Spark Tutorial – Learn Spark Programming
1. Objective – Spark Tutorial
In this Spark Tutorial, we will see an overview of Spark in Big Data. We will start with an introduction to Apache Spark Programming. Then we will move to know the Spark History. Moreover, we will learn why Spark is needed. Afterward, will cover all fundamental of Spark components. Furthermore, we will learn about Spark’s core abstraction and Spark RDD. For more detailed insights, we will also cover spark features, Spark limitations, and Spark Use cases.

Apache Spark Tutorial – What is Apache Spark?
2. Introduction to Spark Programming
What is Spark? Spark Programming is nothing but a general-purpose & lightning fast cluster computing platform. In other words, it is an open source, wide range data processing engine. That reveals development API’s, which also qualifies data workers to accomplish streaming, machine learning or SQL workloads which demand repeated access to data sets. However, Spark can perform batch processing and stream processing. Batch processing refers, to the processing of the previously collected job in a single batch. Whereas stream processing means to deal with Spark streaming data.
Moreover, it is designed in such a way that it integrates with all the Big data tools. Like spark can access any Hadoop data source, also can run on Hadoop clusters. Furthermore, Apache Spark extends Hadoop MapReduce to the next level. That also includes iterative queries and stream processing.
One more common belief about Spark is that it is an extension of Hadoop. Although that is not true. However, Spark is independent of Hadoop since it has its own cluster management system. Basically, it uses Hadoop for storage purpose only.
Although, there is one spark’s key feature that it has in-memory cluster computation capability. Also increases the processing speed of an application.
Basically, Apache Spark offers high-level APIs to users, such as Java, Scala, Python, and R. Although, Spark is written in Scala still offers rich APIs in Scala, Java, Python, as well as R. We can say, it is a tool for running spark applications.
Most importantly, by comparing Spark with Hadoop, it is 100 times faster than Hadoop In-Memory mode and 10 times faster than Hadoop On-Disk mode.
3. Spark Tutorial – History
At first, in 2009 Apache Spark was introduced in the UC Berkeley R&D Lab, which is now known as AMPLab. Afterward, in 2010 it became open source under BSD license. Further, the spark was donated to Apache Software Foundation, in 2013. Then in 2014, it became top-level Apache project.
4. Why Spark?
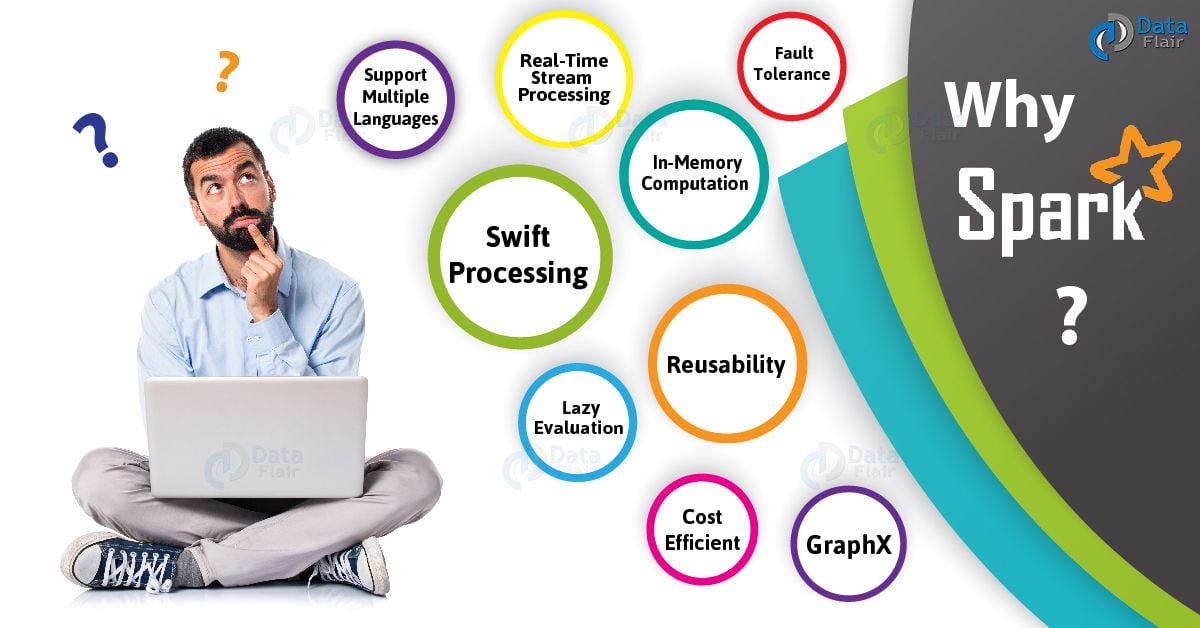
Spark Tutorial – Why Spark?
