Spark SQL Optimization – Understanding the Catalyst Optimizer
1. Objective
The goal of this Apache Spark tutorial is to describe the Spark SQL Optimization framework and how it allows developers to express complex query transformations in very few lines of code. we will also describe How Spark SQL improves the execution time of queries by greatly improving its query optimization capabilities. We will also cover what is an optimization, why catalyst optimizer, what are its fundamental units of working and the phases of Spark execution flow in this tutorial.
Spark SQL Optimization – Understanding the Catalyst Optimizer
2. Introduction to Apache Spark SQL Optimization
“The term optimization refers to a process in which a system is modified in such a way that it work more efficiently or it uses fewer resources.”
Spark SQL is the most technically involved component of Apache Spark. Spark SQL deals with both SQL queries and DataFrame API. In the depth of Spark SQL there lies a catalyst optimizer. Catalyst optimization allows some advanced programming language features that allow you to build an extensible query optimizer.
A new extensible optimizer called Catalyst emerged to implement Spark SQL. This optimizer is based on functional programming construct in Scala.
Catalyst Optimizer supports both rule-based and cost-based optimization. In rule-based optimization the rule based optimizer use set of rule to determine how to execute the query. While the cost based optimization finds the most suitable way to carry out SQL statement. In cost-based optimization, multiple plans are generated using rules and then their cost is computed.
3. What is the need of Catalyst Optimizer?
There are two purposes behind Catalyst’s extensible design:
- We want to add the easy solution to tackle various problems with Bigdata like a problem with semi-structured data and advanced data analytics.
- We want an easy way such that external developers can extend the optimizer.
4. Fundamentals of Catalyst Optimizer
Catalyst optimizer makes use of standard features of Scala programming like pattern matching. In the depth, Catalyst contains the tree and the set of rules to manipulate the tree. There are specific libraries to process relational queries. There are various rule sets which handle different phases of query execution like analysis, query optimization, physical planning, and code generation to compile parts of queries to Java bytecode. Let’s discuss the tree and rules is detail-
4.1. Trees
A tree is the main data type in the catalyst. A tree contains node object. For each node, there is a node. A node can have one or more children. New nodes are defined as subclasses of TreeNode class. These objects are immutable in nature. The objects can be manipulated using functional transformation. See RDD Transformations and Actions Guide for more details about Functional transformations.
For example, if we have three node classes: worth, attribute, and sub in which-
- worth(value: Int): a constant value
- attribute(name: String)
- sub (left: TreeNode, right: TreeNode): subtraction of two expressions.

spark-sql-catalyst-optimizer-tree-example
Then a tree will look like-
4.2. Rules
We can manipulate tree using rules. We can define rules as a function from one tree to another tree. With rule we can run arbitrary code on input tree, the common approach to use a pattern matching function and replace subtree with a specific structure. In a tree with the help of transform function, we can recursively apply pattern matching on all the node of a tree. We get the pattern that matches each pattern to a result.
For example-
tree.transform {case Sub(worth(c1),worth(c2)) => worth(c1+c2) }
The expression that is passed during pattern matching to transform is a partial function. By partial function, it means it only needs to match to a subset of all possible input trees. Catalyst will see, to which part of a tree the given rule applies, and will automatically skip over the tree that does not match. With the same transform call, the rule can match multiple patterns.
For example-
tree.transform {
case Sub(worth(c1), worth(c2)) =>worth(c1-c2)
case Sub(left , worth(0)) => left
case Sub(worth(0), right) => right
}
To fully transform a tree, rule may be needed to execute multiple time.
Catalyst work by grouping rules into batches and these batches are executed until a fixed point is achieved. Fixed point is a point after which tree stops changing even after applying rules.
