Spark Streaming Checkpoint in Apache Spark
1. Objective
In this blog of Apache Spark Streaming Checkpoint, you will read all about Spark Checkpoint. First of all, we will discuss What is Checkpointing in Spark, then, How Checkpointing helps to achieve Fault Tolerance in Apache Spark. Types of Apache Spark Checkpoint i.e Metadata Checkpointing, Data Checkpointing, the comparison between Checkpointing vs Persist() in Spark are also covered in this Spark tutorial.
Spark Streaming Checkpoint in Apache Spark
If you want to learn Apache Spark from basics then our previous post on Apache Spark Introduction will help you. It has a Spark video which helps you to learn Apache Spark simply way.
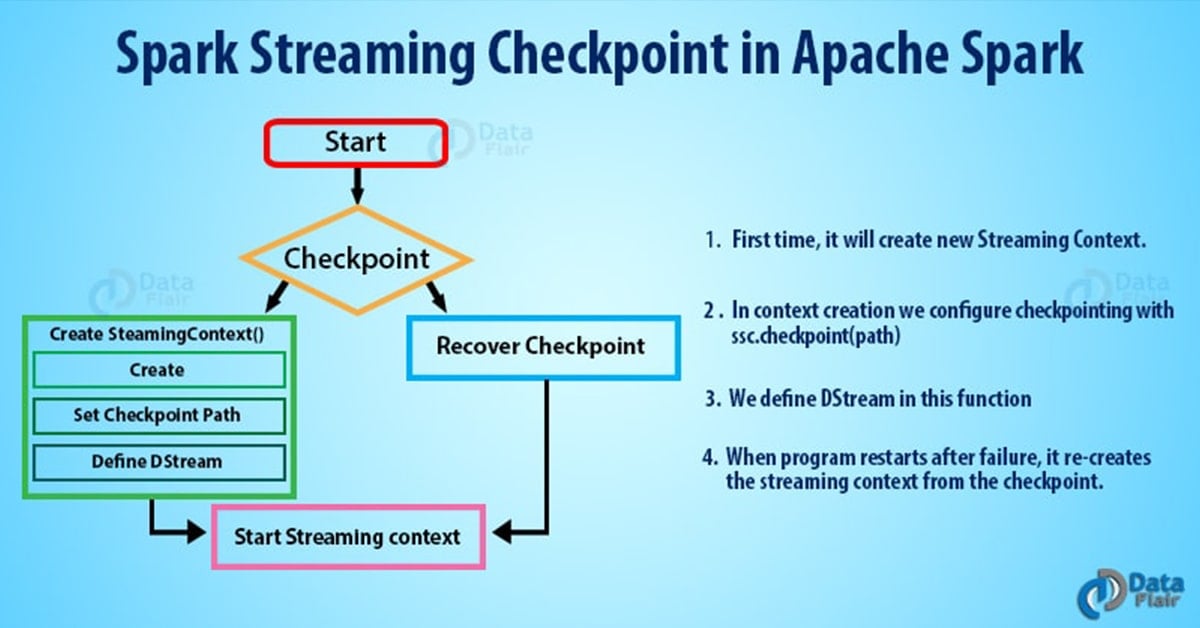
2. Introduction to Spark Streaming Checkpoint
The need with Spark Streaming application is that it should be operational 24/7. Thus, the system should also be fault tolerant. If any data is lost, the recovery should be speedy. Spark streaming accomplishes this using checkpointing.
So, Checkpointing is a process to truncate RDD lineage graph. It saves the application state timely to reliable storage (HDFS). As the driver restarts the recovery takes place.
There are two types of data that we checkpoint in Spark:
- Metadata Checkpointing – Metadata means the data about data. It refers to saving the metadata to fault tolerant storage like HDFS. Metadata includes configurations, DStream operations, and incomplete batches. Configuration refers to the configuration used to create streaming DStream operations are operations which define the steaming application. Incomplete batches are batches which are in the queue but are not complete.
- Data Checkpointing –: It refers to save the RDD to reliable storage because its need arises in some of the stateful transformations. It is in the case when the upcoming RDD depends on the RDDs of previous batches. Because of this, the dependency keeps on increasing with time. Thus, to avoid such increase in recovery time the intermediate RDDs are periodically checkpointed to some reliable storage. As a result, it cuts down the dependency chain.
To set the Spark checkpoint directory call: SparkContext.setCheckpointDir(directory: String)
3. Types of Checkpointing in Apache Spark
There are two types of Apache Spark checkpointing:
- Reliable Checkpointing – It refers to that checkpointing in which the actual RDD is saved in reliable distributed file system, e.g. HDFS. To set the checkpoint directory call: SparkContext.setCheckpointDir(directory: String). When running on the cluster the directory must be an HDFS path since the driver tries to recover the checkpointed RDD from a local file. While the checkpoint files are actually on the executor’s machines.
- Local Checkpointing: In this checkpointing, in Spark Streaming or GraphX we truncate the RDD lineage graph in Spark. In this, the RDD is persisted to local storage in the executor.
4. Difference between Spark Checkpointing and Persist
There are various differences between Spark Checkpoint vs Persist. Let’s discuss it one by one-
Persist
- When we persist RDD with DISK_ONLY storage level the RDD gets stored in a location where the subsequent use of that RDD will not reach that points in recomputing the lineage.
- After persist() is called, Spark remembers the lineage of the RDD even though it doesn’t call it.
- Secondly, after the job run is complete, the cache is cleared and the files are destroyed.
Checkpointing
- Checkpointing stores the RDD in HDFS. It deletes the lineage which created it.
- On completing the job run unlike cache the checkpoint file is not deleted.
- When we checkpointing an RDD it results in double computation. The operation will first call a cache before accomplishing the actual job of computing. Secondly, it is written to checkpointing directory.
5. Conclusion
In the conclusion, using the method of checkpointing one can achieve fault tolerance. It provides fault tolerance to the streaming data when it needs. Also when the read operation is complete the files are not removed like in persist method. Thus, the RDD needs to be checkpointed if the computation takes a long time or the computing chain is too long or if it depends on too many RDDs.
If in case you have any query about Spark Streaming Checkpoint, do leave a comment in a section below.
See Also-
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





What is the usage of dstream.checkpoint(checkpointInterval) apart from check pointing directory.
how do you read a rdd from a checkpoint directory