Hadoop Yarn Tutorial for Beginners
This Hadoop Yarn tutorial will take you through all the aspects of Apache Hadoop Yarn like Yarn introduction, Yarn Architecture, Yarn nodes/daemons – resource manager and node manager. In this tutorial, we will discuss various Yarn features, characteristics, and High availability modes.
Hadoop Yarn Tutorial – Introduction
Apache Yarn – “Yet Another Resource Negotiator” is the resource management layer of Hadoop. The Yarn was introduced in Hadoop 2.x.
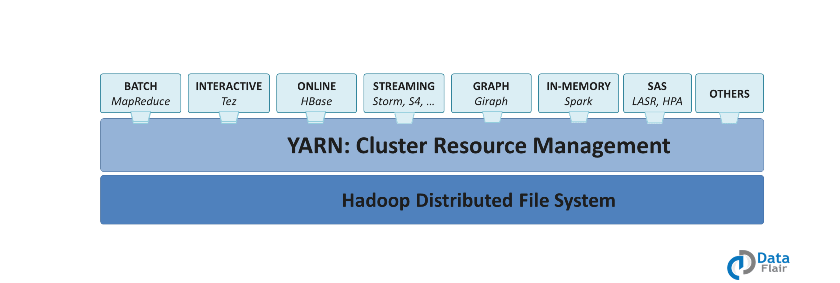
Yarn allows different data processing engines like graph processing, interactive processing, stream processing as well as batch processing to run and process data stored in HDFS (Hadoop Distributed File System). Apart from resource management, Yarn also does job Scheduling.
Yarn extends the power of Hadoop to other evolving technologies, so they can take the advantages of HDFS (most reliable and popular storage system on the planet) and economic cluster. To learn installation of Apache Hadoop 2 with Yarn follows this quick installation guide.
hadoop yarn architecture tutorial
Apache yarn is also a data operating system for Hadoop 2.x. This architecture of Hadoop 2.x provides a general purpose data processing platform which is not just limited to the MapReduce.
It enables Hadoop to process other purpose-built data processing system other than MapReduce. It allows running several different frameworks on the same hardware where Hadoop is deployed.
Hadoop Yarn Architecture
Hadoop YARN architecture
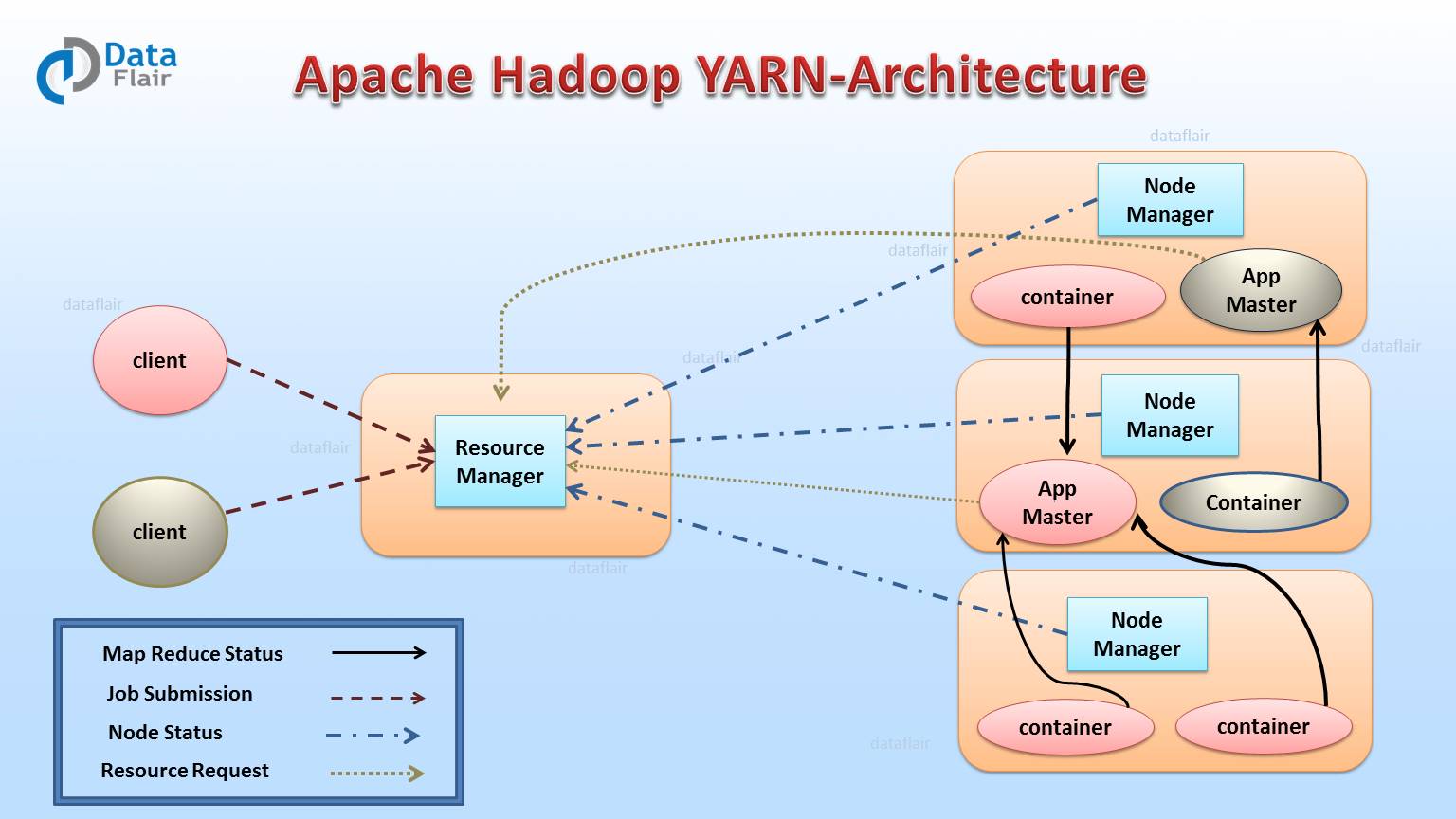
In this section of Hadoop Yarn tutorial, we will discuss the complete architecture of Yarn. Apache Yarn Framework consists of a master daemon known as “Resource Manager”, slave daemon called node manager (one per slave node) and Application Master (one per application).
