Introduction to Apache Spark Paired RDD
1. Objective
In Apache Spark, key-value pairs are what we call as paired RDD. This Spark Paired RDD tutorial aims the information on what are paired RDDs in Spark. We will also learn following methods of creating spark paired RDD and operations on paired RDDs in spark. Such as transformations and actions in Spark RDD. Here transformation operations are groupByKey, reduceByKey, join, left outer join/right OuterJoin. Whereas actions like countByKey. However initially, we will learn a brief introduction to Spark RDDs.
So, let’s start Spark Paired RDD Tutorial.

Introduction to Apache Spark Paired RDD
2. What is Spark RDD?
Apache Spark’s Core abstraction is Resilient Distributed Datasets, an acronym for Resilient Distributed Datasets is RDD. Also, a fundamental data structure of Spark. Moreover, Spark RDDs is immutable in nature. As well as the distributed collection of objects. Basically, RDD in spark is designed as each dataset in RDD is divided into logical partitions. Further, we can say here each partition may be computed on different nodes of the cluster. Moreover, Spark RDDs contain user-defined classes.
You must test your Spark Learning
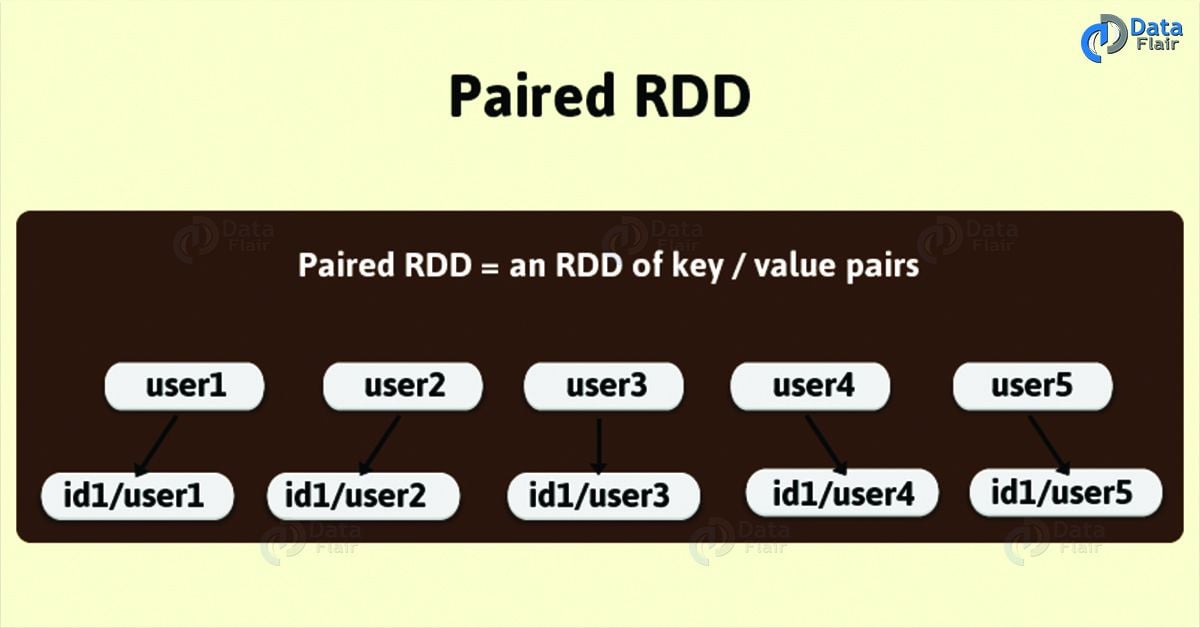
Spark Paired RDD
In addition, Spark RDD is a read-only, partitioned collection of records. Also, They are the fault-tolerant collection of elements which we can operate in parallel. We can also create RDDs, basically in 3 ways. Either by data in stable storage, by other RDDs, or by parallelizing existing collection in driver program. We can achieve faster and efficient MapReduce operations through RDDs.
3. Introduction on Spark Paired RDD
Spark Paired RDDs are nothing but RDDs containing a key-value pair. Basically, key-value pair (KVP) consists of a two linked data item in it. Here, the key is the identifier, whereas value is the data corresponding to the key value.
Moreover, Spark operations work on RDDs containing any type of objects. However key-value pair RDDs attains few special operations in it. Such as, distributed “shuffle” operations, grouping or aggregating the elements by a key.
In addition, on Spark Paired RDDs containing Tuple2 objects in Scala, these operations are automatically available. Basically, operations for the key-value pair are available in the Pair RDD functions class. However, that wraps around a Spark RDD of tuples.
Have a look at Spark SQL Features
For example,
Basically here we are using the reduceByKey operation on key-value pairs. In this code we will count how many times each line of text occurs in a file:
val lines22 = sc.textFile(“data1.txt”)
val pairs22= lines22.map(s => (s, 1))
val counts1 = pairs22.reduceByKey((a, b) => a + b)
Although, one more method we can use is counts.sortByKey().
4. Importance of Paired RDD in Apache Spark
We can say pair RDDs plays the role of very useful building block, in many programs. Basically, some operations that allow us to act on each key in parallel, that exposes those operations. Moreover, through this, we can regroup the data across the network. Like, in spark paired RDDs reduceByKey() method aggregate data separately for each key. Whereas join() method, merges two RDDs together by grouping elements with the same key. However, we can easily extract fields from an RDD. Such as customer ID, an event time, representing, for instance, or other identifiers. Afterward, it uses those fields as keys in spark pair RDD operations.
