Apache Hive – In Depth Hive Tutorial for Beginners
Apache Hive is an open source data warehouse system built on top of Hadoop Haused for querying and analyzing large datasets stored in Hadoop files. It process structured and semi-structured data in Hadoop.
This Apache Hive tutorial explains the basics of Apache Hive & Hive history in great details. In this hive tutorial, we will learn about the need for a hive and its characteristics. This Hive guide also covers internals of Hive architecture, Hive Features and Drawbacks of Apache Hive.
So, let’s start Apache Hive Tutorial.
What is Hive?
Apache Hive is an open source data warehouse system built on top of Hadoop Haused for querying and analyzing large datasets stored in Hadoop files.
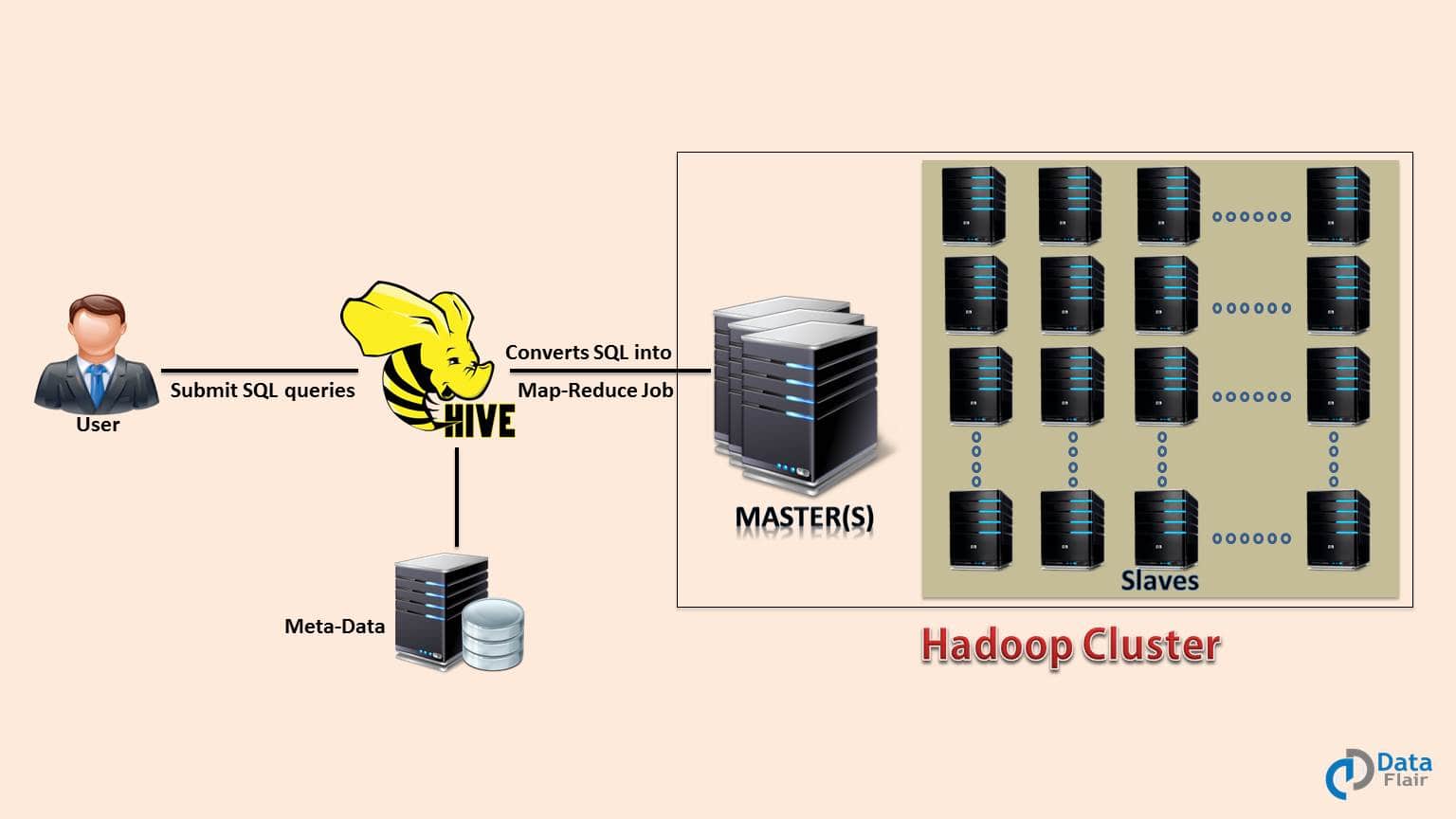
Initially, you have to write complex Map-Reduce jobs, but now with the help of the Hive, you just need to submit merely SQL queries. Hive is mainly targeted towards users who are comfortable with SQL.
