Create Spark Project in Scala With Eclipse Without Maven
1. Objective – Spark Scala Project
This step by step tutorial will explain how to create a Spark project in Scala with Eclipse without Maven and how to submit the application after the creation of jar. This Guide also briefs about the installation of Scala plugin in eclipse and setup spark environment in eclipse. Learn how to configure development environment for developing Spark applications in Scala in this tutorial.
If you are completely new to Apache Spark, I recommend you to read this Apache Spark Introduction Guide.

Create Spark project in Scala with Eclipse without Maven
2. Steps to Create the Spark Project in Scala
To create Spark Project in Scala with Eclipse without Maven follow the steps given below-
i. Platform Used / Required
- Operating System: Windows / Linux / Mac
- Java: Oracle Java 7
- Scala: 2.11
- Eclipse: Eclipse Luna, Mars or later
ii. Install Eclipse plugin for Scala
Open Eclipse Marketplace (Help >> Eclipse Marketplace) and search for “scala ide”. Now install the Scala IDE. Alternatively, you can download Eclipse for Scala.
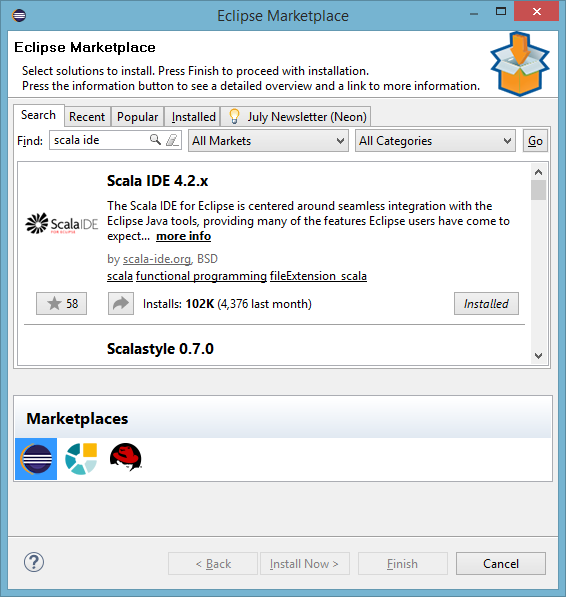
Install Eclipse plugin for Scala
iii. Create a New Spark Scala Project
To create a new Spark Scala project, click on File >> New >> Other
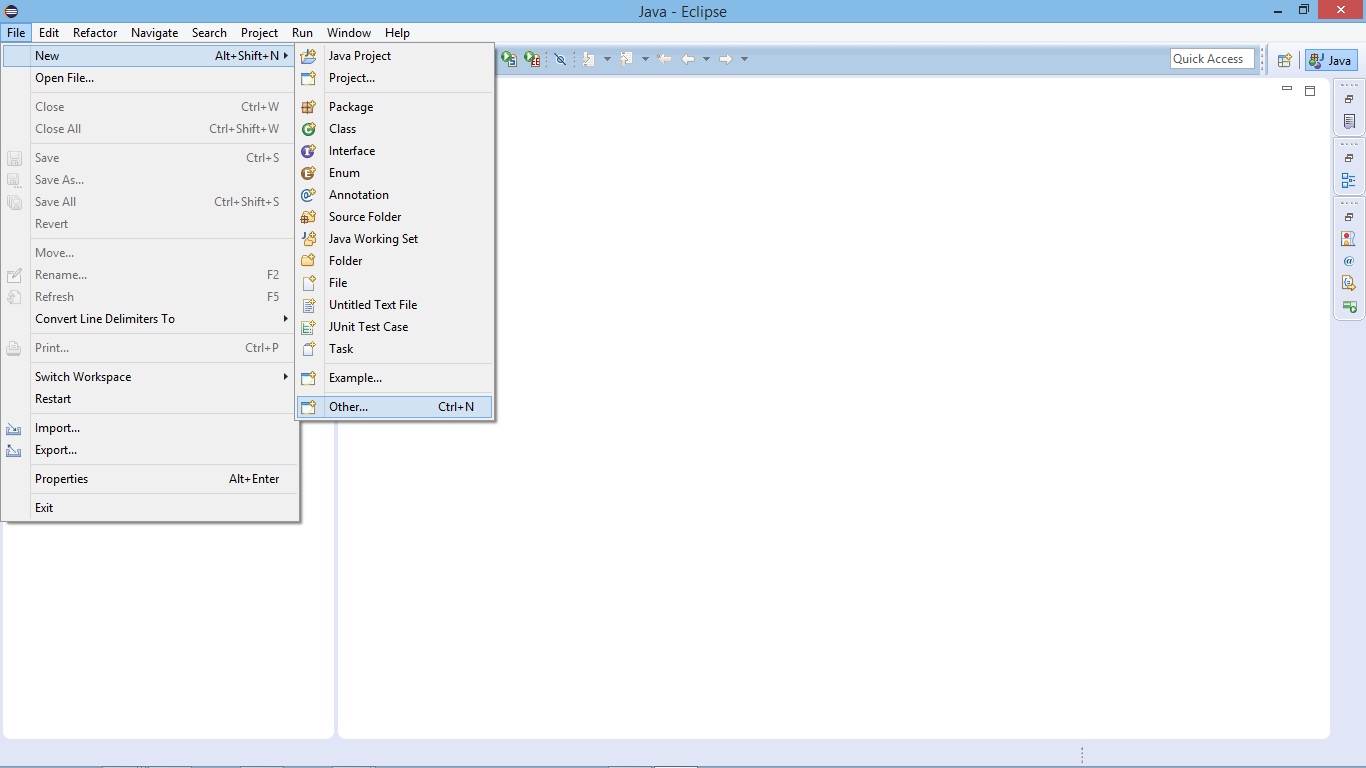
Create a New Spark Scala Project
Select Scala Project:
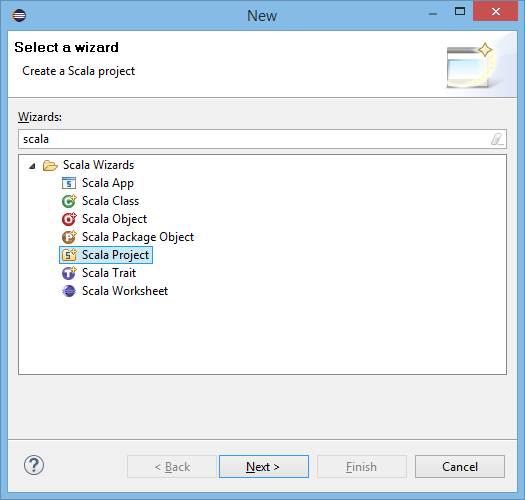
Select Scala Project
Supply Project Name:
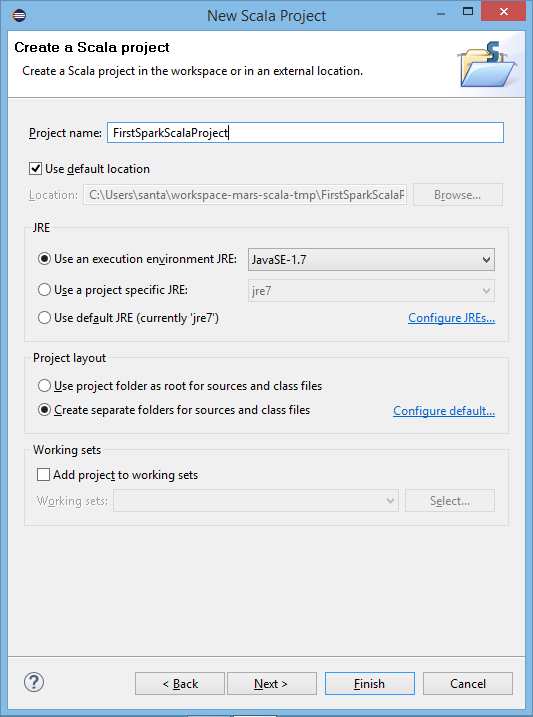
Supply Project Name
iv. Create New Package
After creating the project, now create a new package.
