11 Shining Features of Spark RDD You Must Know
1. Objective
In this Spark tutorial, we will come across various twinkling features of Spark RDD. Before moving forward to this blog make yourself familiar with the concepts of Bigdata and Apache Spark. This blog also contains the introduction to Apache Spark RDD and its operations along with the methods to create RDD.
To play with RDD learn Apache Spark Installation in standalone mode and Multi-cluster node.
11 Shining Features of Spark RDD You Must Know
2. Apache Spark RDD
RDD stands Resilient Distributed Dataset. RDDs are the fundamental abstraction of Apache Spark. It is an immutable distributed collection of the dataset. Each dataset in RDD is divided into logical partitions. On the different node of the cluster, we can compute These partitions. RDDs are a read-only partitioned collection of record. we can create RDD in three ways:
- Parallelizing already existing collection in driver program.
- Referencing a dataset in an external storage system (e.g. HDFS, Hbase, shared file system).
- Creating RDD from already existing RDDs.
There are two operations in RDD namely transformation and Action.
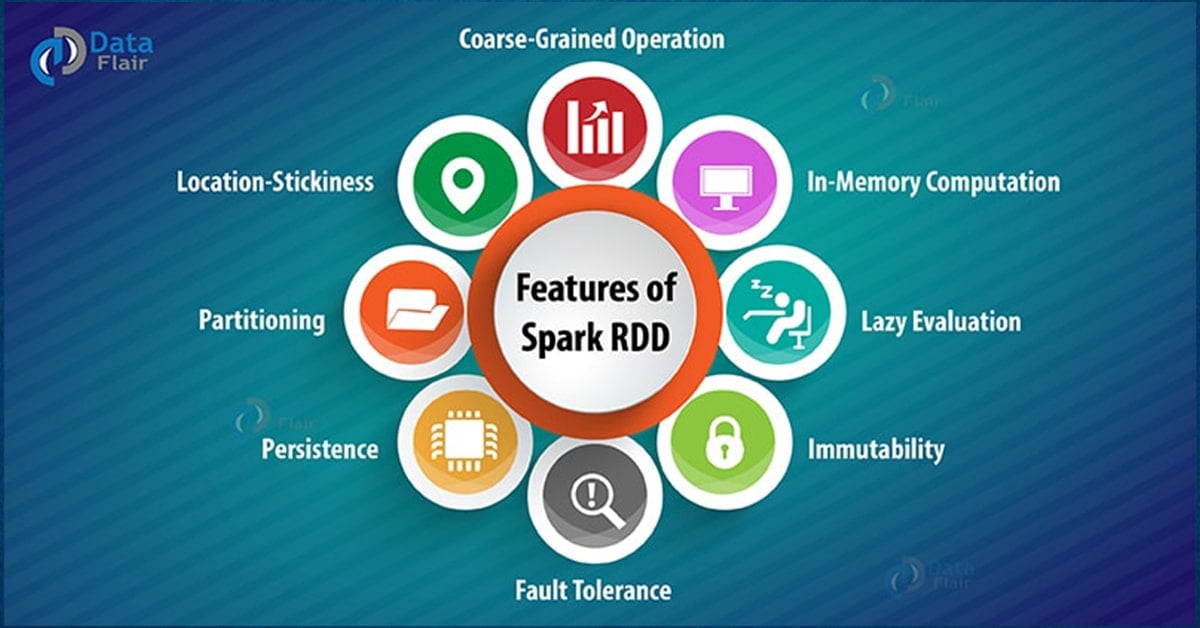
3. Sparkling Features of Spark RDD
There are several advantages of using RDD. Some of them are-
i. In-memory computation
The data inside RDD are stored in memory for as long as you want to store. Keeping the data in-memory improves the performance by an order of magnitudes. refer this comprehensive guide to Learn Spark in-memory computation in detail.
ii. Lazy Evaluation
The data inside RDDs are not evaluated on the go. The changes or the computation is performed only after an action is triggered. Thus, it limits how much work it has to do. Follow this guide to learn Spark lazy evaluation in great detail.
iii. Fault Tolerance
Upon the failure of worker node, using lineage of operations we can re-compute the lost partition of RDD from the original one. Thus, we can easily recover the lost data. Learn Fault tolerance is Spark in detail.
iv. Immutability
RDDS are immutable in nature meaning once we create an RDD we can not manipulate it. And if we perform any transformation, it creates new RDD. We achieve consistency through immutability.
v. Persistence
We can store the frequently used RDD in in-memory and we can also retrieve them directly from memory without going to disk, this speedup the execution. We can perform Multiple operations on the same data, this happens by storing the data explicitly in memory by calling persist() or cache() function. Follow this guide for the detailed study of RDD persistence in Spark.
vi. Partitioning
RDD partition the records logically and distributes the data across various nodes in the cluster. The logical divisions are only for processing and internally it has no division. Thus, it provides parallelism.
vii. Parallel
Rdd, process the data parallelly over the cluster.
viii. Location-Stickiness
RDDs are capable of defining placement preference to compute partitions. Placement preference refers to information about the location of RDD. The DAGScheduler places the partitions in such a way that task is close to data as much as possible. Thus speed up computation. Follow this guide to learn What is DAG?
ix. Coarse-grained Operation
We apply coarse-grained transformations to RDD. Coarse-grained meaning the operation applies to the whole dataset not on an individual element in the data set of RDD.
x. Typed
We can have RDD of various types like: RDD [int], RDD [long], RDD [string].
xi. No limitation
4. Conclusion
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google




