Spark In-Memory Computing – A Beginners Guide
1. Objective
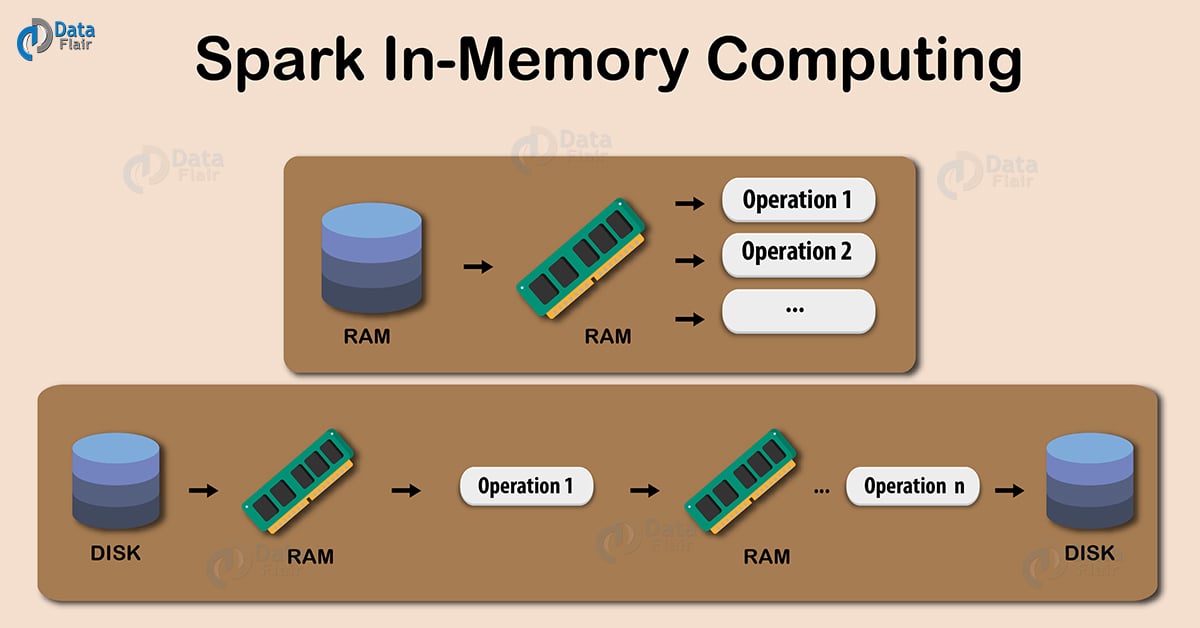
This tutorial on Apache Spark in-memory computing will provide you the detailed description of what is in memory computing? Introduction to Spark in-memory processing and how does Apache Spark process data that does not fit into the memory? This tutorial will also cover various storage levels in Spark and benefits of in-memory computation.
Spark In-Memory Computing – A Beginners Guide
2. What is Spark In-memory Computing?
In in-memory computation, the data is kept in random access memory(RAM) instead of some slow disk drives and is processed in parallel. Using this we can detect a pattern, analyze large data. This has become popular because it reduces the cost of memory. So, in-memory processing is economic for applications. The two main columns of in-memory computation are-
- RAM storage
- Parallel distributed processing.
3. Introduction to Spark In-memory Computing
Keeping the data in-memory improves the performance by an order of magnitudes. The main abstraction of Spark is its RDDs. And the RDDs are cached using the cache() or persist() method.
When we use cache() method, all the RDD stores in-memory. When RDD stores the value in memory, the data that does not fit in memory is either recalculated or the excess data is sent to disk. Whenever we want RDD, it can be extracted without going to disk. This reduces the space-time complexity and overhead of disk storage.
The in-memory capability of Spark is good for machine learning and micro-batch processing. It provides faster execution for iterative jobs.
When we use persist() method the RDDs can also be stored in-memory, we can use it across parallel operations. The difference between cache() and persist() is that using cache() the default storage level is MEMORY_ONLY while using persist() we can use various storage levels.
Follow this link to learn Spark RDD persistence and caching mechanism.
4. Storage levels of RDD Persist() in Spark
The various storage level of persist() method in Apache Spark RDD are:
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
- MEMORY_ONLY_2 and MEMORY_AND_DISK_2
Let’s discuss the above mention Apache Spark storage levels one by one –
4.1. MEMORY_ONLY
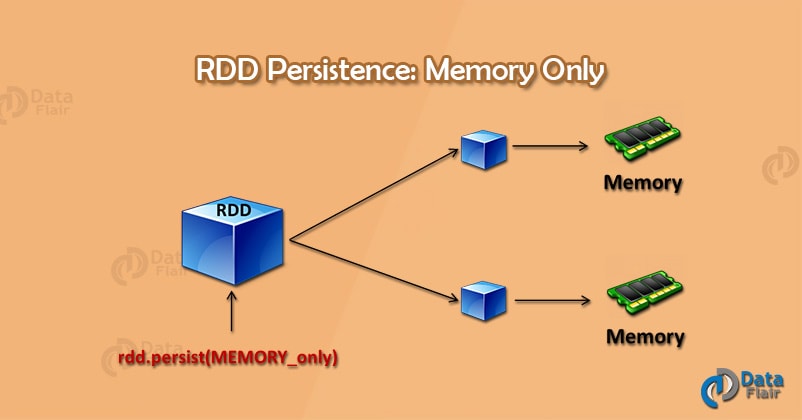
Spark storage level – memory only
In this storage level Spark, RDD store as deserialized JAVA object in JVM. If RDD does not fit in memory, then the remaining will recompute each time they are needed.
