Spark Notes for Beginners & Experienced
1. Objective – Spark notes
In this Apache Spark Notes, we will discuss the next-gen Big Data tool Apache Spark. Spark is an open source, wide range data processing engine with revealing development API’s, that qualify data workers to accomplish Spark streaming, machine learning or SQL workloads which demand repeated access to data sets.
This blog of Spark Notes, answers to what is Apache Spark, what is the need of Spark, what are the Spark components and what are their roles, how Apache Spark is used by data scientist? We will also discuss various features and limitations of Spark in this Spark Notes.
So, let’s start Spark Notes tutorial.
Spark Notes for Beginners & Experienced
2. Spark Notes – What is Spark?
Apache Spark is an open source, wide range data processing engine with revealing development API’s, that qualify data workers to accomplish streaming in spark, machine learning or SQL workloads which demand repeated access to data sets. It is designed in such a way that it can perform batch processing (processing of the previously collected job in a single batch) and stream processing (deal with streaming data). It is a general purpose, cluster computing platform.
Spark is designed in such a way that it integrates with all the Big data tools. For example, Spark can access any Hadoop data source and can run on Hadoop clusters. Spark extends Hadoop MapReduce to next level which includes iterative queries and stream processing.
MapReduce is a programming paradigm that allows scalability across thousands of server in Hadoop cluster. Spark is highly accessible and offers simple APIs in Python, Java, Scala, and R.
There is a common belief that Apache Spark is an extension of Hadoop, which is not true. Spark is independent of Hadoop because it has its own cluster management system. It uses Hadoop for storage purpose only.
The key feature of Spark is that it has in-memory cluster computation capability. That increases the processing speed of an application. The in-memory computing means using a type of middleware software that allows one to store data in RAM, across a cluster of computers, and process it in parallel.
As we know that the images are the worth of a thousand words. To keep this in mind we have also provided Spark video tutorial for more understanding of Apache Spark.
3. Spark Notes – Spark History
Apache Spark is a subproject of Hadoop developed in the year 2009 by Matei Zaharia in UC Berkeley’s AMPLab. The first users of Spark were the group inside UC Berkeley including machine learning researchers, which used Spark to monitor and predict traffic congestion in the San Francisco Bay Area. Spark has open sourced in the year 2010 under BSD license. Spark became a project of Apache Software Foundation in the year 2013 and is now the biggest project of Apache foundation.
4. Why Spark?
This section of Spark notes, we cover the needs of Spark. Apache Spark was developed to overcome the limitations of Hadoop MapReduce cluster computing paradigm. Some of the drawbacks of Hadoop MapReduce are:
- Use only Java for application building.
- Since the maximum framework is written in Java there is some security concern. Java being heavily exploited by cybercriminals this may result in numerous security breaches.
- Opt only for batch processing. Does not support stream processing.
- Hadoop MapReduce uses disk-based processing.
Due to these weaknesses of Hadoop MapReduce Apache Spark come into the picture. Features of Spark listed below explains that how Spark overcomes the limitations of Hadoop MapReduce.
5. Features of Apache Spark
In this section of Spark notes, we will discuss various Spark features, which takes Spark to the limelight.
a. Swift Processing
The key feature required for Bigdata evaluation is speed. With Apache Spark, we get swift processing speed of up to 100x faster in memory and 10x faster than Hadoop even when running on disk. It is achieved by reducing the number of read-write to disk.
b. Dynamic
Because of 80 high-level operators present in Apache Spark, it makes it possible to develop parallel applications. Scala being defaulted language for Spark. We can also work with Java, Python, R. Hence, it provides dynamicity and overcomes the limitation of Hadoop MapReduce that it can build applications only in java.
c. In – Memory Processing
Disk seeks is becoming very costly with increasing volumes of data. Reading terabytes to petabytes of data from disk and writing back to disk, again and again, is not acceptable. Hence in-memory processing in Spark works as a boon to increasing the processing speed. Spark keeps data in memory for faster access. Keeping data in servers’ RAM as it makes accessing stored data quickly /faster.
Spark owns advanced DAG execution engine which facilitates in-memory computation and acyclic data flow resulting high speed. You can find out the more detail about Spark in-memory computation.
d. Reusability
Apache Spark provides the provision of code reusability for batch processing, join streams against historical data, or run adhoc queries on stream state.
e. Fault Tolerance
Spark RDD (Resilient Distributed Dataset), abstraction are designed to seamlessly handle failures of any worker nodes in the cluster. Thus, the loss of data and information is negligible. Follow this guide to learn how fault tolerance is achieved in Spark?
f. Real-Time Stream Processing
Spark Streaming can handle real-time stream processing along with the integration of other frameworks which concludes that sparks streaming ability are easy, fault tolerance and Integrated. Refer Spark Streaming Tutorial for detailed study.
g. Pillar to Sophisticated Analytics
Spark comes with tools for interactive/declarative queries, streaming data, machine learning which is an addition to the simple map and reduces, so that user can combine all this into a single workflow.