As we know, there was no general purpose computing engine in the industry, since
- To perform batch processing, we were using Hadoop MapReduce.
- Also, to perform stream processing, we were using Apache Storm / S4.
- Moreover, for interactive processing, we were using Apache Impala / Apache Tez.
- To perform graph processing, we were using Neo4j / Apache Giraph.
Hence there was no powerful engine in the industry, that can process the data both in real-time and batch mode. Also, there was a requirement that one engine can respond in sub-second and perform in-memory processing.
Therefore, Apache Spark programming enters, it is a powerful open source engine. Since, it offers real-time stream processing, interactive processing, graph processing, in-memory processing as well as batch processing. Even with very fast speed, ease of use and standard interface. Basically, these features create the difference between Hadoop and Spark. Also makes a huge comparison between Spark vs Storm.
5. Apache Spark Components
In this Apache Spark Tutorial, we discuss Spark Components. It puts the promise for faster data processing as well as easier development. It is only possible because of its components. All these Spark components resolved the issues that occurred while using Hadoop MapReduce.
Now let’s discuss each Spark Ecosystem Component one by one-
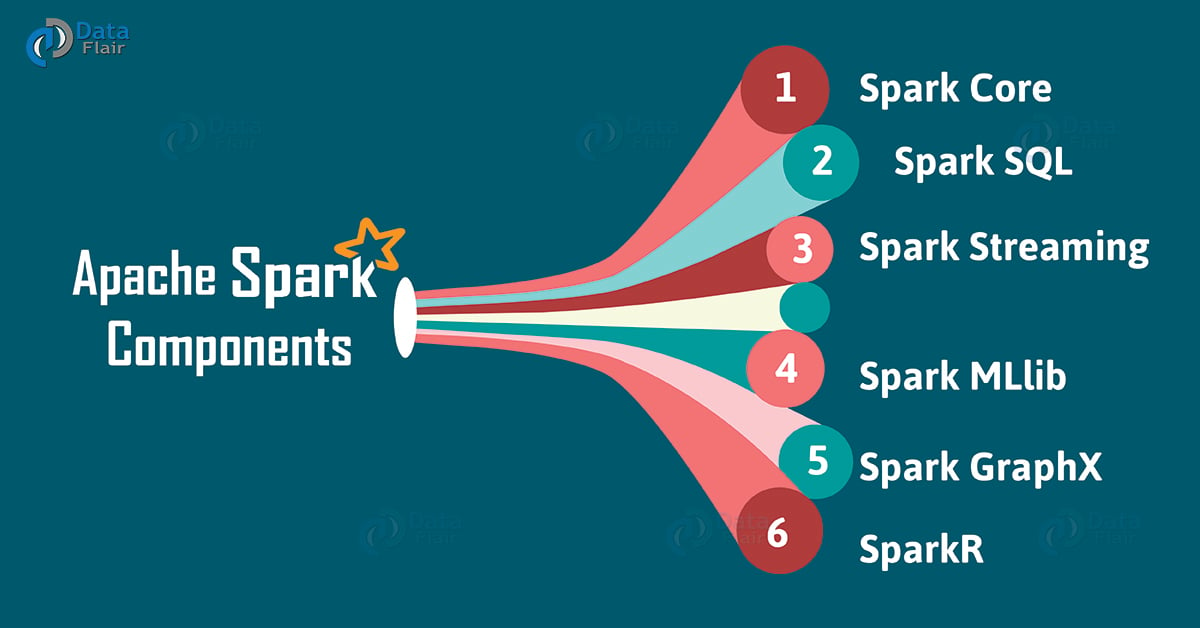
Spark Tutorial – Apache Spark Ecosystem Components
a. Spark Core
Spark Core is a central point of Spark. Basically, it provides an execution platform for all the Spark applications. Moreover, to support a wide array of applications, Spark Provides a generalized platform.