Hive use language called HiveQL (HQL), which is similar to SQL. HiveQL automatically translates SQL-like queries into MapReduce jobs.
Hive abstracts the complexity of Hadoop. The main thing to notice is that there is no need to learn java for Hive.
The Hive generally runs on your workstation and converts your SQL query into a series of jobs for execution on a Hadoop cluster. Apache Hive organizes data into tables. This provides a means for attaching the structure to data stored in HDFS.
Apache History Hive
Data Infrastructure Team at Facebook developed Hive. Apache Hive is also one of the technologies that are being used to address the requirements at Facebook. It is very popular with all the users internally at Facebook.
It is being used to run thousands of jobs on the cluster with hundreds of users, for a wide variety of applications.
Apache Hive-Hadoop cluster at Facebook stores more than 2PB of raw data. It regularly loads 15 TB of data on a daily basis.
Now it is being used and developed by a number of companies like Amazon, IBM, Yahoo, Netflix, Financial Industry Regulatory Authority (FINRA) and many others.
Why Apache Hive?
Let’s us now discuss the need of Hive-
Facebook had faced a lot of challenges before the implementation of Apache Hive. Challenges like the size of the data being generated increased or exploded, making it very difficult to handle them. The traditional RDBMS could not handle the pressure.
As a result, Facebook was looking out for better options. To overcome this problem, Facebook initially tried using MapReduce. But it has difficulty in programming and mandatory knowledge in SQL, making it an impractical solution.
Hence, Apache Hive allowed them to overcome the challenges they were facing.
With Apache Hive, they are now able to perform the following:
- Schema flexibility and evolution
- Tables can be portioned and bucketed
- Apache Hive tables are defined directly in the HDFS
- JDBC/ODBC drivers are available
Apache Hive saves developers from writing complex Hadoop MapReduce jobs for ad-hoc requirements. Hence, hive provides summarization, analysis, and query of data.
Hive is very fast and scalable. It is highly extensible. Since Apache Hive is similar to SQL, hence it becomes very easy for the SQL developers to learn and implement Hive Queries.
Hive reduces the complexity of MapReduce by providing an interface where the user can submit SQL queries. So, now business analysts can play with Big Data using Apache Hive and generate insights.
It also provides file access on various data stores like HDFS and HBase. The most important feature of Apache Hive is that to learn Hive we don’t have to learn Java.
Hive Architecture
After the introduction to Apache Hive, Now we are going to discuss the major component of Hive Architecture. The Apache Hive components are-
- Metastore – It stores metadata for each of the tables like their schema and location. Hive also includes the partition metadata. This helps the driver to track the progress of various data sets distributed over the cluster. It stores the data in a traditional RDBMS format. Hive metadata helps the driver to keep a track of the data and it is highly crucial. Backup server regularly replicates the data which it can retrieve in case of data loss.
- Driver – It acts like a controller which receives the HiveQL statements. The driver starts the execution of the statement by creating sessions. It monitors the life cycle and progress of the execution. Driver stores the necessary metadata generated during the execution of a HiveQL statement. It also acts as a collection point of data or query result obtained after the Reduce operation.