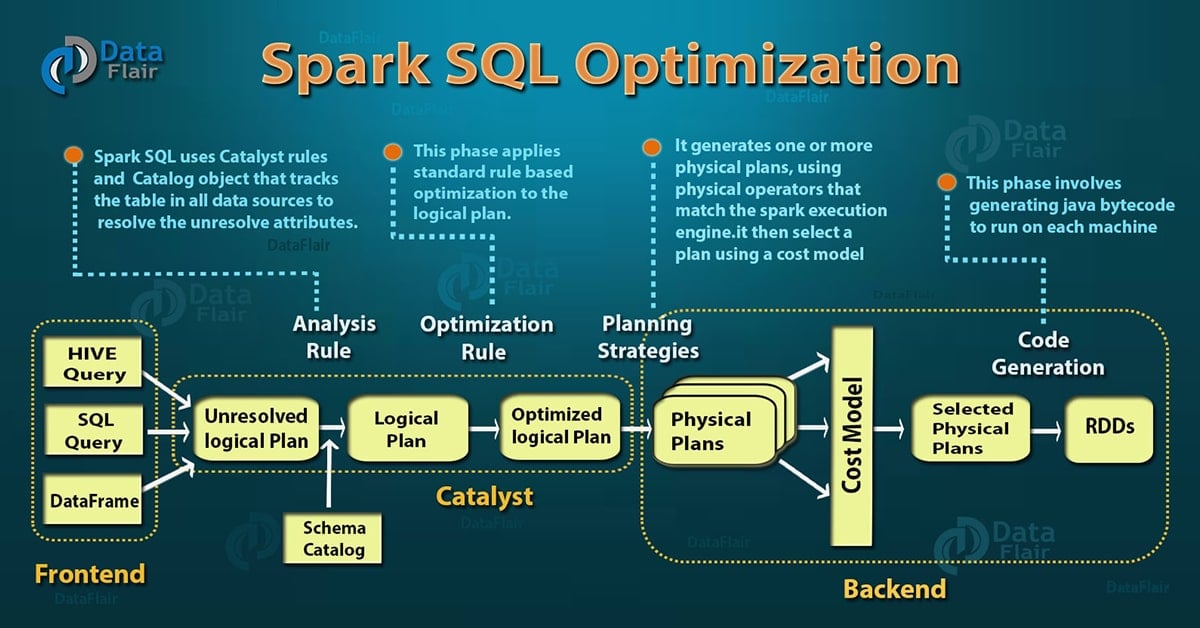
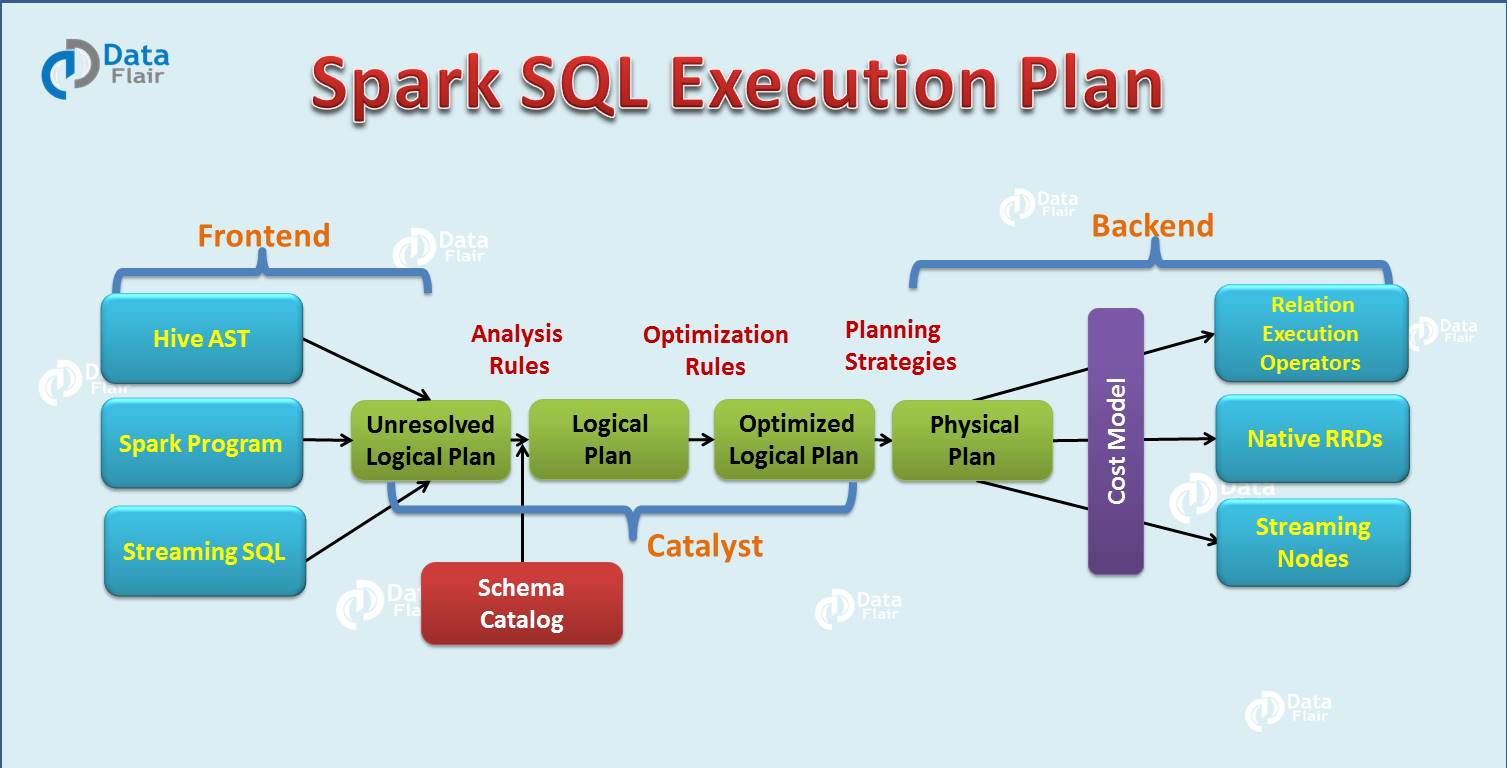
5. Spark SQL Execution Plan
After the detailed introduction of Apache Spark SQL catalyst optimizer, now we will discuss the Spark SQL query execution phases. In four phases we use Catalyst’s general tree transformation framework:
- Analysis
- Logical Optimization
- Physical planning
- Code generation
Phases-of-Spark-SQL-Execution-plan
5.1. Analysis
Spark SQL Optimization starts from relation to be computed. It is computed either from abstract syntax tree (AST) returned by SQL parser or dataframe object created using API. Both may contain unresolved attribute references or relations. By unresolved attribute, it means we don’t know its type or have not matched it to an input table. Spark SQL make use of Catalyst rules and a Catalog object that track data in all data sources to resolve these attributes. It starts by creating an unresolved logical plan, and then apply the following steps:
- Search relation BY NAME FROM CATALOG.
- Map the name attribute, for example, col, to the input provided given operator’s children.
- Determine which attributes match to the same value to give them unique ID.
- Propagate and push type through expressions.
5.2. Logical Optimization
In this phase of Spark SQL optimization, the standard rule-based optimization is applied to the logical plan. It includes constant folding, predicate pushdown, projection pruning and other rules. It became extremely easy to add a rule for various situations.
5.3. Physical Planning
There are about 500 lines of code in the physical planning rules. In this phase, one or more physical plan is formed from the logical plan, using physical operator matches the Spark execution engine. And it selects the plan using the cost model. It uses Cost-based optimization only to select join algorithms. For small relation SQL uses broadcast join, the framework supports broader use of cost-based optimization. It can estimate the cost recursively for the whole tree using the rule.