b. Spark SQL
On the top of Spark, Spark SQL enables users to run SQL/HQL queries. We can process structured as well as semi-structured data, by using Spark SQL. Moreover, it offers to run unmodified queries up to 100 times faster on existing deployments. To learn Spark SQL in detail, follow this link.
c. Spark Streaming
Basically, across live streaming, Spark Streaming enables a powerful interactive and data analytics application. Moreover, the live streams are converted into micro-batches those are executed on top of spark core. Learn Spark Streaming in detail.
d. Spark MLlib
Machine learning library delivers both efficiencies as well as the high-quality algorithms. Moreover, it is the hottest choice for a data scientist. Since it is capable of in-memory data processing, that improves the performance of iterative algorithm drastically.
e. Spark GraphX
Basically, Spark GraphX is the graph computation engine built on top of Apache Spark that enables to process graph data at scale.
f. SparkR
Basically, to use Apache Spark from R. It is R package that gives light-weight frontend. Moreover, it allows data scientists to analyze large datasets. Also allows running jobs interactively on them from the R shell. Although, the main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark. Follow the link to learn SparkR in detail.
To learn about all the components of Spark in detail, follow link Apache Spark Ecosystem – Complete Spark Components Guide
6. Resilient Distributed Dataset – RDD
The key abstraction of Spark is RDD. RDD is an acronym for Resilient Distributed Dataset. It is the fundamental unit of data in Spark. Basically, it is a distributed collection of elements across cluster nodes. Also performs parallel operations. Moreover, Spark RDDs are immutable in nature. Although, it can generate new RDD by transforming existing Spark RDD.Learn about Spark RDDs in detail.
a. Ways to create Spark RDD
Basically, there are 3 ways to create Spark RDDs
i. Parallelized collections
By invoking parallelize method in the driver program, we can create parallelized collections.
ii. External datasets
One can create Spark RDDs, by calling a textFile method. Hence, this method takes URL of the file and reads it as a collection of lines.
iii. Existing RDDs
Moreover, we can create new RDD in spark, by applying transformation operation on existing RDDs.
To learn all three ways to create RDD in detail, follow the link.
b. Spark RDDs operations
There are two types of operations, which Spark RDDs supports:
i. Transformation Operations
It creates a new Spark RDD from the existing one. Moreover, it passes the dataset to the function and returns new dataset.
ii. Action Operations
In Apache Spark, Action returns final result to driver program or write it to the external data store.
Learn RDD Operations in detail.
c. Sparkling Features of Spark RDD
There are various advantages of using RDD. Some of them are

Spark Tutorial – Spark RDD Features
i. In-memory computation
Basically, while storing data in RDD, data is stored in memory for as long as you want to store. It improves the performance by an order of magnitudes by keeping the data in memory.
ii. Lazy Evaluation
Spark Lazy Evaluation means the data inside RDDs are not evaluated on the go. Basically, only after an action triggers all the changes or the computation is performed. Therefore, it limits how much work it has to do. learn Lazy Evaluation in detail.
iii. Fault Tolerance
If any worker node fails, by using lineage of operations, we can re-compute the lost partition of RDD from the original one. Hence, it is possible to recover lost data easily. Learn Fault Tolerance in detail.
iv. Immutability
Immutability means once we create an RDD, we can not manipulate it. Moreover, we can create a new RDD by performing any transformation. Also, we achieve consistency through immutability.
v. Persistence
In in-memory, we can store the frequently used RDD. Also, we can retrieve them directly from memory without going to disk. It results in the speed of the execution. Moreover, we can perform multiple operations on the same data. It is only possible by storing the data explicitly in memory by calling persist() or cache() function.