- Compiler – It performs the compilation of the HiveQL query. This converts the query to an execution plan. The plan contains the tasks. It also contains steps needed to be performed by the MapReduce to get the output as translated by the query. The compiler in Hive converts the query to an Abstract Syntax Tree (AST). First, check for compatibility and compile-time errors, then converts the AST to a Directed Acyclic Graph (DAG).
- Optimizer – It performs various transformations on the execution plan to provide optimized DAG. It aggregates the transformations together, such as converting a pipeline of joins to a single join, for better performance. The optimizer can also split the tasks, such as applying a transformation on data before a reduce operation, to provide better performance.
- Executor – Once compilation and optimization complete, the executor executes the tasks. Executor takes care of pipelining the tasks.
- CLI, UI, and Thrift Server – CLI (command-line interface) provides a user interface for an external user to interact with Hive. Thrift server in Hive allows external clients to interact with Hive over a network, similar to the JDBC or ODBC protocols.
Apache Hive
Apache Hive Tutorial – Hive Shell
The shell is the primary way with the help of which we interact with the Hive; we can issue our commands or queries in HiveQL inside the Hive shell. Hive Shell is almost similar to MySQL Shell.
It is the command line interface for Hive. In Hive Shell users can run HQL queries. HiveQL is also case-insensitive (except for string comparisons) same as SQL.
We can run the Hive Shell in two modes which are: Non-Interactive mode and Interactive mode
- Hive in Non-Interactive mode – Hive Shell can be run in the non-interactive mode, with -f option we can specify the location of a file which contains HQL queries. For example- hive -f my-script.q
- Hive in Interactive mode – Hive Shell can also be run in the interactive mode. In this mode, we directly need to go to the hive shell and run the queries there. In hive shell, we can submit required queries manually and get the result. For example- $bin/hive, go to hive shell.
Features of Apache Hive
There are so many features of Apache Hive. Let’s discuss them one by one-
- Hive provides data summarization, query, and analysis in much easier manner.
- Hive supports external tables which make it possible to process data without actually storing in HDFS.
- Apache Hive fits the low-level interface requirement of Hadoop perfectly.
- It also supports partitioning of data at the level of tables to improve performance.
- Hive has a rule based optimizer for optimizing logical plans.
- It is scalable, familiar, and extensible.
- Using HiveQL doesn’t require any knowledge of programming language, Knowledge of basic SQL query is enough.
- We can easily process structured data in Hadoop using Hive.
- Querying in Hive is very simple as it is similar to SQL.
- We can also run Ad-hoc queries for the data analysis using Hive.
Limitation of Apache Hive
Hive has the following limitations-
- Apache does not offer real-time queries and row level updates.
- Hive also provides acceptable latency for interactive data browsing.
- It is not good for online transaction processing.
- Latency for Apache Hive queries is generally very high.
So, this was all in Apache Hive Tutorial. Hope you like our explanation.
Conclusion
In Conclusion, Hive is a Data Warehousing package built on top of Hadoop used for data analysis. Hive also uses a language called HiveQL (HQL) which automatically translates SQL-like queries into MapReduce jobs.
We have also learned various components of Hive like meta store, optimizer etc.
If you have any query related to this Apache Hive tutorial, so leave a comment in a section given below.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google


I wish you could write a chapter on Tez. I hear is has greatly improved the capabilities of Hive by leveraging memory.
Hi KRJ,
Thanks for commenting on Apache Hive tutorial. Nowadays, Apache Spark and Hadoop are the rising stars of the Big Data World. So, we recommend you to explore them because Tez will die soon.
To know about Hadoop and Apache Spark, you can refer our articles.
Regards
DataFlair
Excellent explanation. All your materials simple and clear. Appreciate it. Many thanks
Thanks, Dhanu for the appreciation, we are glad you found our “Hive tutorial for beginners” informative. Hope, you are enjoying our other Apache Hive articles.
Please do share with your peer groups and help us to circulate the Hive Concepts.
Regards,
DataFlair
Can we process semi-structured and unstructured data with Hive.