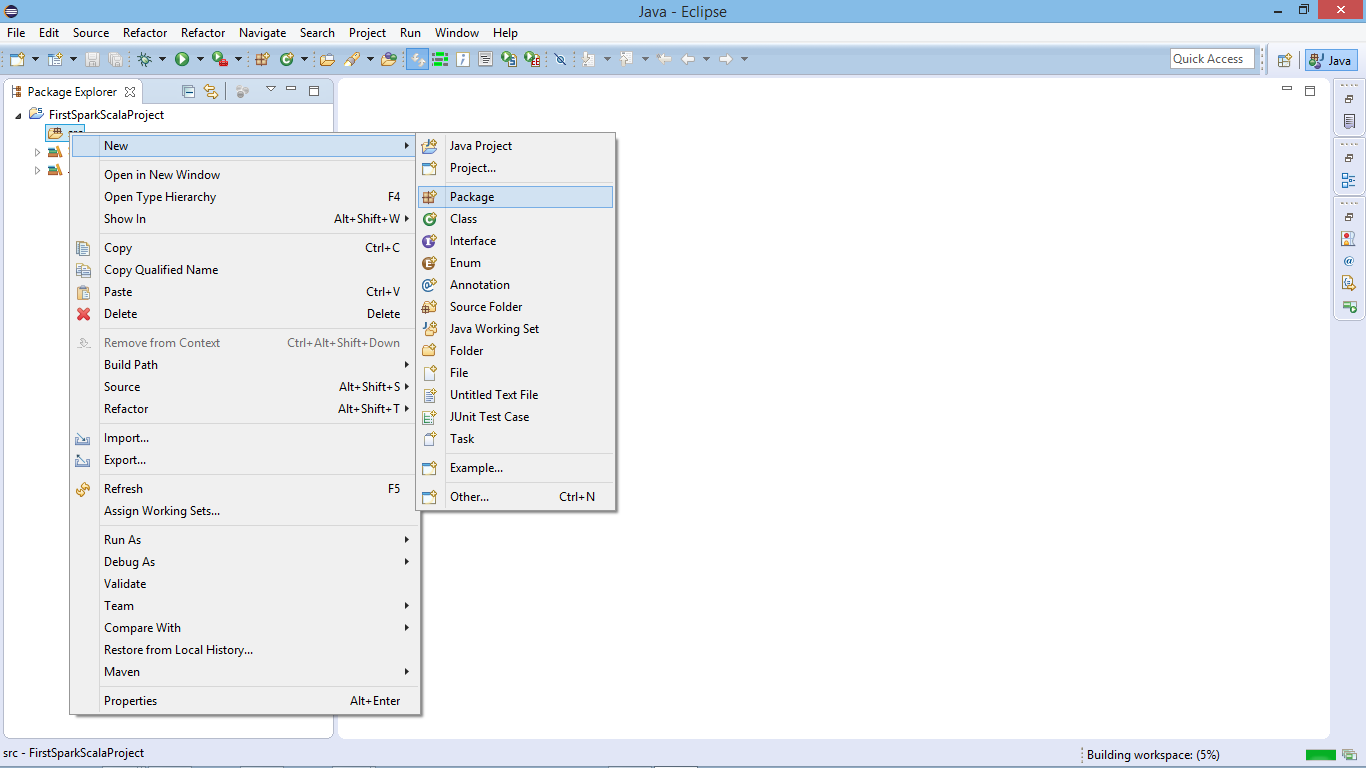
Create New Package
Supply Package Name:
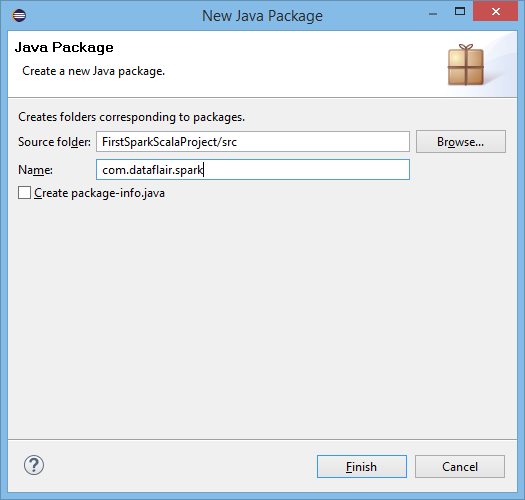
Supply Package Name
v. Create a New Scala Object
Now create a new Scala Object to develop Scala program for Spark application
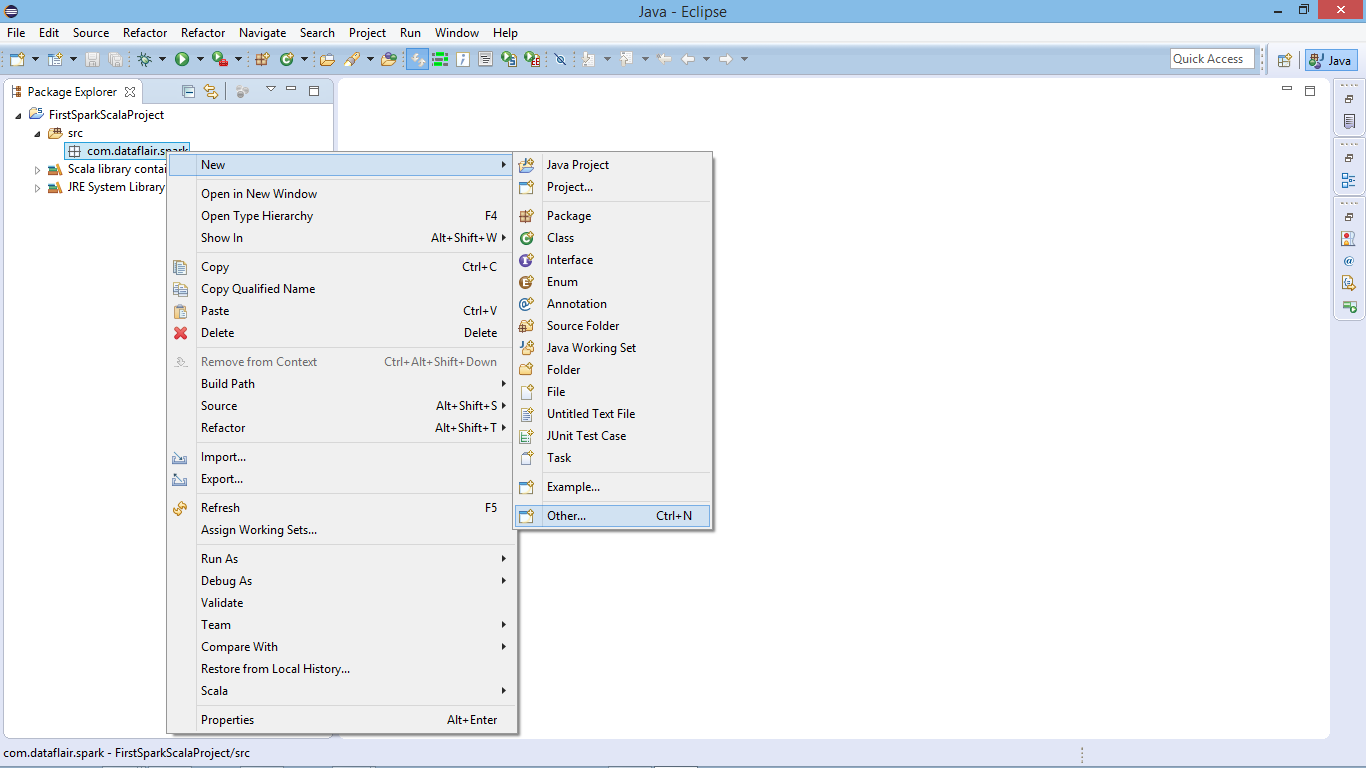
Create a new Scala Object to develop Scala program for Spark application
Select Scala Object:
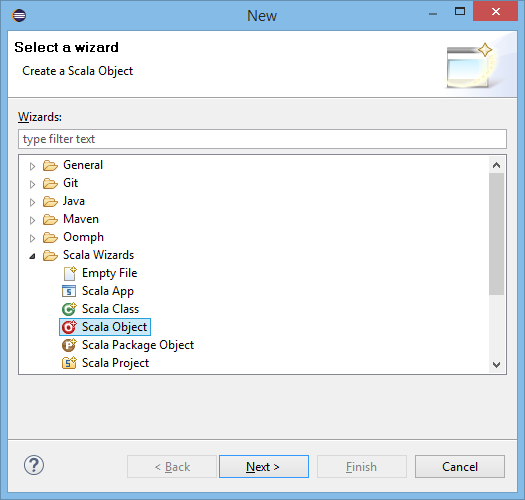
Select Scala Object
Supply Object Name:
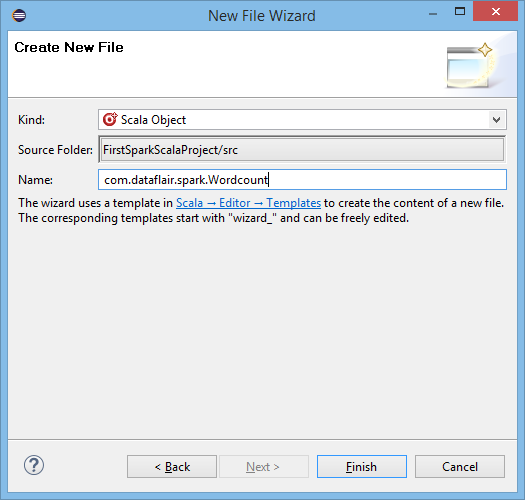
Supply Object Name:
vi. New Scala Object in Editor
Scala object is ready now we can develop our Spark wordcount code in Scala-
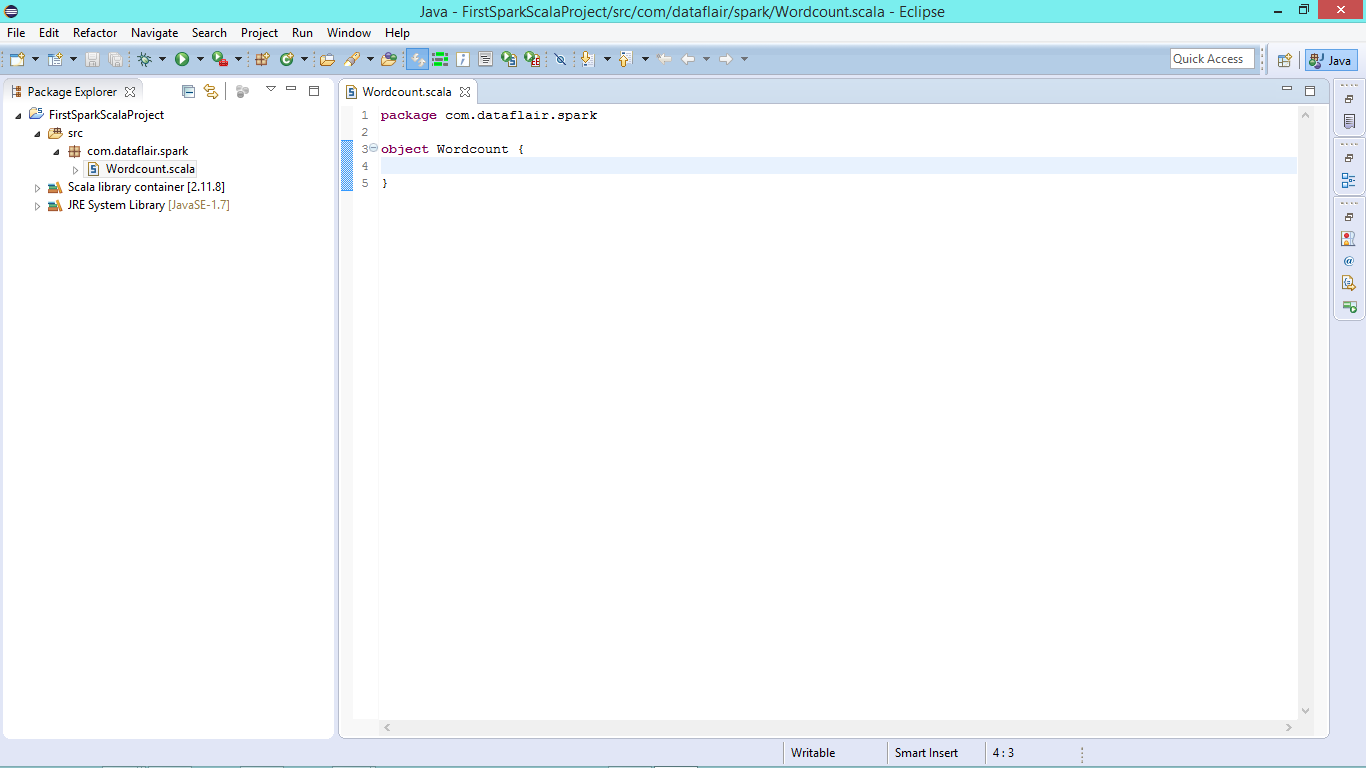
New Scala Object in Editor to create Spark Application
vii. Copy below Spark Scala Wordcount Code in Editor
[php]
package com.dataflair.spark
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Wordcount {