Learn Persistence and Caching Mechanism in detail.
vi. Partitioning
Basically, RDD partition the records logically. Also, distributes the data across various nodes in the cluster. Moreover, the logical divisions are only for processing and internally it has no division. Hence, it provides parallelism.
vii. Parallel
While we talk about parallel processing, RDD processes the data parallelly over the cluster.
viii. Location-Stickiness
To compute partitions, RDDs are capable of defining placement preference. Moreover, placement preference refers to information about the location of RDD. Although, the DAGScheduler places the partitions in such a way that task is close to data as much as possible. Moreover, it speeds up computation.
ix. Coarse-grained Operation
Generally, we apply coarse-grained transformations to Spark RDD. It means the operation applies to the whole dataset not on the single element in the data set of RDD in Spark.
x. Typed
There are several types of Spark RDD. Such as: RDD [int], RDD [long], RDD [string].
xi. No limitation
There are no limitations to use the number of Spark RDD. We can use any no. of RDDs. Basically, the limit depends on the size of disk and memory.
In this Apache Spark tutorial, we cover most Features of Spark RDD to learn more about RDD Features follow this link.
7. Spark Tutorial – Spark Streaming
While data is arriving continuously in an unbounded sequence is what we call a data stream. Basically, for further processing, Streaming divides continuous flowing input data into discrete units. Moreover, we can say it is a low latency processing and analyzing of streaming data.
In addition, an extension of the core Spark API Streaming was added to Apache Spark in 2013. That offers scalable, fault-tolerant and high-throughput processing of live data streams. Although, here we can do data ingestion from many sources. Such as Kafka, Apache Flume, Amazon Kinesis or TCP sockets. However, we do processing here by using complex algorithms which are expressed with high-level functions such as map, reduce, join and window.
a. Internal working of Spark Streaming
Let’s understand its internal working. While live input data streams are received. It further divided into batches by Spark streaming, Afterwards, these batches are processed by the Spark engine to generate the final stream of results in batches.
b. Discretized Stream (DStream)
Apache Spark Discretized Stream is the key abstraction of Spark Streaming. That is what we call Spark DStream. Basically, it represents a stream of data divided into small batches. Moreover, DStreams are built on Spark RDDs, Spark’s core data abstraction. It also allows Streaming to seamlessly integrate with any other Apache Spark components. Such as Spark MLlib and Spark SQL.
Follow this link, to Learn Concept of Dstream in detail.
8. Features of Apache Spark
There are several sparkling Apache Spark features:
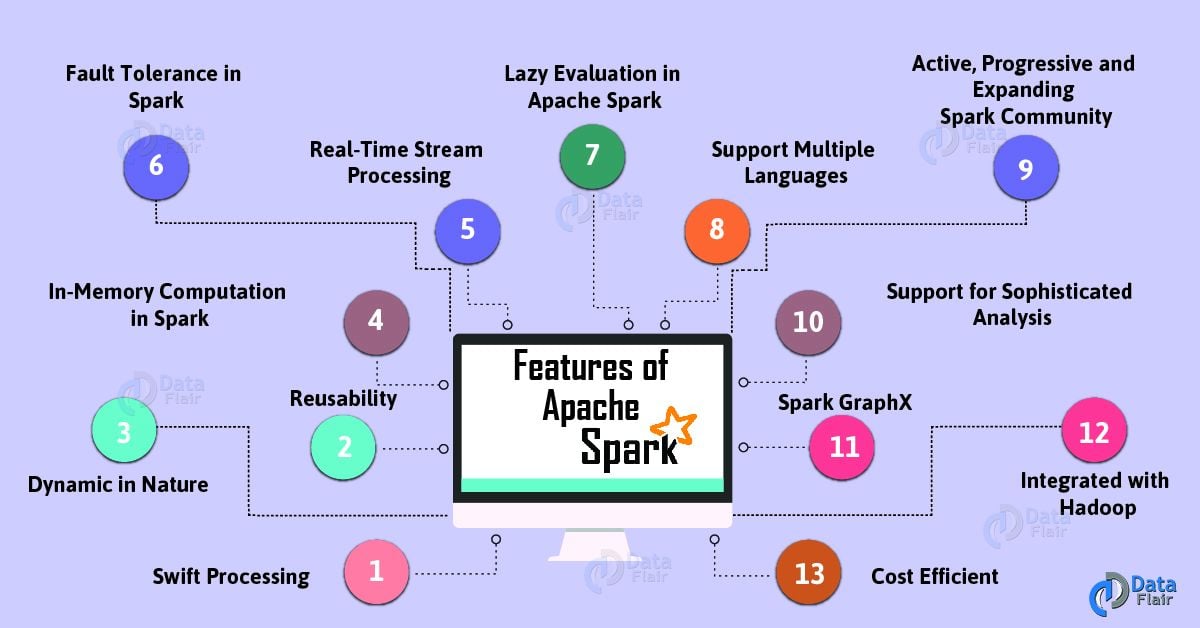
Apache Spark Tutorial – Features of Apache Spark
a. Swift Processing
Apache Spark offers high data processing speed. That is about 100x faster in memory and 10x faster on the disk. However, it is only possible by reducing the number of read-write to disk.