For that you need cassendra or mongodb
Hi Shivam,
Thanks for the reply, we have a series of Cassandra Tutorials and MongoDB Tutorials as well. You can also refer them to our main menu.
Regards,
DataFlair
Hi Sajid,
Thanks for asking the query on Apache Hive.
Answer – No, Apache Hive cannot handle Unstructured data. First, you have to convert unstructured data to structured data, then we can process it in HIve.
Hope, you understood!
Keep learning and keep coding
DataFlair
The materials are quite easy to understand .Thanks for all topics .
Hello Deepti,
Thanks for the amazing comment. Hope, now you know what is Apache Hive with its architecture and benefits. You can refer our sidebar, for more Hive tutorials. Also, we have a series of Apache Hive interview Questions and Quizzes, for your practice.
Regards,
DataFlair
I’m very glad that I found this website.
Hi, Daniel
Thanks for appreciating our efforts on Apache Hive Tutorial. This is just a beginning, we have many more Hive tutorials, which will surely help you to build your knowledge.
Please refer them too.
Regards,
DataFlair
Hello,
The content in the article is very clear and nice. Everyone can understand the concepts quickly. Thanks for the article!!
Can we have interview based scenarios on Hive. It would be helpful for us.
Thanks,
Santhosh.
Hi Santhosh,
Thank you so much for taking the time to write this excellent review for Apache Hive tutorial or beginners. Hope, you refer our sidebar and complete this list of Hive tutorial.
For Apache Hive Interview Question, you can refer our Hive Interview Question and Quiz Section (At bottom of left sidebar). We have a series of latest questions.
Hope it will help you!
Keep Visiting DataFlair
In both it is written that “Hive Shell can be run in the non-interactive mode”
(( kindly correct it ))
*************************************************************************
Hive in Non-Interactive mode – Hive Shell can be run in the non-interactive mode, with -f option we can specify the location of a file which contains HQL queries. For example- hive -f my-script.q
Hive in Interactive mode – Hive Shell can also be run in the non-interactive mode. In this mode, we directly need to go to the hive shell and run the queries there. In hive shell, we can submit required queries manually and get the result. For example- $bin/hive, go to hive shell.
I am totally addicted to data flair. whatever be the doubts, It will be cleared over here for Sure.
The best part, if doubts still exist then comment and expert will revert back to You.
Thank you so much, Jittendra for such a nice word. DataFlair is always looking to help those who are willing to learn.
You can also contribute DataFlair by sharing the articles with your peer groups.
In interactive mode of Hive, please correct the 2nd line.
Hi, You are saying “not good for Online transaction processing” , Why?
Hi, Can I have a pdf version of this tutorial which I can print as I prefer reading hardcopy over softcopy. Also, it is easier to mark and maintain important things in hardcopy.
It would be great if you Data-flair team can mail me the pdf form of this tutorial.
Thanks in advance !!
Apache Hive does not offer real-time queries and row level updates. Can you please explain this in detail.
Excellent tutorial for beginners and experienced.
I am not able to click on the topics properly in my left corner if I click on something it is opening something else
What is “Hadoop Haused”. I see this is many places. I could not figure this out.
As a result, Facebook was looking out for better options. To overcome this problem, Facebook initially tried using MapReduce. But it has difficulty in programming and mandatory knowledge in SQL, making it an impractical solution. -> there is an error in this sentence -> programming and mandatory knowledge in “JAVA”
notiecd there are many sentences reperated
Apache Hive is an open source data warehouse system built on top of Hadoop Haused for querying and analyzing large datasets stored in Hadoop files.
I just love the way you guys explain.
I just love the way you guys explain. I am so much dependent for BIG DATA on data flair. A WARM THANKS.
As a result, Facebook was looking out for better options. To overcome this problem, Facebook initially tried using MapReduce. But it has difficulty in programming and mandatory knowledge in SQL, making it an impractical solution. -> there is an error in this sentence -> programming and mandatory knowledge in “JAVA”
notiecd there are many sentences reperated