def main(args: Array[String]) {
//Create conf object
val conf = new SparkConf()
.setAppName(“WordCount”)
//create spark context object
val sc = new SparkContext(conf)
//Check whether sufficient params are supplied
if (args.length < 2) {
println(“Usage: ScalaWordCount <input> <output>”)
System.exit(1)
}
//Read file and create RDD
val rawData = sc.textFile(args(0))
//convert the lines into words using flatMap operation
val words = rawData.flatMap(line => line.split(” “))
//count the individual words using map and reduceByKey operation
val wordCount = words.map(word => (word, 1)).reduceByKey(_ + _)
//Save the result
wordCount.saveAsTextFile(args(1))
//stop the spark context
sc.stop
}
}[/php]
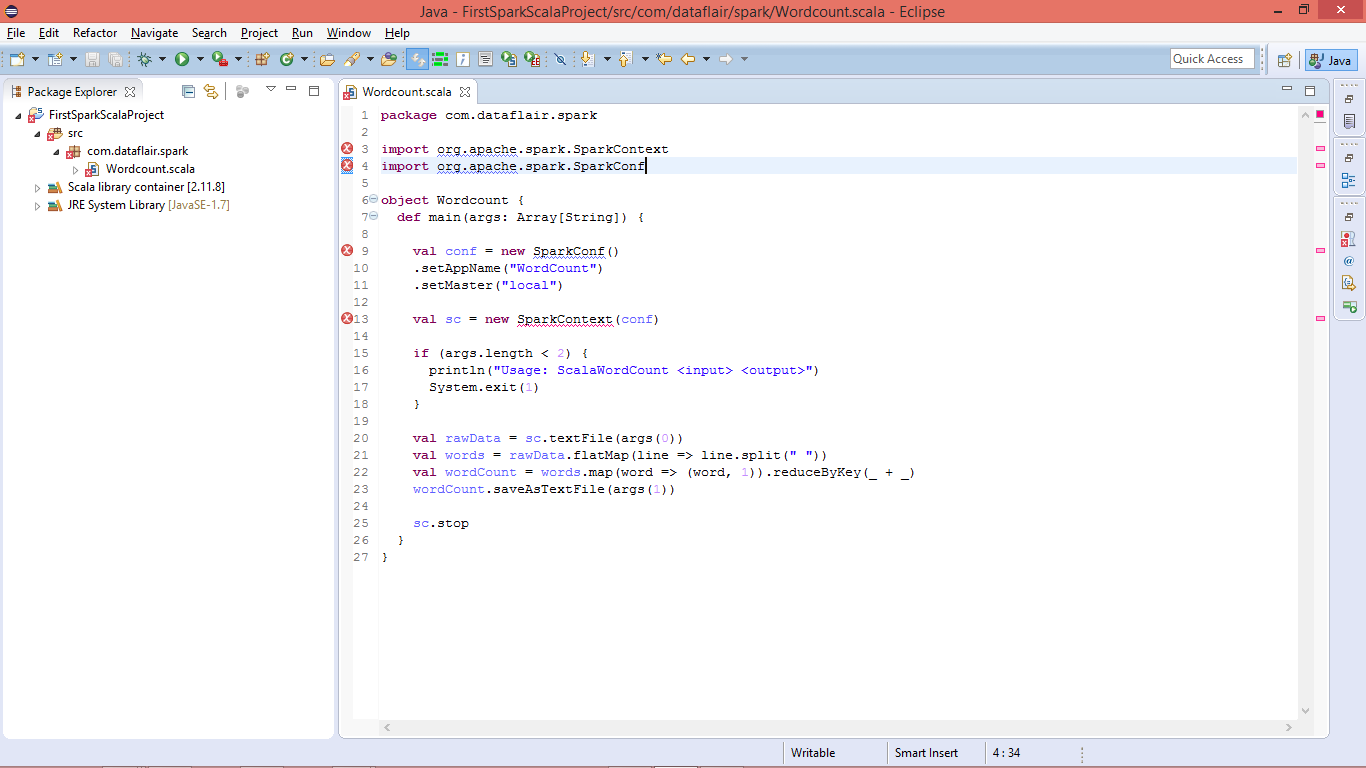
Spark Scala WordCount Code in Editor
You will see lots of error due to missing libraries.