b. Dynamic in Nature
Basically, it is possible to develop a parallel application in Spark. Since there are 80 high-level operators available in Apache Spark.
c. In-Memory Computation in Spark
The increase in processing speed is possible due to in-memory processing. It enhances the processing speed.
d. Reusability
We can easily reuse spark code for batch-processing or join stream against historical data. Also to run ad-hoc queries on stream state.
e. Spark Fault Tolerance
Spark offers fault tolerance. It is possible through Spark’s core abstraction-RDD. Basically, to handle the failure of any worker node in the cluster, Spark RDDs are designed. Therefore, the loss of data is reduced to zero.
f. Real-Time Stream Processing
We can do real-time stream processing in Spark. Basically, Hadoop does not support real-time processing. It can only process data which is already present. Hence with Spark Streaming, we can solve this problem.
g. Lazy Evaluation in Spark
All the transformations we make in Spark RDD are Lazy in nature, that is it does not give the result right away rather a new RDD is formed from the existing one. Thus, this increases the efficiency of the system.
h. Support Multiple Languages
Spark supports multiple languages. Such as Java, R, Scala, Python. Hence, it shows dynamicity. Moreover, it also overcomes the limitations of Hadoop since it can only build applications in Java.
i. Support for Sophisticated Analysis
There are dedicated tools in Apache Spark. Such as for streaming data interactive/declarative queries, machine learning which add-on to map and reduce.
j. Integrated with Hadoop
As we know Spark is flexible. It can run independently and also on Hadoop YARN Cluster Manager. Even it can read existing Hadoop data.
k. Spark GraphX
In Spark, a component for graph and graph-parallel computation, we have GraphX. Basically, it simplifies the graph analytics tasks by the collection of graph algorithm and builders.
l. Cost Efficient
For Big data problem as in Hadoop, a large amount of storage and the large data center is required during replication. Hence, Spark programming turns out to be a cost-effective solution.
Learn All features of Apache Spark, in detail.
9. Limitations of Apache Spark Programming
There are many limitations of Apache Spark. Let’s learn all one by one:

Spark Tutorial – Limitations of Apache Spark Programming
a. No Support for Real-time Processing
Basically, Spark is near real-time processing of live data. In other words, Micro-batch processing takes place in Spark Streaming. Hence we can not say Spark is completely Real-time Processing engine.
b. Problem with Small File
In RDD, each file is a small partition. It means, there is the large amount of tiny partition within an RDD. Hence, if we want efficiency in our processing, the RDDs should be repartitioned into some manageable format. Basically, that demands extensive shuffling over the network.
c. No File Management System
A major issue is Spark does not have its own file management system. Basically, it relies on some other platform like Hadoop or another cloud-based platform.
d. Expensive
While we desire cost-efficient processing of big data, Spark turns out to be very expensive. Since keeping data in memory is quite expensive. However the memory consumption is very high, and it is not handled in a user-friendly manner. Moreover, we require lots of RAM to run in-memory, thus the cost of spark is much higher.
e. Less number of Algorithms
Spark MLlib have very less number of available algorithms. For example, Tanimoto distance.
f. Manual Optimization
It is must that Spark job is manually optimized and is adequate to specific datasets. Moreover, to partition and cache in spark to be correct, it is must to control it manually.
g. Iterative Processing
Basically, here data iterates in batches. Also, each iteration is scheduled and executed separately.
h. Latency
On comparing with Flink, Apache Spark has higher latency.
i. Window Criteria
Spark only support time-based window criteria not record based window criteria.