4.2. MEMORY_AND_DISK

Spark storage level-memory and disk
In this level, RDD is stored as deserialized JAVA object in JVM. If the full RDD does not fit in memory then the remaining partition is stored on disk, instead of recomputing it every time when it is needed.
4.3. MEMORY_ONLY_SER
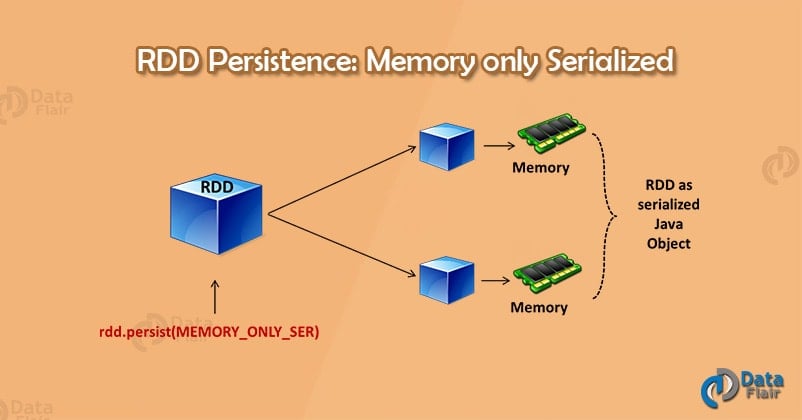
Spark storage level – memory only serialized
This level stores RDDs as serialized JAVA object. It stores one-byte array per partition. It is like MEMORY_ONLY but is more space efficient especially when we use fast serializer.
4.4. MEMORY_AND_DISK_SER
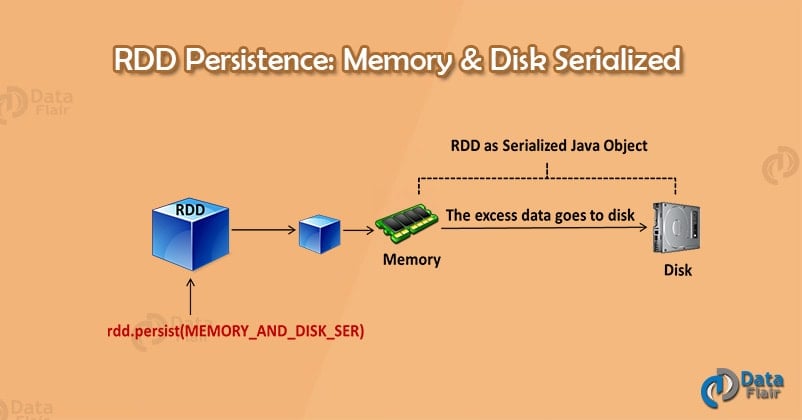
Spark storage level – memory and disk serialized
This level stores RDD as serialized JAVA object. If the full RDD does not fit in the memory then it stores the remaining partition on the disk, instead of recomputing it every time when we need.
4.5. DISK_ONLY
Spark storage level-disk-only
This storage level stores the RDD partitions only on disk.
4.6. MEMORY_ONLY_2 and MEMORY_AND_DISK_2
It is like MEMORY_ONLY and MEMORY_AND_DISK. The only difference is that each partition gets replicate on two nodes in the cluster.
Follow this link to learn more about Spark terminologies and concepts in detail.
5. Advantages of In-memory Processing
After studying Spark in-memory computing introduction and various storage levels in detail, let’s discuss the advantages of in-memory computation-
- When we need a data to analyze it is already available on the go or we can retrieve it easily.
- It is good for real-time risk management and fraud detection.
- The data becomes highly accessible.
- The computation speed of the system increases.
- Improves complex event processing.
- Cached a large amount of data.
- It is economic, as the cost of RAM has fallen over a period of time.
6. Conclusion
In conclusion, Apache Hadoop enables users to store and process huge amounts of data at very low costs. However, it relies on persistent storage to provide fault tolerance and its one-pass computation model makes MapReduce a poor fit for low-latency applications and iterative computations, such as machine learning and graph algorithms.
Hence, Apache Spark solves these Hadoop drawbacks by generalizing the MapReduce model. It improves the performance and ease of use.
If you like this post or have any query related to Apache Spark In-Memory Computing, so, do let us know by leaving a comment.
See Also – Limitations Of Apache Spark.
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





I have done the spark and scala course but have no experience in real-time projects or distributed cluster. I would like to do one or two projects in big data and get the job in the same.
Please let me know for the options of doing the project with you and guidance.
Use GCP for real time programming
Hi Adithyan
Thanks for commenting on the Apache Spark In-Memory Tutorial. Soon, we will publish an article for a list of Spark projects. Stay with us!
Regards,
DataFlair
Hi Dataflair team, any update on the spark project? Thanks!
Thanks for document.Really awesome explanation on each memory type.
Need clarification on memory_only_ser as we told one-byte array per partition.Whether this is equivalent to indexing in SQL.
As RAM is a volatile memory, doesn’t it affect Apache Spark processing?
Are Spark nodes are always active? If nodes get off then data stored RAm will be lost, right?