viii. Add Spark Libraries
Configure Spark environment in Eclipse: Right click on project name >> build path >> Configure Build Path
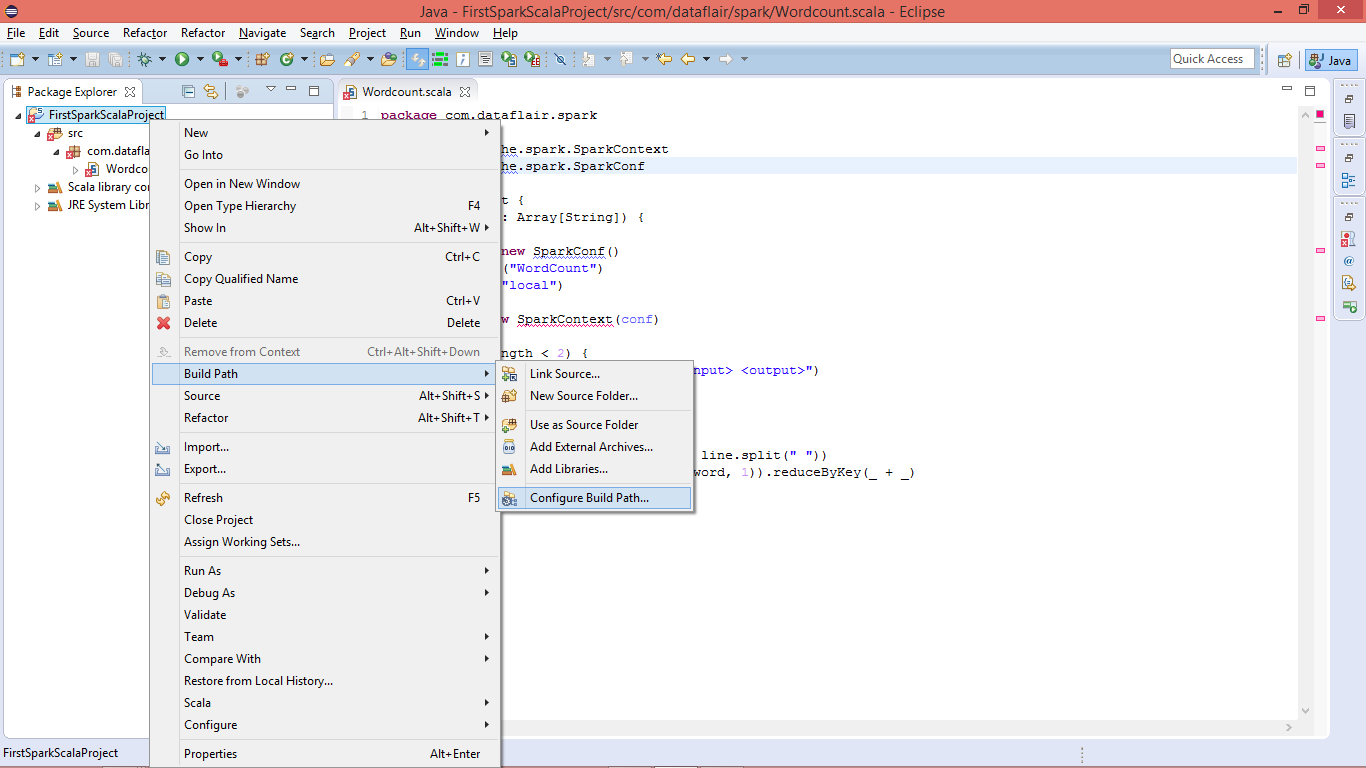
Configure Spark environment in Eclipse
Add the External Jars:
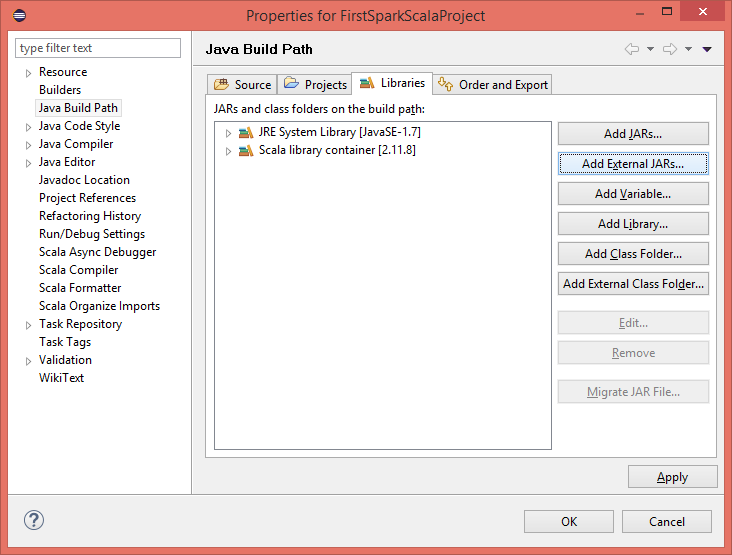
Add the External Jars
ix. Select Spark Jars and insert
You should have spark setup available in developing environment, it will be needed for spark libraries.
