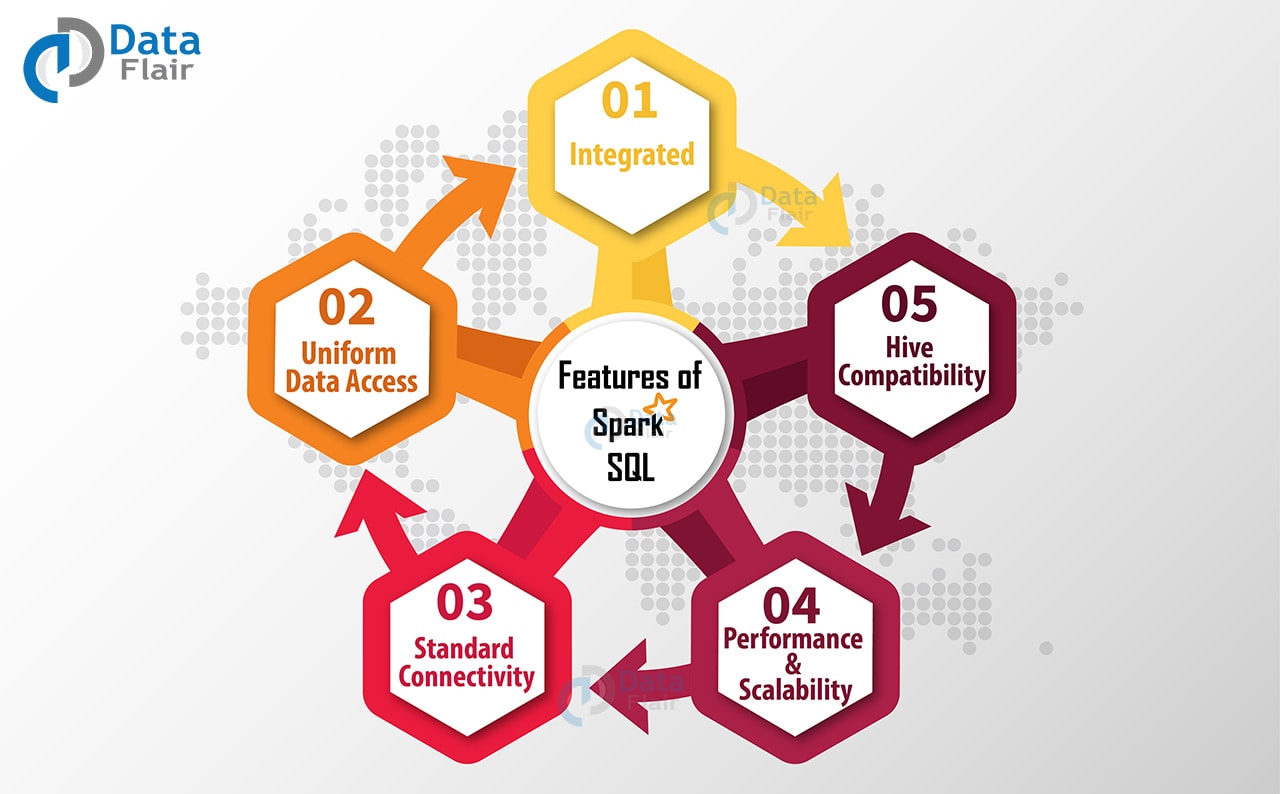
Features of Spark SQL
i. Integrated
Logically mix SQL queries with Spark programs. Apache Spark SQL allows query structured data inside Spark programs, using SQL or a DataFrame API in Java, Scala, Python, and R.
ii. Uniform Data Access
In Spark DataFrames and SQL supports a common way to access a variety of data sources, like Hive, Avro, Parquet, ORC, JSON, and JDBC. Hence Spark SQL can join data across these sources.
iii. Hive Compatibility
Runs unmodified Hive queries on current data. Spark SQL rewrites the Hive frontend and meta store, allowing full compatibility with current Hive data, queries, and UDFs.
v. Standard Connectivity
Connect through JDBC or ODBC. A server that supports industry norms JDBC and ODBC connectivity for business intelligence tools.
v. Performance & Scalability
Apache Spark SQL incorporates a cost-based optimizer, code generation, and columnar storage to make queries agile alongside computing thousands of nodes using the Spark engine, which provides full mid-query fault tolerance.
5. Conclusion
Hence, Spark SQL allows Apache Spark to work with structured and unstructured data. The data can be from various sources. It enhances the performance of Spark applications. As a result, It provides an efficient platform to the Spark developers to work with various type of data.
If in case you have any confusion about Apache Spark SQL, so leave a comment in a section below. We will be glad to solve them.
See Also-
Reference:
http://spark.apache.org/
Your opinion matters
Please write your valuable feedback about DataFlair on Google





In the Conclusion section the first line “Hence, Spark SQL allows Apache Spark to work with structured and unstructured data” — creates a doubt. Al-through I got an impression that Spark SQL works with Structured data but not unstructured data.
Please confirm.
by Spark SQL, we can assign schema to XML,Json files also.
does spark sql have any limitation or potential improvement scope?