h. Compatibility with Hadoop & existing Hadoop Data
Apache Spark is compatible with both versions of Hadoop ecosystem. Be it YARN (Yet Another Resource Negotiator) or SIMR (Spark in MapReduce). It can read anything existing Hadoop data that’s what makes it suitable for migration of pure Hadoop applications. It can run independently too. Follow this link if you would like to know how Spark is compatible with Hadoop?
i. Lazy Evaluation
Lazy Evaluation is an Another outstanding feature of Apache Spark is called by need or memorization. It waits for instructions before providing a final result which saves time. Learn Spark Lazy Evaluation feature in detail.
j. Active, Progressive and Expanding Community
A wide set of developers from over 50 companies build Apache Spark. It has active mailing state and JIRA for issue tracking.
6. Apache Spark Ecosystem
Till now in Spark notes, we have studied what is Spark and way spark is needed? Now, we will cover the Spark Ecosystem. Following are the ecosystem components of Apache Spark.
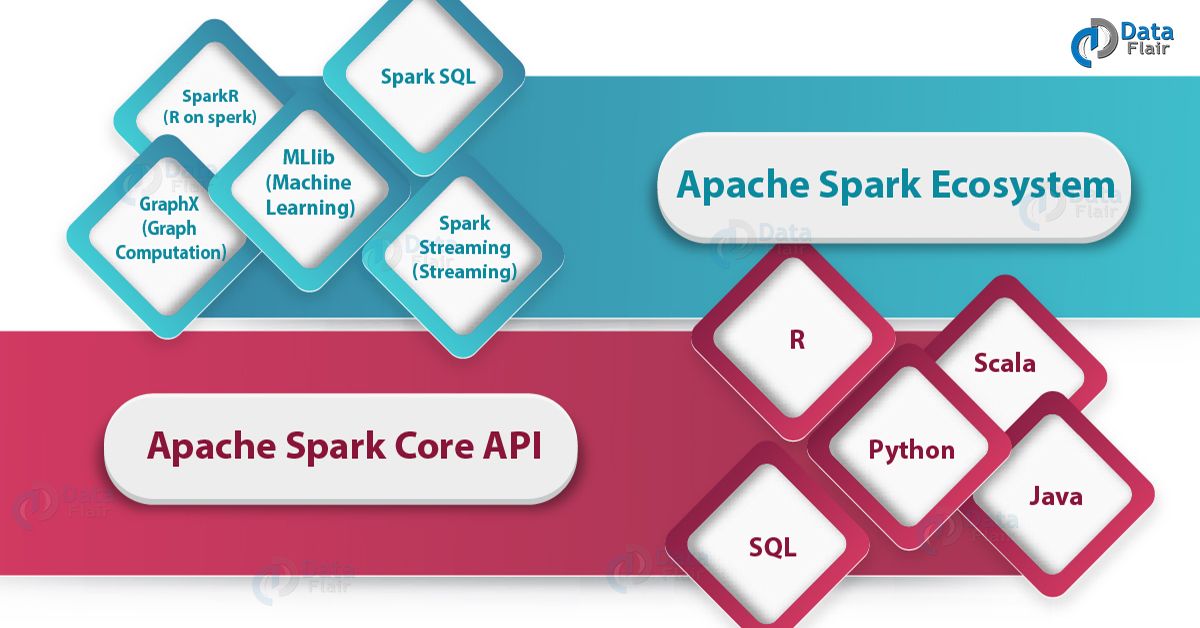
Apache Spark Ecosystem Components
a. Spark Core
It is the foundation of Spark. Spark core is also shelter to API that contains the backbone of Spark i.e. RDDs (resilient distributed datasets). The basic functionality of Spark is present in Spark Core like memory management, fault recovery, interaction with the storage system. It is in charge of essential I/O functionalities like:
- Programming and observing the role of Spark cluster
- Task dispatching
- Fault recovery
- It overcomes the snag of MapReduce by using in-memory computation.
b. Spark SQL
Spark SQL component is a distributed framework. It is a Spark package that allows working with structured and semi-structured data. Spark SQL allows querying in SQL and HQL too which provides declarative query with optimized storage running in parallel.
It enables powerful interactive and analytical application across both streaming and historical data. SparkSQL allows accessing data from multiple sources like Hive table, Parquet, and JSON. It also lets you intermix SQL query with the programmatic data manipulations supported by RDDs in Python, Java, and Scala, all within a single application, thus combining SQL with complex analytics.
Refer our Spark SQL Tutorial for the detailed study.
c. Spark Streaming
Spark Streaming enables processing of the large stream of data. It makes easy for the programmer to move between an application that manipulates data stored in memory, on disk and arriving in real time. Micro-batching is used for real time streaming. Firstly the small batches have formed from the live data and then delivered to the Spark batch processing System for processing. In short, it provides data abstraction known as DStream. It also provides fault tolerance characteristics. Refer Spark Streaming Tutorial for detailed study.
d. MLlib
Spark MLlib (Machine learning library) provides algorithms like machine learning as well as statistical, which further includes classification, regression, linear algebra, clustering, collaborative filtering as well as supporting functions such as model evaluation and data import.