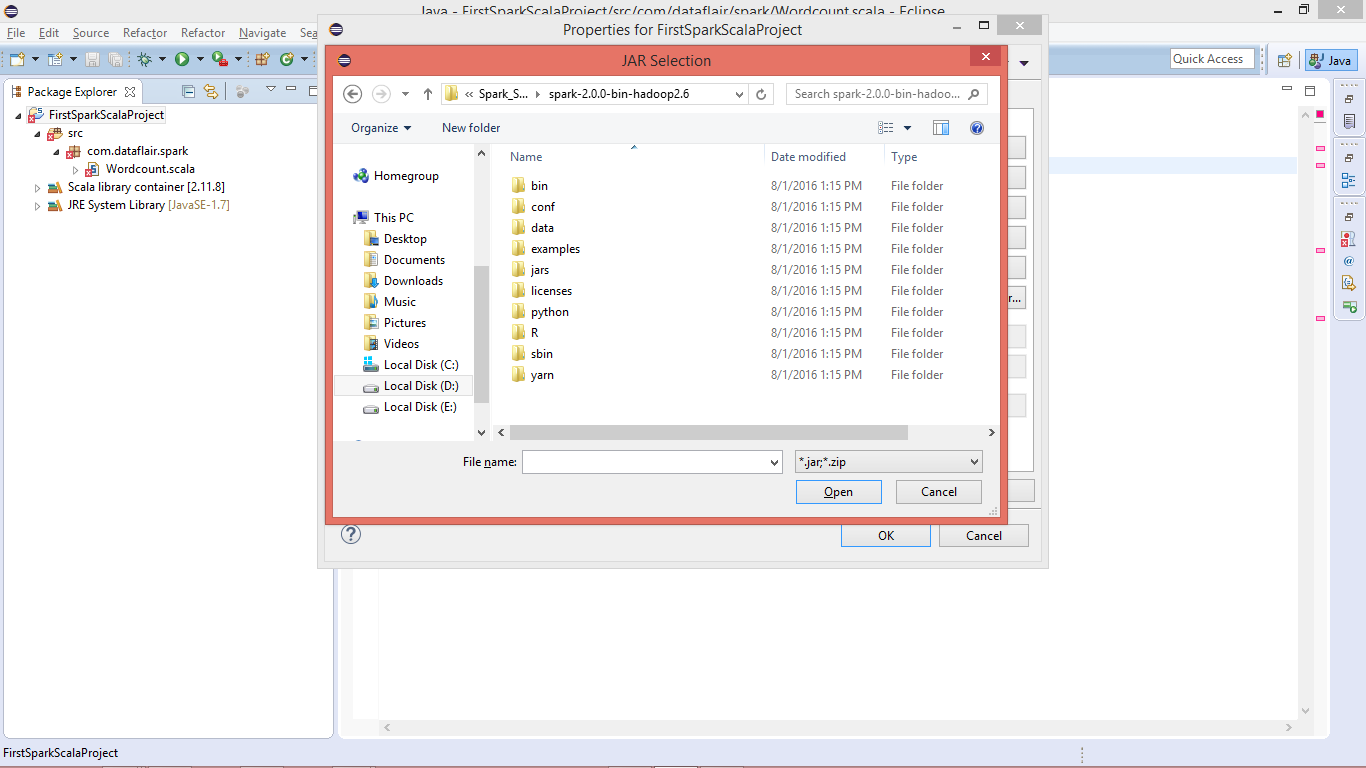
Select Spark Jars and insert
Go to “Spark-Home >> jars” and select all the jars:
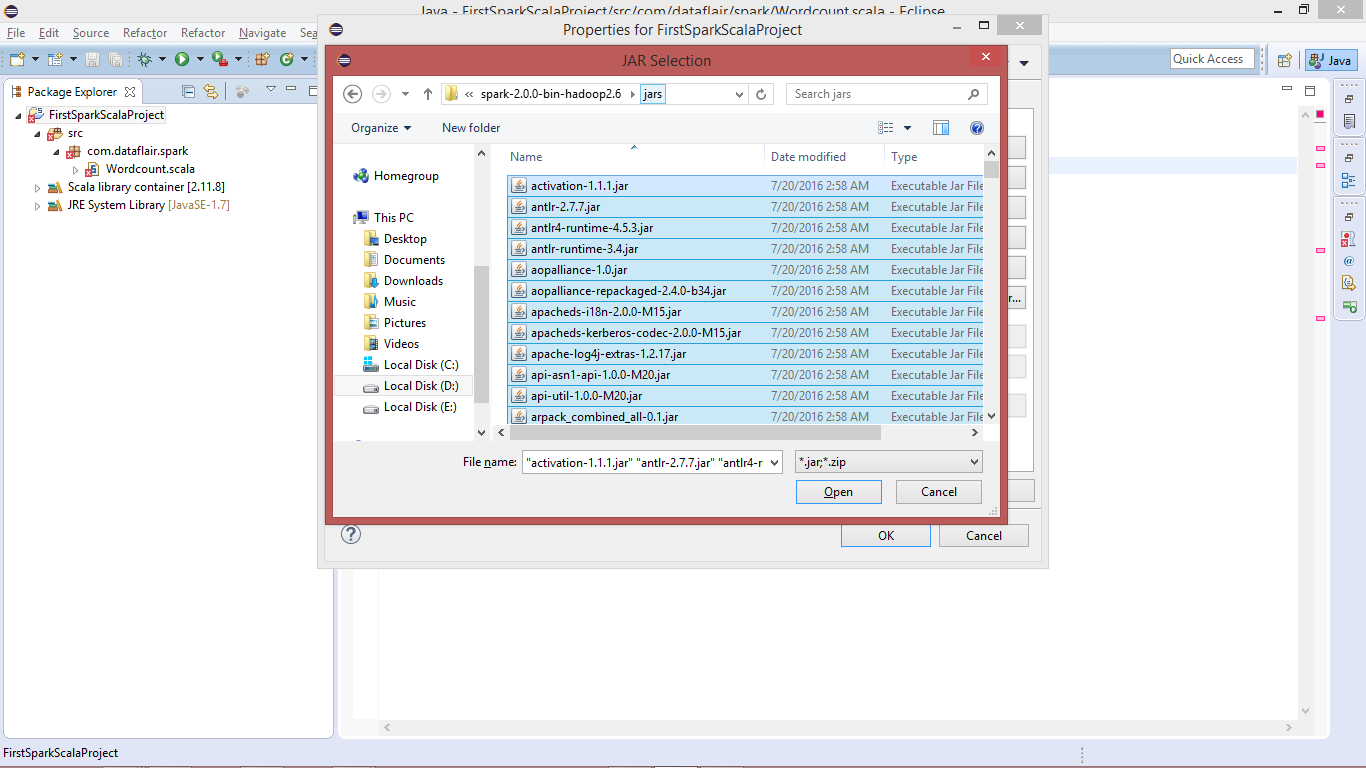
select all the jars
Import the selected jar:
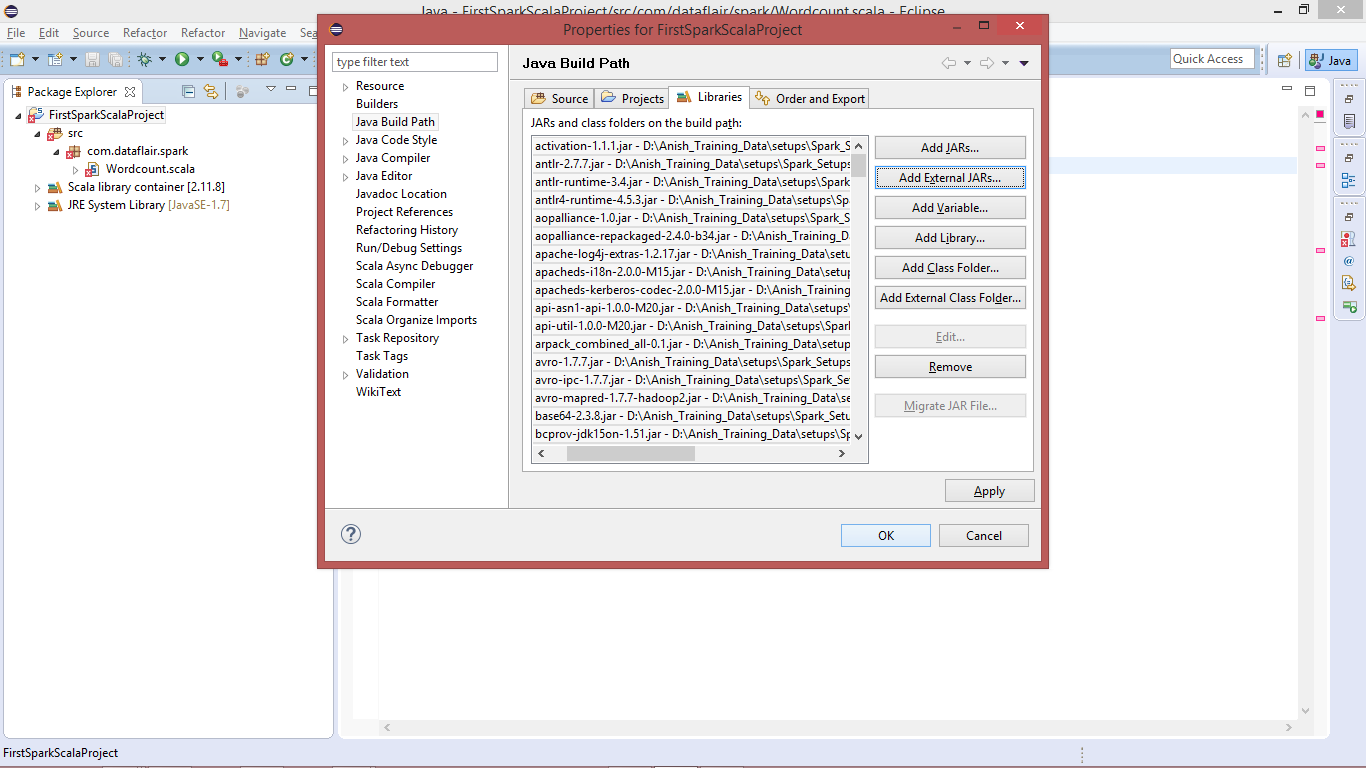
Import the selected jar
x. Spark Scala Word Count Program
After importing the libraries all the errors will be removed.
