How to Overcome the Limitations of RDD in Apache Spark?
1. Objective
This Tutorial on the limitations of RDD in Apache Spark, walk you through the Introduction to RDD in Spark, what is the need of DataFrame and Dataset in Spark, when to use DataFrame and when to use DataSet in Apache Spark. To get the answer to these questions we will discuss various limitations of Apache Spark RDD and How we can use DataFrame and Dataset to overcome the Disadvantages of Spark RDD.
How to Overcome the Limitations of RDD in Apache Spark?
2. What is RDD in Apache Spark?
Before going to the disadvantages of RDD, let’s have a brief introduction to Spark RDD.
RDD is the fundamental data structure of Apache Spark. RDD is Read-only partition collection of records. It can only be created through deterministic operation on either: Data in stable storage, other RDDs, and parallelizing already existing collection in driver program(Follow this guide to learn the ways to create RDD in Spark). RDD is an immutable distributed collection of data, partitioned across nodes in the cluster that can be operated in parallel with a low-level API that offers transformations and actions.
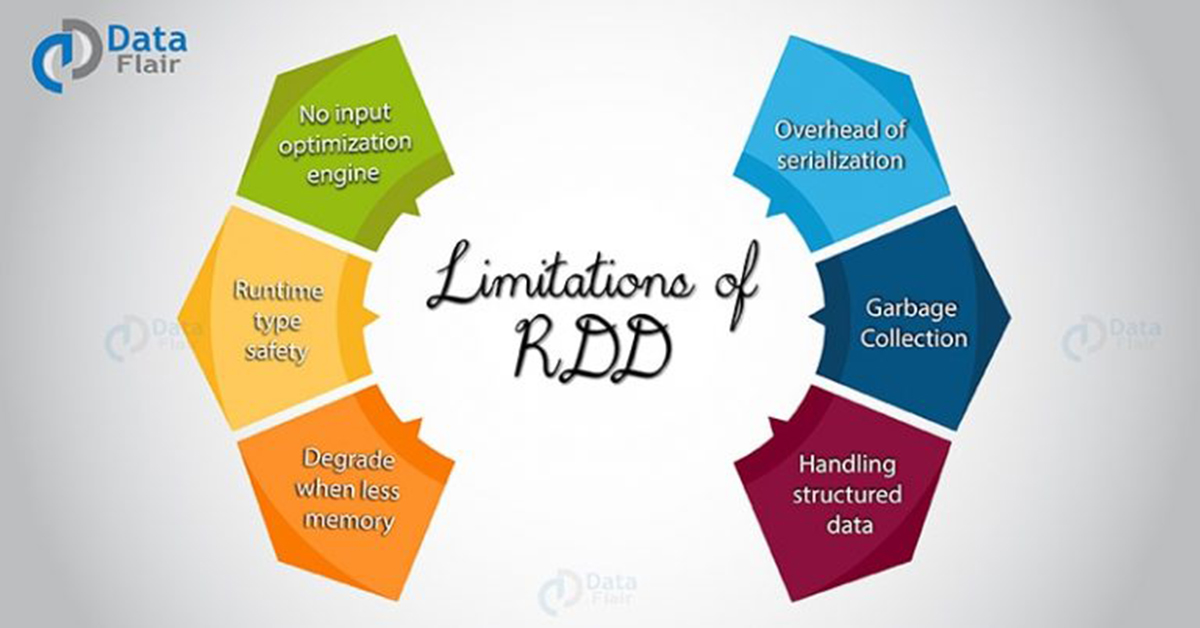
3. What are the Limitations of RDD in Apache Spark?
In this Section of Spark tutorial, we will discuss the problems related to RDDs in Apache Spark along with their solution.
i. No input optimization engine
There is no provision in RDD for automatic optimization. It cannot make use of Spark advance optimizers like catalyst optimizer and Tungsten execution engine. We can optimize each RDD manually.
This limitation is overcome in Dataset and DataFrame, both make use of Catalyst to generate optimized logical and physical query plan. We can use same code optimizer for R, Java, Scala, or Python DataFrame/Dataset APIs. It provides space and speed efficiency.
ii. Runtime type safety
There is no Static typing and run-time type safety in RDD. It does not allow us to check error at the runtime.
Dataset provides compile-time type safety to build complex data workflows. Compile-time type safety means if you try to add any other type of element to this list, it will give you compile time error. It helps detect errors at compile time and makes your code safe.
iii. Degrade when not enough memory
The RDD degrades when there is not enough memory to store RDD in-memory or on disk. There comes storage issue when there is a lack of memory to store RDD. The partitions that overflow from RAM can be stored on disk and will provide the same level of performance. By increasing the size of RAM and disk it is possible to overcome this issue.
iv. Performance limitation & Overhead of serialization & garbage collection
Since the RDD are in-memory JVM object, it involves the overhead of Garbage Collection and Java serialization this is expensive when the data grows.
Since the cost of garbage collection is proportional to the number of Java objects. Using data structures with fewer objects will lower the cost. Or we can persist the object in serialized form.
v. Handling structured data
RDD does not provide schema view of data. It has no provision for handling structured data.
Dataset and DataFrame provide the Schema view of data. It is a distributed collection of data organized into named columns.
So, this was all in limitations of RDD in Apache Spark. Hope you like our explanation.
4. Conclusion
As a result of RDD’s limitations, the need of DataFrame and Dataset emerged. Thus made the system more friendly to play with a large volume of data.
If you are willing to work with Spark 1.6.0 then the DataFrame API is the most stable option available and offers the best performance. However, the Dataset API is very promising and provides a more natural way to code.
If you like this post and think that I have missed some limitations of RDD in Apache Spark, So, please leave a comment in the comment box.
See Also-
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





first of all thanks for the blog .
Question –
Degrade when not enough memory block , how it is overcome in Dataframe or Dataset ?
The content of the paired RDD is having the RDD Limitations and Paired RDD concept is in RDD Limitations. correct me if I am wrong.
Hello Kiran,
No, you are not wrong, it was our mistake now, we have corrected it. You can learn Spark without any distractions.
Keep learning and keep visiting DataFlair