Rule-based physical optimization, such as pipelining projections or filters into one Spark map Operation is also carried out by the physical planner. Apart from this, it can also push operations from the logical plan into data sources that support predicate or projection pushdown.
5.4. Code Generation
The final phase of Spark SQL optimization is code generation. It involves generating Java bytecode to run on each machine. Catalyst uses the special feature of Scala language, “Quasiquotes” to make code generation easier because it is very tough to build code generation engines. Quasiquotes lets the programmatic construction of abstract syntax trees (ASTs) in the Scala language, which can then be fed to the Scala compiler at runtime to generate bytecode. With the help of a catalyst, we can transform a tree representing an expression in SQL to an AST for Scala code to evaluate that expression, and then compile and run the generated code.
6. Conclusion
Hence, Spark SQL optimization enhances the productivity of developers and the performance of the queries that they write. A good query optimizer automatically rewrites relational queries to execute more efficiently, using techniques such as filtering data early, utilizing available indexes, and even ensuring different data sources are joined in the most efficient order.
By performing these transformations, the optimizer improves the execution times of relational queries and frees the developer from focusing on the semantics of their application instead of its performance.
Catalyst makes use of Scala’s powerful features such as pattern matching and runtime metaprogramming to allow developers to concisely specify complex relational optimizations.
See Also-
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





does spark sql have any limitation or potential improvement scope?