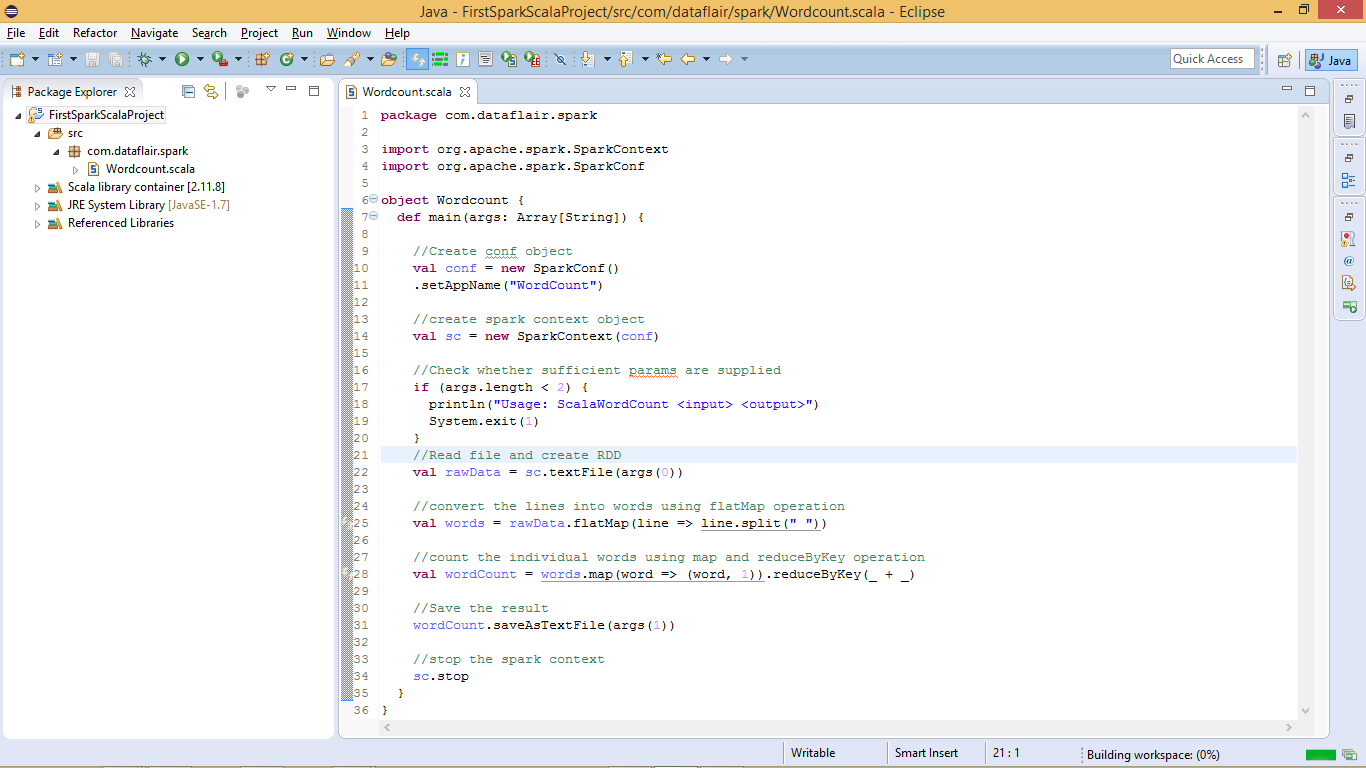
Spark WordCount Program in Scala
We have successfully created Spark environment in Eclipse and developed Spark Scala program. Now let’s deploy the Spark job on Linux, before deploying/running the application you must have Spark Installed.
Follow this links to install Apache Spark on single node cluster or on the multi-node cluster.
xi. Create the Spark Scala Program Jar File
Before running created Spark word count application we have to create a jar file. Right click on project >> export
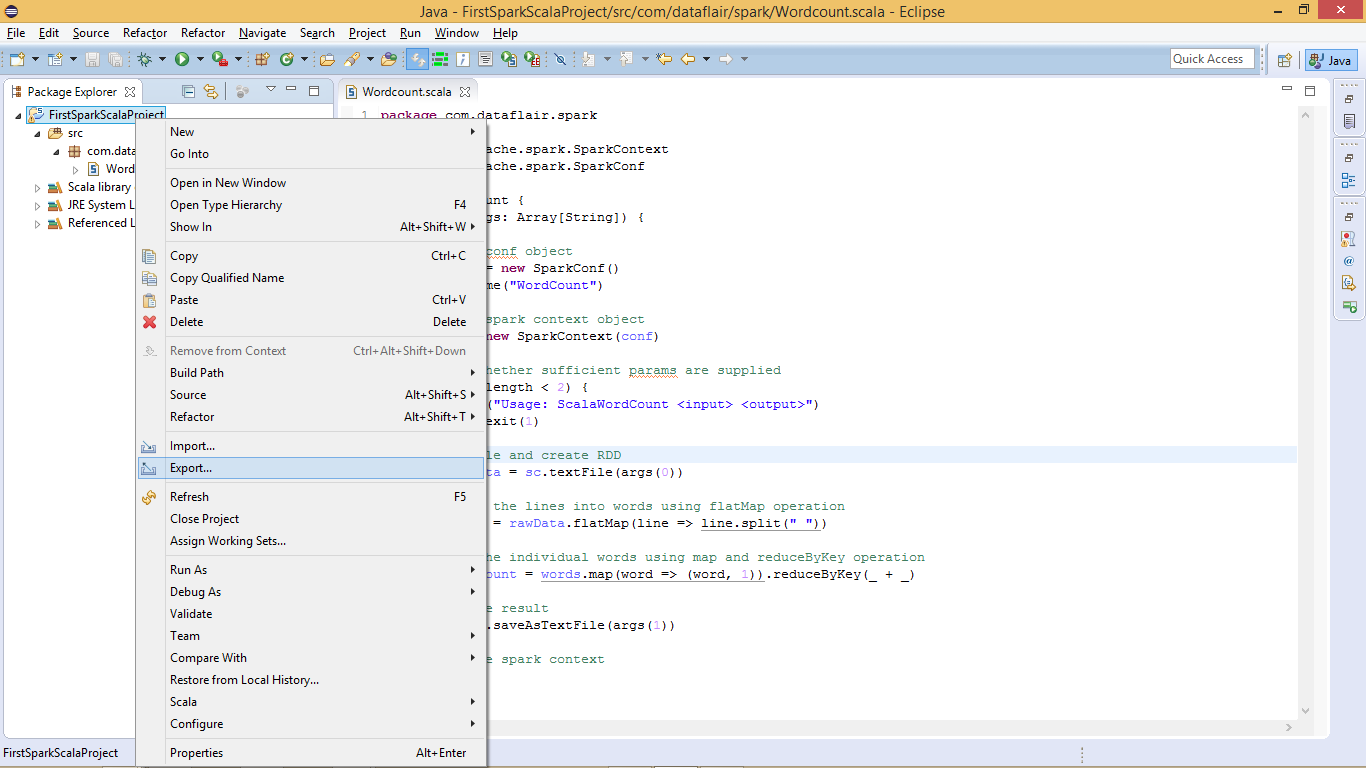
Create the Spark Scala Program Jar File
Select Jar-file Option to Export:
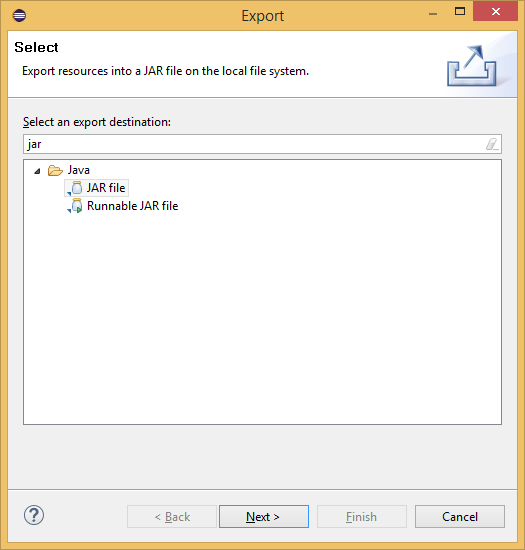
Select Jar-file Option to Export
Create the Jar file:
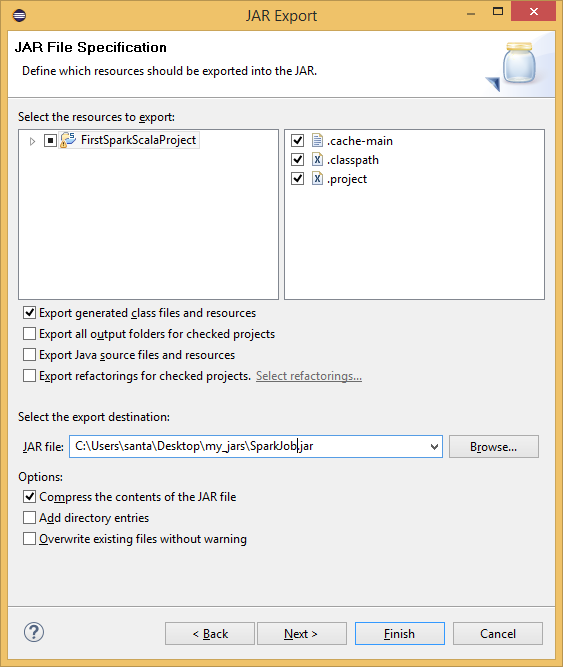
Create the Jar file
The jar file for the Spark Scala application has been created, now we need to run it.
