Spark Performance Tuning-Learn to Tune Apache Spark Job
1. Objective – Spark Performance Tuning
Spark Performance Tuning is the process of adjusting settings to record for memory, cores, and instances used by the system. This process guarantees that the Spark has optimal performance and prevents resource bottlenecking in Spark.
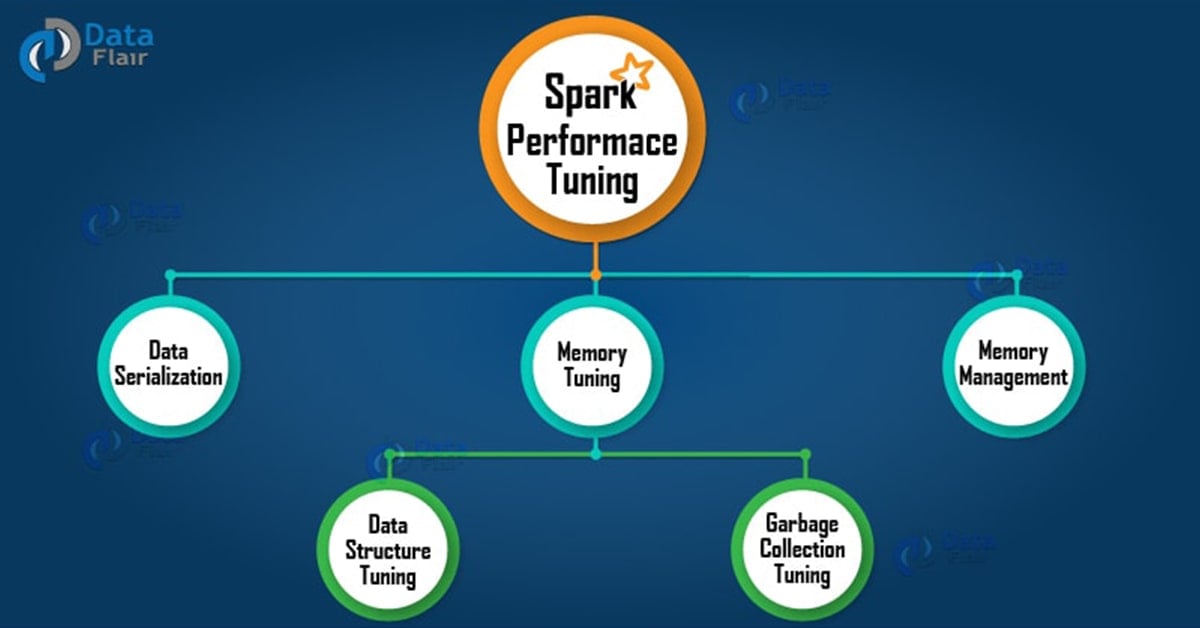
In this Tutorial of Performance tuning in Apache Spark, we will provide you complete details about How to tune your Apache Spark jobs? This Spark Tutorial covers performance tuning introduction in Apache Spark, Spark Data Serialization libraries such as Java serialization & Kryo serialization, Spark Memory tuning. We will also learn about Spark Data Structure Tuning, Spark Data Locality and Garbage Collection Tuning in Spark in this Spark performance tuning and Optimization tutorial.
Spark Performance Tuning-Learn to Tune Apache Spark Job
Refer this guide to learn the Apache Spark installation in the Standalone mode.
2. What is Performance Tuning in Apache Spark?
The process of adjusting settings to record for memory, cores, and instances used by the system is termed tuning. This process guarantees that the Spark has optimal performance and prevents resource bottlenecking. Effective changes are made to each property and settings, to ensure the correct usage of resources based on system-specific setup. Apache Spark has in-memory computation nature. As a result resources in the cluster (CPU, memory etc.) may get bottlenecked.
Sometimes to decrease memory usage RDDs are stored in serialized form. Data serialization plays important role in good network performance and can also help in reducing memory usage, and memory tuning.