Note: To overcome these limitations of Spark, we can use Apache Flink – 4G of Big Data.
Learn All Limitations of Apache Spark, in detail.
10. Apache Spark Tutorial – Use Cases
There are many industry-specific Apache Spark use cases, let’s discuss them one by one:
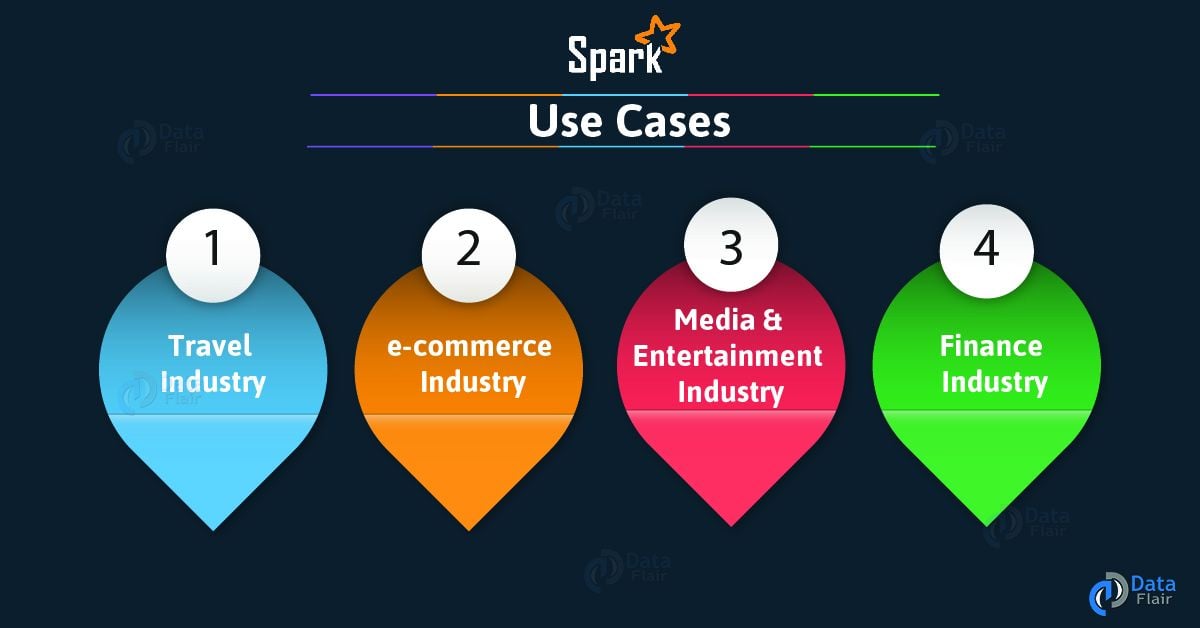
Spark Tutorial – Apache Spark Use Cases
a. Spark Use Cases in the Finance Industry
There are many banks those are using Spark. Basically, it helps to access and analyze many of the parameters in the bank sector like the emails, social media profiles, call recordings, forum, and many more. Further, it helps to make right decisions for several zones.
b. Apache Spark Use Cases in E-Commerce Industry
Basically, it helps with information about a real-time transaction. Moreover, those are passed to streaming clustering algorithms.
c. Apache Spark Use Cases in Media & Entertainment Industry
We use Spark to identify patterns from the real-time in-game events. Moreover, it helps to respond in order to harvest lucrative business opportunities.
d. Apache Spark Use Cases in Travel Industry
Basically, travel industries are using spark rapidly. Moreover, it helps users to plan a perfect trip by speed up the personalized recommendations. Although, its review process of the hotels in a readable format is done by using Spark.
Apache Spark tutorial cover Spark real-time use Cases, there are many more, follow the link to learn all in detail. Apache Spark use cases in real time
11. Spark Tutorial – Conclusion
As a result, we have seen every aspect of Apache Spark, what is Apache spark programming and spark definition, History of Spark, why Spark is needed, Components of Apache Spark, Spark RDD, Features of Spark RDD, Spark Streaming, Features of Apache Spark, Limitations of Apache Spark, Apache Spark use cases. In this tutorial we were trying to cover all spark notes, hope you get desired information in it if you feel to ask any query, feel free to ask in the comment section.