xii. Go to Spark Home Directory
Login to Linux and open terminal. To run Spark Scala application we will be using Ubuntu Linux. Copy the jar file to Ubuntu and create one text file, which we will use as input for Spark Scala wordcount job.
cd spark home directory
xiii. Submit Spark Application using spark-submit script
To submit the Spark application using below command:
bin/spark-submit --class <Qualified-Class-Name> --master <Master> <Path-Of-Jar-File> <Input-Path> <Output-Path>
bin/spark-submit --class com.dataflair.spark.Wordcount --master local ../sparkJob.jar ../wc-data output
Let’s understand above command:
- bin/spark-submit: To submit Spark Application
- –class: To specify the class name to execute
- –master: Master (local / <Spark-URI> / yarn)
- <Jar-Path>: The jar file of application
- <Input-Path>: Location from where input data will be read
- <Output-Path>: Location where Spark application will write output
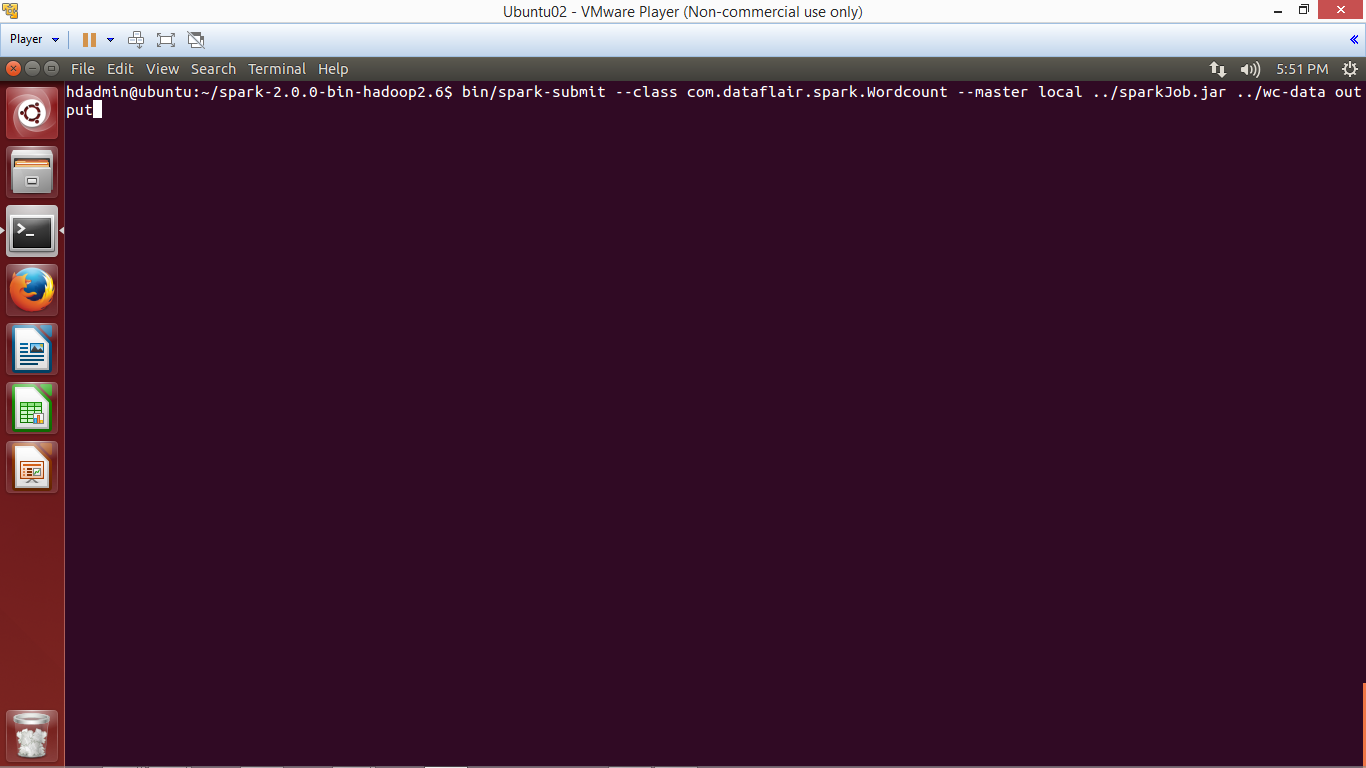
Submit Spark Application using spark-submit script
Submit Spark Application using spark-submit script
The application has been completed successfully, now browse the result.
xiv. Browse the result
Browse the output directory and open the file with name part-xxxxx which contains the output of the application.
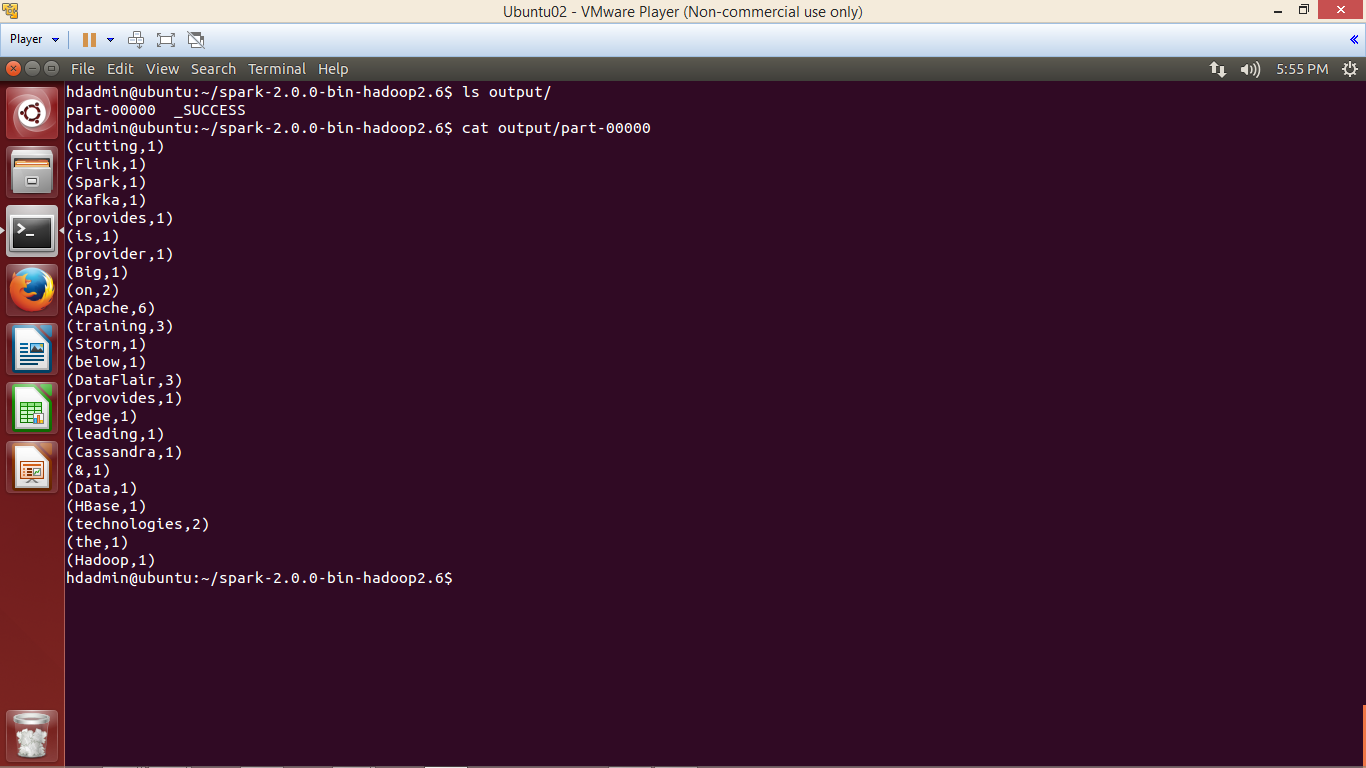
spark wordcount job success
We have successfully created Spark project in Scala and deployed on Ubuntu.
To play with Spark First learn RDD, DataFrame, DataSet in Apache Spark and then refer this Spark shell commands tutorial to practically implements Spark functionalities.
See Also-
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





What I like about this article is that it has not missed a step (in my eyes, at least). If hand-holding the hesitant starters in the world of Apache Spark, has been the objective, then you have achieved it. Good job!
Hi Nirmalya,
Thanks for such nice words. The feedback comes from our loyal readers, build our confidence and inspire us to bring you even better content.