If used properly, tuning can:
- Ensure proper use of all resources in an effective manner.
- Eliminates those jobs that run long.
- Improves the performance time of the system.
- Guarantees that jobs are on correct execution engine.
3. Data Serialization in Spark
It is the process of converting the in-memory object to another format that can be used to store in a file or send over the network. It plays a distinctive role in the performance of any distributed application. The computation gets slower due to formats that are slow to serialize or consume a large number of files. Apache Spark gives two serialization libraries:
- Java serialization
- Kryo serialization
Java serialization – Objects are serialized in Spark using an ObjectOutputStream framework, and can run with any class that implements java.io.Serializable. The performance of serialization can be controlled by extending java.io.Externalizable. It is flexible but slow and leads to large serialized formats for many classes.
Kryo serialization – To serialize objects, Spark can use the Kryo library (Version 2). Although it is more compact than Java serialization, it does not support all Serializable types. For better performance, we need to register the classes in advance. We can switch to Karyo by initializing our job with SparkConf and calling-
conf.set(“spark.serializer”, “org.apache.spark.serializer.KyroSerializer”)
We use the registerKryoClasses method, to register our own class with Kryo. In case our objects are large we need to increase spark.kryoserializer.buffer config. The value should be large so that it can hold the largest object we want to serialize.
Get the Best Spark Books to become Master of Apache Spark.
4. Memory Tuning in Spark
Consider the following three things in tuning memory usage:
- Amount of memory used by objects (the entire dataset should fit in-memory)
- The cost of accessing those objects
- Overhead of garbage collection.
The Java objects can be accessed but consume 2-5x more space than the raw data inside their field. The reasons for such behavior are:
- Every distinct Java object has an “object header”. The size of this header is 16 bytes. Sometimes the object has little data in it, thus in such cases, it can be bigger than the data.
- There are about 40 bytes of overhead over the raw string data in Java String. It stores each character as two bytes because of String’s internal usage of UTF-16 encoding. If there are 10 characters String, it can easily consume 60 bytes.
- Common collection classes like HashMap and LinkedList make use of linked data structure, there we have “wrapper” object for every entry. This object has both header and pointer (8 bytes each) to the next object in the list.
- Collections of primitive types often store them as “boxed objects”. For example, java.lang.Integer.
a. Spark Data Structure Tuning
By avoiding the Java features that add overhead we can reduce the memory consumption. There are several ways to achieve this:
- Avoid the nested structure with lots of small objects and pointers.
- Instead of using strings for keys, use numeric IDs or enumerated objects.
- If the RAM size is less than 32 GB, set JVM flag to –xx:+UseCompressedOops to make a pointer to four bytes instead of eight.
b. Spark Garbage Collection Tuning
JVM garbage collection is problematic with large churn RDD stored by the program. To make room for new objects, Java removes the older one; it traces all the old objects and finds the unused one. But the key point is that cost of garbage collection in Spark is proportional to a number of Java objects. Thus, it is better to use a data structure in Spark with lesser objects. One more way to achieve this is to persist objects in serialized form. As a result, there will be only one object per RDD partition.
5. Memory Management in Spark
We consider Spark memory management under two categories: execution and storage. The memory which is for computing in shuffles, Joins, aggregation is Execution memory. While the one for caching and propagating internal data in the cluster is storage memory. Both execution and storage share a unified region M. When the execution memory is not in use, the storage can use all the memory. The same case lies true for Storage memory. Execution can drive out the storage if necessary. This is done only until storage memory usage falls under certain threshold R.
We can get several properties by this design. First, the application can use entire space for execution if it does not use caching. While the applications that use caching can reserve a small storage (R), where data blocks are immune to evict.
Even though we have two relevant configurations, the users need not adjust them. Because default values are relevant to most workloads:
- memory.fraction describes the size of M as a fraction of the (JVM heap space-300MB)(default 0.6). The remaining 40% is stored in user data structure, internal metadata in Spark and safeguarding against OOM error in case of Sparse and large records.
