Limitations of Apache Spark – Ways to Overcome Spark Drawbacks
1. Objective
Some of the drawbacks of Apache Spark are there is no support for real-time processing, Problem with small file, no dedicated File management system, Expensive and much more due to these limitations of Apache Spark, industries have started shifting to Apache Flink– 4G of Big Data.
In this Apache Spark limitations tutorial, we will discuss these Apache Spark disadvantages and how to overcome these limitations of Apache Spark.
Limitations of Apache Spark – Ways to Overcome Spark Drawbacks
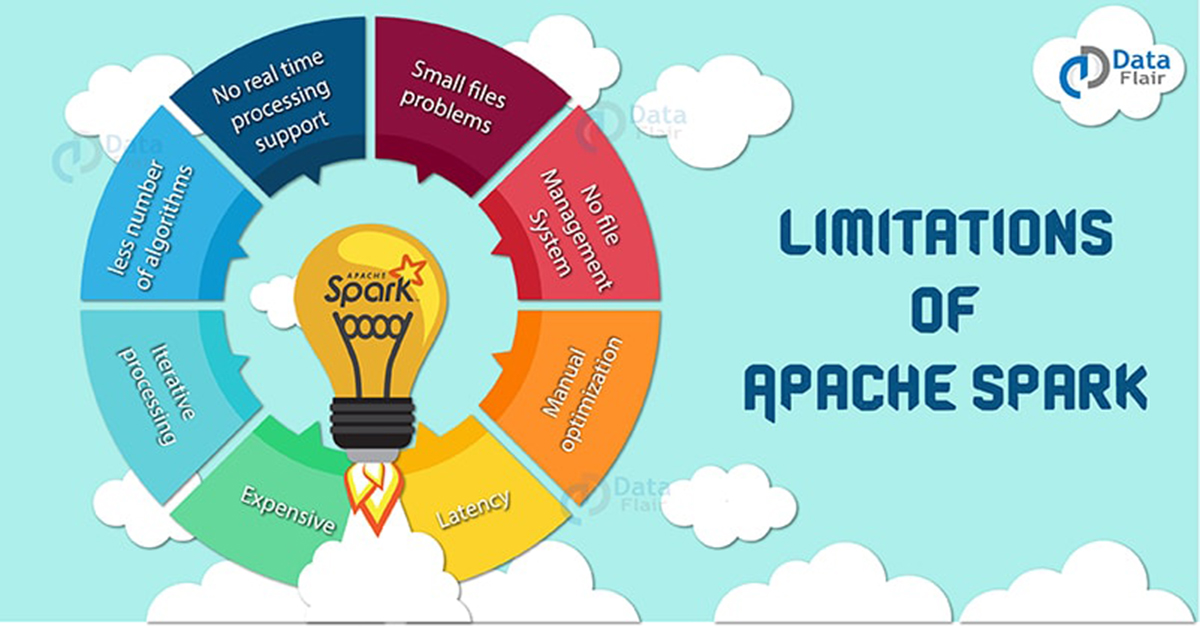
2. Limitations of Apache Spark
As we know Apache Spark is the next Gen Big data tool that is being widely used by industries but there are certain limitations of Apache Spark due to which industries have started shifting to Apache Flink– 4G of Big Data. Before we learn what are the disadvantages of Apache Spark, let us learn the advantages of Apache Spark.
So let us now understand Apache Spark problems and when not to use Spark.
a. No Support for Real-time Processing
In Spark Streaming, the arriving live stream of data is divided into batches of the pre-defined interval, and each batch of data is treated like Spark Resilient Distributed Database (RDDs). Then these RDDs are processed using the operations like map, reduce, join etc. The result of these operations is returned in batches. Thus, it is not real time processing but Spark is near real-time processing of live data. Micro-batch processing takes place in Spark Streaming.
b. Problem with Small File
If we use Spark with Hadoop, we come across a problem of a small file. HDFS provides a limited number of large files rather than a large number of small files. Another place where Spark legs behind is we store the data gzipped in S3. This pattern is very nice except when there are lots of small gzipped files. Now the work of the Spark is to keep those files on network and uncompress them. The gzipped files can be uncompressed only if the entire file is on one core. So a large span of time will be spent in burning their core unzipping files in sequence.
In the resulting RDD, each file will become a partition; hence there will be a large amount of tiny partition within an RDD. Now if we want efficiency in our processing, the RDDs should be repartitioned into some manageable format. This requires extensive shuffling over the network.
c. No File Management System
Apache Spark does not have its own file management system, thus it relies on some other platform like Hadoop or another cloud-based platform which is one of the Spark known issues.
d. Expensive
In-memory capability can become a bottleneck when we want cost-efficient processing of big data as keeping data in memory is quite expensive, the memory consumption is very high, and it is not handled in a user-friendly manner. Apache Spark requires lots of RAM to run in-memory, thus the cost of Spark is quite high.
e. Less number of Algorithms
Spark MLlib lags behind in terms of a number of available algorithms like Tanimoto distance.
f. Manual Optimization
The Spark job requires to be manually optimized and is adequate to specific datasets. If we want to partition and cache in Spark to be correct, it should be controlled manually.
g. Iterative Processing
In Spark, the data iterates in batches and each iteration is scheduled and executed separately.
h. Latency
Apache Spark has higher latency as compared to Apache Flink.
i. Window Criteria
Spark does not support record based window criteria. It only has time-based window criteria.
j. Back Pressure Handling
Back pressure is build up of data at an input-output when the buffer is full and not able to receive the additional incoming data. No data is transferred until the buffer is empty. Apache Spark is not capable of handling pressure implicitly rather it is done manually.
These are some of the major pros and cons of Apache Spark. We can overcome these limitations of Spark by using Apache Flink – 4G of Big Data.
3. Conclusion
Although Spark has many drawbacks, it is still popular in the market for big data solution. But there are various technologies that are overtaking Spark. Like stream processing is much better using Flink then Spark as it is real time processing. Learn feature wise differences between Apache Spark vs Apache Flink to understand which is better and how.
See Also-
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





Great article. Thanks for it. Do you have other examples of missing algorithms in Spark Mllib?