We hope you are exploring other Spark blogs as well.
Regards,
Data-Flair
I’m gonna say to my little brother, that he should also visit this web site on regular basis to obtain updates from hottest reports.
Hii Becky,
Thanks for visiting Data Flair. We are happy to hit the mark for you and your brother. It seems that you liked and understood how to create the Spark Project in Scala. You should share this Spark Knowledge but not only with your brother, with all who wants to explore the career in Spark. Our Site Data Flair is continuously working for the sake of our loyal readers.
I am not able to create jar. it says
JAR creation failed. See details for additional information.
Class files on classpath not found or not accessible for: ‘SparkApplication/src/com/spark/employee/Maxwages.scala’
Dear Udit,
It seems there is compilation error in your program. Spark is not able to create class file when compilation error is there.
Excellent page to setup the Scala + Spark + Eclipse
Gr8 Work
Glad to see your review on Spark Project in Scala. Our team is continuously working for readers like you. You must read more Spark blogs on our website and let us know if the content helps you.
getting error while running with spark-submit
exception in thread main java.lang.nosuchmethodexception
Make sure you use scala version compatible with your spark version.
Great Post
Dileep thanks a lot, for taking time to post the review on Spark Scala Project. Your words are valuable to us. Update yourself with our new Spark blogs. Keep learning, keep sharing.
Great Post described in simple steps
Hii Dileep
Thank you for sharing such a positive experience. Keep learning and keep visiting Data Flair.
Maven should be given the preference as it is the preferred way.
Hii Mohit,
Thank you for catching this Maven query for Spark Scala Project.
Maven is quite a popular way, will post another article detailing the steps: how to create a Spark Scala project using Maven. Till then keep visiting Data Flair and keep learning.
Great! helped a lot.
Thanks Nikita for such nice words. We glad to see that our explanation of the process of creating a Spark Scala Project helps you. We want you to learn more about Spark. Here we are providing the best Spark guide for you:
https://data-flair.training/blogs/apache-spark-performance-tuning/
This Spark scala Project process is very helpful and very detailed.
Thanks very much.
Aliaa, Thank you so much for taking the time to write this excellent review. We regularly post the simply written helpful articles on Spark. You can select the spark category for more on Spark. Good luck with the site.
clearly explained how to create a jar in eclipse, if possible pls explain in intellij as well
Hii Venu,
Glad you understand our explained tutorial of creating Jar in Spark Scala Project. Soon, we will post another tutorial about the project creation in IntelliJ for a Spark & Scala project. Get notified with our new blogs, keep checking the site. You can also check our new blog, hope this helps to clear your Spark Concept
https://data-flair.training/blogs/scala-spark-shell-commands/
Do the same commands apply when running spark-shell on Windows cmd? If not how do I run this jar file using Spark-submit on Windows cmd?
Yes Vaibhav, all the mentioned steps/commands in Spark Scala Project work on Windows. You can set up the complete Spark Scala environment on Windows. If you want to explore more in Spark check this link:
https://data-flair.training/blogs/apache-spark-sql-dataframe-tutorial/
after importing the libraries stiil errors are there….please help
Pravin, please post the error, will look into it.
Excellent post.
Just a small correction for creation of conf object.
val conf = new SparkConf().setAppName(“WordCount”).setMaster(“local[*]”)
Hello sir
Your this tutorial is very good but in last step we past jar file in spark home dir then use spark submit command for run the program. Here i am facing the problem. sir plz can you this make this tutorial on video. By video we can understand where we doing something wrong.
Please sir help the student. You Blog is very good
hello sir
Your tutorials are very good.This is also a good tutorial. When i was creating project in scala without using maven in the last step where we using jar file does not conf. So please sir can you convert this tutorial in video in this way we can more understand how to conf spark scala through eclipse to ubuntu
Thanks if you can help us
Hii Alka, you commented on this Spark Scala Project, so we are grateful for your loyal feedback telling us that our current approach on Spark requires a video tutorial to explain the things to our readers. We will work on it so that you can get an easy understanding of Spark Scala. I can see that you are very curious to learn more about Spark, just follow our site for best Spark Tutorials.
Used below command for execution:
spark-submit –class WordCount –master local /vinyas/Jars/WordCount.jar
But getting error:
java.lang.ClassNotFoundException: WordCount
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
What might be the reason?
Hii Vinyas, check the below solutions your error on Spark Scala Project
There could be the following 2 issues:
Either you are mentioning the wrong class name, make sure to mention the fully qualified class name. Or there are compile-time issues in your program. Check this and still if you are getting any error do let us know.
Hi,
I have also got the same error. On compiling in eclipse i am getting below error:
Error: Main method not found in class com.dataflair.spark.Wordcount, please define the main method as:
public static void main(String[] args)
or a JavaFX application class must extend javafx.application.Application
The shown program is in Scala. public static void main(String[] args) is Java style of coding.
If you are getting the same error, look for following issues:
– Use Scala 2.11 (by default Scala 2.12 is shipped with Eclipse)
– Check the package name and class name
– look at the problems tab in Eclipse (next to console)
This one is great. Could you please explain how to run the above spark program in hadoop? The same .jar file made, not using spark-shell.
Rajat Saha, thanks a lot for such loyal comment and good words.
You can run the Spark program on Hadoop, you need to mention the input and output path of HDFS URI and mention the master as yarn. If you are satisfied with this, leave a remark.
Hi, I did everything like above but get the next problem: Failed to load com.dataflair.spark.Wordcount
I already tried to clean and rebuild the project but still doesn’t working. Where can the Problem lie? Thanks in advence
Hi Sir ,
its great tutorial which helped me in learning spark -scala-eclipse as a beginner.
I am getting an error as output directory already exists.
can you please help me with that.
spark-submit –class com.smruti.scala.Wordcount –master local C:\Users\irhake\Desktop\ApacheSpark_POC\jarFol
der\SparkJob.jar C:\Users\irhake\Desktop\ApacheSpark_POC\sample.txt C:\Users\irhake\Desktop\ApacheSpark_POC\output
“main” org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/C:/Users/irhake/Deskto
utput/op.txt already exists
Please supply a new directory name (path).
For each application / job we need to supply a new output directory which must not exist, alternatively, you can delete the existing directory.
Hi, Thank you for the nice tutorial, I am able to make the sample working perfectly.
But the completed application shown in master:8080 is always zero. How to make them working?
Hi JN,
Thanks for commenting on the Spark Scala project. I think you have installed Spark Standalone Mode and running the application on Local Mode. It is recommended to run the application in Standalone mode to listed application on –master spark://IP-ADDRESS:PORT.
Hope, it will help you!
Regards,
DataFlair
Hi DataFlair, Thanks for the fast reply . I tried to ran as you told me, but it is showing FileNotFound Excception.
I executed like this –> spark-submit –class com.dataflair.spark.Wordcount –master spark://172.31.38.56:7077 test1.jar /home/ubuntu/scalaapp/wc-data output
I am getting this error–> Caused by: java.io.FileNotFoundException: File file:/home/ubuntu/scalaapp/wc-data does not exist
wc-data is available in the specified path and the created output folder is empty
Hello JN
We have tested, it’s working fine:
spark-submit –master spark://ubuntu:7077 –class com.dataflair.spark.Wordcount ../sparkwc.jar /home/dataflair/inp /home/dataflair/out
Your error is clearly saying, the file wc-data doesn’t exist, please give the correct path.
Hi,
I followed the example step-by-step and it was nicely written. New to spark and having some issues if you can help,
I am doing this in windows, and I installed Spark — I can start spark-shell, and it is giving me as below:
Spark context Web UI available at ip-address : port,
When I’m doing as below for above example:
spark-submit –class com.dataflair.spark.Wordcount –master spark: //: SparkJob.jar wc-data.txt output
It is giving me as below:
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
log4j:WARN No appenders could be found for logger (org.apache.spark.deploy.SparkSubmit$$anon$2).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
no output file is getting generated.
I started spark-shell in different command prompt window, it starts spark and ends with scala shell.
and I opened separate cmd prompt to run spark-submit.
Please if you can help. thanks
Hi Ravi,
The above example has been tested on Ubuntu, I recommend you to run on Ubuntu.
BTW, it’s supported on Windows as well, if no output file is generated, it seems there is some issue, please scan the logs and post the same.
Thank you for the article.Your content has been helpful in many cases.
I am new to apache spark, Just started learning. I would like to learn about spark using java. pls guide for the same