- memory.storageFraction shows the size of R as the fraction of M (default 0.5).
Learn How Fault Tolerance is achieved in Apache Spark.
6. Determining Memory Consumption in Spark
If we want to know the size of Spark memory consumption a dataset will require to create an RDD, put that RDD into the cache and look at “Storage” page in Web UI. This page will let us know the amount of memory RDD is occupying.
If we want to know the memory consumption of particular object, use SizeEstimator’S estimate method.
7. Spark Garbage Collection Tuning
In garbage collection, tuning in Apache Spark, the first step is to gather statistics on how frequently garbage collection occurs. It also gathers the amount of time spent in garbage collection. Thus, can be achieved by adding -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps to Java option. The next time when Spark job run, a message will display in workers log whenever garbage collection occurs. These logs will be in worker node, not on drivers program.
Java heap space divides into two regions Young and Old. The young generation holds short-lived objects while Old generation holds objects with longer life. The garbage collection tuning aims at, long-lived RDDs in the old generation. It also aims at the size of a young generation which is enough to store short-lived objects. With this, we can avoid full garbage collection to gather temporary object created during task execution. Some steps that may help to achieve this are:
- If full garbage collection is invoked several times before a task is complete this ensures that there is not enough memory to execute the task.
- In garbage collection statistics, if OldGen is near to full we can reduce the amount of memory used for caching. This can be achieved by lowering spark.memory.fraction. the better choice is to cache fewer objects than to slow down task execution. Or we can decrease the size of young generation i.e., lowering –Xmn.
The effect of Apache Spark garbage collection tuning depends on our application and amount of memory used.
8. Other consideration for Spark Performance Tuning
a. Level of Parallelism
To use the full cluster the level of parallelism of each program should be high enough. According to the size of the file, Spark sets the number of “Map” task to run on each file. The level of parallelism can be passed as a second argument. We can set the config property spark.default.parallelism to change the default.
b. Memory Usage of Reduce Task in Spark
Although RDDs fit in our memory many times we come across a problem of OutOfMemoryError. This is because the working set of our task say groupByKey is too large. We can fix this by increasing the level of parallelism so that each task’s input set is small. We can increase the number of cores in our cluster because Spark reuses one executor JVM across many tasks and has low task launching cost.
Learn about groupByKey and other Transformations and Actions API in Apache Spark with examples.
c. Broadcasting Large Variables
The size of each serialized task reduces by using broadcast functionality in SparkContext. If a task uses a large object from driver program inside of them, turn it into the broadcast variable. Generally, it considers the tasks that are about 20 Kb for optimization.
d. Data Locality in Apache Spark
Data locality plays an important role in the performance of Spark Jobs. The case in which the data and code that operates on that data are together, the computation is faster. But if the two are separate, then either the code should be moved to data or vice versa. It is faster to move serialized code from place to place then the chunk of data because the size of the code is smaller than the data.
Based on data current location there are various levels of locality. The order from closest to farthest is:
- The best possible locality is that the PROCESS_LOCAL resides in same JVM as the running code.
- NODE_LOCAL resides on the same node in this. It is because the data travel between processes is quite slower than PROCESS_LOCAL.
- There is no locality preference in NO_PREF data is accessible from anywhere.
- RACK_LOCAL data is on the same rack of the server. Since the data is on the same rack but on the different server, so it sends the data in the network, through a single switch.
- ANY data resides somewhere else in the network and not in the same rack.
So, this was all in Spark Performance Tuning. Hope you like our explanation.
9. Conclusion – Spark Performance Tuning
Consequently, to increase the performance of the system performance tuning plays the vital role. Serializing the data plays an important role in tuning the system. Spark employs a number of optimization techniques to cut the processing time. Thus, Performance Tuning guarantees the better performance of the system.
After learning performance tuning in Apache Spark, Follow this guide to learn How Apache Spark works in detail.
You can share your queries about Spark performance tuning, by leaving a comment. We will be happy to solve them.
See Also-
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





Yes , really nice information. Thank you!!