MLlib is a scalable learning library that discusses high-quality algorithms and high speed. It also contains some lower level primitives.
e. GraphX
GraphX is an API for graphs and graph parallel execution. It is a network graph analytics engine. GraphX is a library that performs graph-parallel computation and manipulates graph. It has various Spark RDD API so it can help to create directed graphs with arbitrary properties linked to its vertex and edges.
Spark GraphX also provides various operator and algorithms to manipulate graph. Clustering, classification, traversal, searching, and pathfinding is possible in GraphX.
f. SparkR
In Apache Spark 1.4 SparkR has released. It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. The main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark. It is R package that gives light-weight frontend to use Apache Spark from R.
7. Limitations of Apache Spark
There are some limitations of Apache Spark
- Spark Does not have its file management system, so you need to integrate with Hadoop or another cloud-based data platform.
- In-memory capability can become a bottleneck when it comes to cost-efficient processing of Bigdata.
- Memory consumption is very high.
- It requires large data.
- MLlib lacking in a number of available algorithms (Tanimoto distance).
8. Spark Notes – Install Spark
To install Apache Spark follow this Spark installation on Ubuntu guide. Once you have completed the installation, you can play with Spark shell and run various commands, please follow this Quickstart guide to playing with Spark.
So, this was all in Spark Notes. Hope you like our explanation.
9. Conclusion – Spark Notes
In conclusion, Apache Spark notes defines that Apache spark has designed in such a way that it can scale up from one to thousands of computer node. Moreover, the simplicity of APIs in spark and its processing speed makes Spark a popular framework among data scientists. So, for the data exploration, Spark uses SQL shell. MLlib supports data analysis and Machine Learning. It lets the data scientist handle the problem with large data size.
Hence Spark provides a simple way to parallelize the applications across Clusters and hides the complexity of distributed systems programming, network developer, and fault tolerance.
Still, if you felt that I have missed any point in this Spark Notes, so please let me know by leaving a comment.
See Also
Reference
http://spark.apache.org/
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Lazy evaluation is a evaluation technIque that holds/procrastinates the evaluation /calculation of an expression till its value is required and that additionally avoids repeated evalutaion also known as sharing.Sharing decreases the execution time of functions by an exponential aspect known as
call-by-name.It increases performance by avoiding needless calculations, and error conditions in calculating compound expressions.
The definition of the lazy evaluation that the value is wrapped in a tiny wrapper function , when called, produces the desired value. This function is not called immediately, but instead stored, to be called only when or if needed.
Thank you, Sapna For Sharing Information on “Spark Lazy Evaluation”. It will help our readers to get a clear idea of Lazy Evaluation in Apache Spark.
I have read so many articles about the blogger lovers however this
paragraph is genuinely a good paragraph, keep it up.
We are Glad readers like you like our content on “Apache Spark Notes”.
Keep visiting Data-Flair for more contents on other technologies like- Spark, Hadoop, R Programming etc.
Hi blogger !! I read your content everyday and i must say you have very interesting
content here.
Hi Francesca,
Thanks for showing interest in our content, feel free to share this blog with your friends and fellow Spark learners.
Keep Liking and Keep Visiting Data-Flair
Hi admin ! I read your posts everyday and i must say
you have high quality posts here.
We Appreciate your kind words. Each Spark tutorial from Data-Flair is a step towards every learner to provide them with latest and useful information & knowledge about Apache Spark.
Thanks for this “Spark Notes” article. Can you explain lazy evaluation in brief?
Hi Nirmal Chauhan,
Thanks for Commenting on “Spark Notes” Tutorial, you can read Lazy Evaluation from here, Spark Lazy Evaluation.
We provide all the relevant links in the tutorial itself.
Regard,
Data-Flair
Your style is so unique compared to other people I’ve read stuff
from. Thank you for posting when you’ve got the opportunity,
Guess I will just bookmark this page.
Hi Mitzib,
Your Appreciation means a lot to us, we always try to improve our content to provide maximum knowledge for our readers.
Regard
Data-Flair
Hi Blogger,
Thanks for the article, I like your article so much, it helps me to learn the spark and Hadoop.
We need real time scenario to give us idea. Can you please share me your contact.
Thanks,
Thanks, Sipra for such kind words.
You Can Contact us at- [email protected]
Hi blogger!
Thank for your articles, it give me a overview and depth mind about spark. Thank you
Hi, love this blog. Thank you so much for this.
Is there a pdf version for this?
Thanks in advance.
How spark deals with bigger data…..so data from disk is loaded in memory rdd and further processed what about data greater than 1 tb and so on