Best Books to Learn Spark.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





Thank you; very informative!
Hi Robert,
We are enthralled that you liked our Spark Tutorial. Nice feedback from our loyal readers like this always motivates us to work harder, so that we can provide you with more great stuff.
Keep connected with us for more Spark tutorials.
Thank you , Great info.
Hello Srinivas,
Thanks for taking the time and leaving a review on our blog Apache Spark Tutorial.
Keep Visiting DataFlair
Very nicely explained. The content was crisp and clear
Hi Rahul,
We are glad you like our Spark Tutorial. You can refer our sidebar for more articles and you can play spark quiz to know your performance.
Keep learning and keep visiting DataFlair
Hi, thanks for the valuable information, my question is do you have a private trainer to teach one to one classes?
Hi Hawazin,
Thanks for sharing your feedback. Yes, we do provide our Certified Apache Spark Training Course. Each batch holds 2 instructors for 12 students, which makes for a great one-to-one experience with the instructor. This will enable you to clear your doubts and also interact with the entire batch so you can learn even more in the process.
For more details, you can visit our Apache Spark Course Page.
Regards,
DataFlair
one of the best blogs in Apache Spark, each concept is explained with examples. It will be really good if for each concept, sample code is shared.
Hello Anil,
Thanks for such nice words for “Apache Spark Tutorial for beginners”, we have 50+ tutorial on Spark, which will help you to master in Big Data. So, you can refer them too.
Regards,
DataFlair
Hi Team,
Thanks for this informative spark blog. Can you please share the sample use case or questions for our practice?
Hello Rahul,
Thanks for the appreciation, you can refer our sidebar for more Spark tutorials and we have series of Spark Interview Questions and Quizzes for practicing.
Hope, it will help you!
DataFlair
Very helpful content! I’m always here on your blog for my new big data tech blogs. Keep adding more contents!
Whenever I search for any technical stuff I always look for data-flair… It kinds of one destination solution for many technology.. Thanks for providing such a nice portal.
I’ve visited many websites. But you guys have the best tutorial. In detail and easy to capture. Helped me a lot.
Hats off to the DataFlair team.
very helpful… Thanks DatFlair!!!
I’m confused with the phrase highlighted in double quote –> it is 100 times faster than Big Data Hadoop and “10 times faster than accessing data from disk”
I don’t think above highlighted is needed, because even Hadoop also read and process the data from disk (MapReduce). If this case what is need of mentioning separately again as above ?
Correct me If I’m Wrong
Hey Ravi,
Thanks for the pointing out. We have made the necessary changes in the above Spark tutorial.
Keep Visiting DataFlair
One of the best apache spark tutorial blog.It helped me to understand all the concepts and all points covered very well.
Thank U so much for this valuable information.
Thanks for the feedback. If you liked the Spark tutorial, share it on Facebook and Linkedin with your friends.
This is very detail ,clear and easy to understand…Thanks Data Flair !!
I like the explanation of spark limitations.
One of the best pages to learn spark in depth and clear.
As of now in 2020 for a fresher which is a better tool to learn either Apache Spark or Flink?
it is a good website to learn spark
spark is good technology
Nice and detailed explanation, could you add a blog for Adaptive Query Execution, it is the only piece missing (P.S. post link if available)
Which are these 80 high level operators in Spark and how they are helping spark for enabling parallel application as mentioned in section 8.b Dynamic in Nature?
I don’t know why it is mentioned cost efficient in features and Expensive in limitations.
Can someone resolve this.
Hi Team DataFlair.
It’s July 2022? So does BigData course or study content updated or not like industry expect? because I saw the comments and most of these are showing older like 2017, 18, or 19.
Obviously, there is no doubt about this content you provided here in free of cost, it’s excellent. But just for that doubt I’m asked.
In Big Data Course, we are use Hadoop 3.x, which is latest (and most popular) version of Hadoop. Apart from this, we use Spark 2.x, the most popular version of Spark, we will upgrade this to spark 3.x in the near future.
very nice and informative introduction