I am running in heavy performance issues in a interative algorithm using the graphframes framework with message aggregation.
I do not find out what I do wrong with caching or the way of iterating. Do you have any hint where to read or search to understand this bottlenek?
The code is written on Pyspark
Spark Version: Spark 2.4.3
Python Version: 3.7
Graphframes Version: 0.7.0
#######################################################################################
# Inferred Removed detection using graphframe message aggregation
#######################################################################################
def find_inferred_removed(spark,sc,edges,max_iter=100:
“””
rules implemented:
1) start from scrap=true backwards
2) stop on removed.inNotNull() – either removed is Null or it contains the timestamp of removal
3) stop on binary split
4) stop if created_utc_last > scrap_date
5) skip self loops
6) handle rebuilds as combination of binary split and removed.inNotNull()
“””
_logger.warning(“+++ find_inferred_removed(): starting inferred_removed analysis …”)
####################################################################
# 1) Prepare input data for IR algorithm
###################################################################
# create initial edges set without self loops
# this removes real self loops and also cycles which are in the super_edge notation also self loops
# introduce a new temp column “_to_remove” that is used to remember the state during the loop
#Start Data:
# _inferred_removed: always True if scrap=True or removed=True
# _removed: True if removed
# _scrap_date: if scrap, the use the created_utc as _scrap_date
# exclude self loops
# create and union vertices dataframe
vertices=edges.select(“src”).union(edges.select(“dst”)).distinct().withColumnRenamed(‘src’, ‘id’)
edge_init=(
edges
# create temporary working column _to_remove that holds the values during iteration through the graph
# initialize the values with true if the inferred_removed or the scrap column has true value
# !! not when the removed column is not empty as here we have to decide later if to stop or continue
.withColumn(“_inferred_removed”,f.when(f.col(“scrap”)==True,True).otherwise(False))
.withColumn(“_inferred_removed”,f.when(f.col(“removed”).isNotNull(),True).otherwise(f.col(“_inferred_removed”))) \
.withColumn(“_removed”,f.when(f.col(“removed”).isNotNull(),True).otherwise(False))
.withColumn(“_scrap_date”,f.when(f.col(“scrap”)==True,f.col(“created_utc_last”)).otherwise(None))
# exclude self loops
.where(f.col(“src”)!=f.col(“dst”))
)
# set result set to initial values
# this will be update in each round of the loop of the aggregate message process
# This will be a real copy, a new RDD, immutable?? Memory issue??
result_edges=edge_init
# this is the temporary dataframe where we write in the aggregation results each round
# an empty dataframe can only be created from an empty RDD
# id will be the id
# final_flag: True, False, for this id if True then proceed, otherwise only send False
# scrap_date to send to predecessors
remember_agg = spark.createDataFrame(
sc.emptyRDD(),
StructType([StructField(“id”,StringType(),True),
StructField(“final_flag”,BooleanType(),True),
StructField(“scrap_date”,TimestampType(),True)
])
)
# create initial graph object
gx=GraphFrame(vertices,edge_init)