Do you know about Structured Streaming in SparkR
5. How to Create Spark Paired RDD
There are several ways to create Paired RDD in Spark, like by running a map() function that returns key-value pairs. However, language differs the procedure to build the key-value RDD. Such as
a. In Python language
It is a requirement to return an RDD composed of Tuples for the functions of keyed data to work. Moreover, in spark for creating a pair RDD, we use the first word as the key in python programming language.
pairs = lines.map(lambda x: (x.split(” “)[0], x))
b. In Scala language
As similar to the previous example here also we need to return tuples. Furthermore, this will make available the functions of keyed data. Also, to offer the extra key or value functions, an implicit conversion on Spark RDD of tuples exists.
Let’s revise Data type Mapping between R and Spark
Afterward, again by using the first word as the keyword creating apache spark pair RDD.
val pairs = lines.map(x => (x.split(” “)(0), x))
c. In Java language
Basically, Java doesn’t have a built-in function of tuple function. Therefore, we can use the Scala. It only sparks’ Java API has users create tuples.Tuple2 class. However by, by writing new Tuple2(elem1, elem2) in Java, we can create a new tuple. Moreover, we can access its relevant elements with the _1() and _2() methods.
Moreover, when we create paired RDDs in Spark, it is must to call special versions of spark’s functions in java. As an example, we can use mapToPair () function in place of the basic map() function.
Again, here using the first word as the keyword to create a Spark paired RDD,
PairFunction<String, String, String> keyData =
new PairFunction<String, String, String>() {
public Tuple2<String, String> call(String x) {
return new Tuple2(x.split(” “)[0], x);
}
};
JavaPairRDD<String, String> pairs = lines.mapToPair(keyData)Prepare yourself for Spark Interview
6. Spark Paired RDD Operations
a. Transformation Operations
Paired RDD allows the same transformation those are available to standard RDDs. Moreover, here also same rules apply from “passing functions to spark”. Also in Spark, there are tuples available in paired RDDs. Basically, we need to pass functions that operate on tuples, despite on individual elements. Let’s discuss some of the transformation methods below, like
groupByKey
The groupbykey operation generally groups all the values with the same key.
rdd.groupByKey()
reduceByKey(fun)
Here, the reduceByKey operation generally combines values with the same key.
add.reduceByKey( (x, y) => x + y)
Let’s discuss Spark GraphX Features
combineByKey(createCombiner, mergeValue, mergeCombiners, partitioner)
CombineByKey uses a different result type, then combine those values with the same key.
mapValues(func)
Even without changing the key, mapValues operation applies a function to each value of a paired RDD of spark.
rdd.mapValues(x => x+1)
keys()
Keys() operation generally returns a spark RDD of just the keys.
rdd.keys()
values()
values() operation generally returns an RDD of just the values.
rdd.values()
Let’s revise Spark MLlib Algorithms
sortByKey()
Similarly, the sortByKey operation generally returns an RDD sorted by the key.
rdd.sortByKey()
b. Action Operations
As similar as RDD transformations, there are same RDD actions available on spark pair RDD. However, paired RDDs also attains some additional actions of spark. Basically, those leverages the advantage of data which is of keyvalue nature. Let’s discuss some of the action methods below, like
countByKey()
Through countByKey operation, we can count the number of elements for each key.
rdd.countByKey()
collectAsMap()
Here, collectAsMap() operation helps to collect the result as a map to provide easy lookup.
rdd.collectAsMap()
lookup(key)
Moreover, it returns all values associated with the provided key.
rdd.lookup()
7. Conclusion
As a result, we have learned to work with Spark key-value data. Moreover, we have also learned how to create Spark Paired RDD and how to use the specialized Spark functions and operations. However, we hope this article answered all your questions regarding same. Still, if you feel to ask any query, feel free to ask in the comment section.
See also –
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





Hi Team,
Small correction.
Link to Spark – RDD Limitations is pointing to
https://data-flair.training/blogs/spark-paired-rdd/ and Spark – Paired RDD is pointing to https://data-flair.training/blogs/apache-spark-rdd-limitations/.
Thanks,
Sai Prasad.
Hi Sai Prasad,
Thanks for the observation, we have corrected our mistake and checked our sidebar (completely). Now, you can learn without any distractions.
Regards,
DataFlair
Hi team we have group by key and reduce by key both work are same except I/O, but what is the major difference between both of them, defiantly in production we are using reduce by key to reduce I/O, but if the group by key is there mean it has some unique work, please let me know.
groupByKey() will re-shuffle all the data & send to reducers to aggregate – that will lot of data flowing through N/W & have the risks of disk errors too.
reduceByKey() – will aggregate the data on each partition & shuffle the aggregated data to reducers for final aggregation. So less data flow through N/W.
Thanks for the contents. It is very informative.
One suggestion –
Write should try to reduce the usage of “moreover”, “however” and “although” with every other statements.
I found this pattern in several articles too before this one. This alters the flow of information/statements.
Thanks for the feedback. We will surely improve the writing pattern of the articles.