####################################################################
# 2) main algorithm loop
###################################################################
# start message aggregation loop.
# the max_iter limit is a limit if the algorithm is not converging at all to stop and break out the loop
loop_start_time =time.time()
for iter_ in range(max_iter):
_logger.warning(“+++ find_inferred_removed(): iteration step= ” + str(iter_+1) + ” with loop time= ” + str(round(time.time()-loop_start_time)) + ” seconds”)
# message that sends the _to_remove flag backwards in the graph to the source of each edge
# the latest value of the _to_remove flag of each edge is send backwards to be compared
msgToSrc_inferred_removed = AM.edge[“_inferred_removed”]
msgToSrc_removed = AM.edge[“_removed”]
msgToSrc_id = AM.dst[“id”]
msgToSrc_scrap_date = AM.edge[“_scrap_date”]
# send the value of inferred_removed backwards (in order to inferre remove)
agg_inferred_removed = gx.aggregateMessages(
# aggregate with the min function over boolean. Spark min function aggregates with the
# following logic over bool
# min(True,True)=True -> only true if all true
# min(True,False)=False –> otherwise false
# min(False,False)=False
# AM.msg: So hole ich mir die Nachricht die kommt
f.min(AM.msg).alias(“agg_inferred_removed”),
# send message to source vertice
sendToSrc=msgToSrc_inferred_removed,
# send nothing to destination vertices
sendToDst=None)
# send the value of removed backwards (in order to stop if remove has date)
agg_removed = gx.aggregateMessages(
f.max(AM.msg).alias(“agg_removed”),
sendToSrc=msgToSrc_removed,
sendToDst=None)
# send the own id backwards (in order to check of multi splits)
agg_id = gx.aggregateMessages(
f.collect_set(AM.msg).alias(“agg_src”),
sendToSrc=msgToSrc_id,
sendToDst=None)
# send scrap_date=utc_created_last from scraped edge backwards (in order to stop on newer edges)
agg_scrap_date = gx.aggregateMessages(
f.max(AM.msg).alias(“agg_scrap_date”),
sendToSrc=msgToSrc_scrap_date,
sendToDst=None)
# join all aggretation results on each vertices together and analyse
full_agg=(
agg_inferred_removed.alias(“agg_1″)
.join(agg_removed,agg_inferred_removed.id==agg_removed.id,how=”left”)
.join(agg_id,agg_inferred_removed.id==agg_id.id,how=”left”)
.join(agg_scrap_date,agg_inferred_removed.id==agg_scrap_date.id,how=”left”)
.withColumn(“_size”,f.size(f.col(“agg_src”)))
.withColumn(“final_flag”,
f.when((f.col(“agg_inferred_removed”)==True) & (f.col(“agg_removed”)==False),True)
.otherwise(
f.when((f.col(“agg_inferred_removed”)==True) & (f.col(“agg_removed”)==True)& (f.col(“_size”)>1),True)
.otherwise(False)
)
)
.select(“agg_1.id”,”final_flag”,”agg_scrap_date”)
)
# break condition: if nothing more to aggregate quit the loop
################################################################
# to find out if nothing is more todo substract the remember_agg from the current agg dataframe
# if they are exactly similar and nothing is changing with further iteration
# if they are same the substract has 0 rows and then the take(1) has the length 0
# this is a comon workaround in Spark to find empty dataframes
#print(“###########”)
#full_agg.show()
#remember_agg.show()
#print(“###########”)
if((iter_>0) & (len(full_agg.select(“id”,”final_flag”).subtract(remember_agg.select(“id”,”final_flag”)).take(1))==0)):
_logger.warning(“+++ find_inferred_removed(): THE END: Inferred removed analysis completed after ” + str(iter_+1) + ” iterations in ” + str(round(time.time()-loop_start_time)) + ” seconds”)
break
# Cache dataframe
remember_agg=AM.getCachedDataFrame(full_agg)
#Update
result_edges=(
result_edges.alias(“result”)
.join(remember_agg,result_edges.dst==remember_agg.id,how=”left”)
# update scrap date in order to push it backwards
.withColumn(“_scrap_date”,f.when(f.col(“_scrap_date”).isNull(),f.col(“agg_scrap_date”)).otherwise(f.col(“_scrap_date”)))
.withColumn(“_inferred_removed”,f.when(f.col(“final_flag”)==True,True).otherwise(f.col(“_inferred_removed”)))
# in case the scrap date is older than a created date of an edge we also stop inferred removed
.withColumn(“_inferred_removed”,f.when(f.col(“_scrap_date”)<f.col("created_utc_last"),False).otherwise(f.col("_inferred_removed")))
.drop("id")
.drop("final_flag")
.drop("agg_scrap_date")
)
# Cache dataframe
cachedNewEdges = AM.getCachedDataFrame(result_edges)
gx=GraphFrame(vertices,cachedNewEdges)
return result_edges