1. Resource Manager (RM)
It is the master daemon of Yarn. RM manages the global assignments of resources (CPU and memory) among all the applications. It arbitrates system resources between competing applications. follow Resource Manager guide to learn Yarn Resource manager in great detail.
Resource Manager has two Main components:
- Scheduler
- Application manager
a) Scheduler
The scheduler is responsible for allocating the resources to the running application. The scheduler is pure scheduler it means that it performs no monitoring no tracking for the application and even doesn’t guarantees about restarting failed tasks either due to application failure or hardware failures.
b) Application Manager
It manages running Application Masters in the cluster, i.e., it is responsible for starting application masters and for monitoring and restarting them on different nodes in case of failures.
2. Node Manager (NM)
It is the slave daemon of Yarn. NM is responsible for containers monitoring their resource usage and reporting the same to the ResourceManager. Manage the user process on that machine. Yarn NodeManager also tracks the health of the node on which it is running. The design also allows plugging long-running auxiliary services to the NM; these are application-specific services, specified as part of the configurations and loaded by the NM during startup. A shuffle is a typical auxiliary service by the NMs for MapReduce applications on YARN
3. Application Master (AM)
One application master runs per application. It negotiates resources from the resource manager and works with the node manager. It Manages the application life cycle.
The AM acquires containers from the RM’s Scheduler before contacting the corresponding NMs to start the application’s individual tasks.
Resource Manager Restart
Resource Manager is the central authority that manages resources and schedules applications running on YARN. Hence, it is potentially an SPOF in an Apache YARN cluster.
There are two types of restart for Resource Manager:
- Non-work-preserving RM restart – This restart enhances RM to persist application/attempt state in a pluggable state-store. Resource Manager will reload the same info from state-store on the restart and re-kick the previously running apps. Users does not need to re-submit the applications. Node manager and clients during down time of RM will keep polling RM until RM comes up, when RM comes up, it will send a re-sync command to all the NM and AM it was talking to via heartbeats. The NMs will kill all its manager’s containers and re-register with RM
- Work-preserving RM restart – This focuses on reconstructing the running state of RM by combining the container status from Node Managers and container requests from Application Masters on restart. The key difference from Non-work-preserving RM restart is that already running apps will not be stopped after master restarts, so applications will not lose its processed data because of RM/master outage. RM recovers its running state by taking advantage of container status which is sent from all the node managers. NM will not kill the containers when it re-syncs with the restarted RM. It continues managing the containers and sends the container status across to RM when it re-registers.
Yarn Resource Manager High availability
The ResourceManager (master) is responsible for handling the resources in a cluster, and scheduling multiple applications (e.g., spark apps or MapReduce). Before to Hadoop v2.4, the master (RM) was the SPOF (single point of failure).
The High Availability feature adds redundancy in the form of an Active/Standby ResourceManager pair to remove this otherwise single point of failure.
ResourceManager HA is realized through an Active/Standby architecture – at any point in time, one in the masters is Active, and other Resource Managers are in Standby mode, they are waiting to take over when anything happens to the Active.
The trigger to transition-to-active comes from either the admin (through CLI) or through the integrated failover-controller when automatic failover is enabled.
1. Manual transitions and failover
When automatic failover is not configured, admins have to manually transit one of the Resource managers to the active state.
Failover from active master to the other, they are expected to transmit the active master to standby and transmit a Standby-RM to Active. Hence, this activity can be done using the yarn.
2. Automatic failover
In this case, there is no need for any manual intervention. The master has an option to embed the Zookeeper (a coordination engine) based ActiveStandbyElector to decide which Resource Manager should be the Active.
When the active fails, another Resource Manager is automatically selected to be active. Note that, there is no need to run a separate zookeeper daemon because ActiveStandbyElector embedded in Resource Managers acts as a failure detector and a leader elector instead of a separate ZKFC daemon.
Yarn Web Application Proxy
It is also the part of Yarn. By default, it runs as a part of RM but we can configure and run in a standalone mode. Hence, the reason of the proxy is to reduce the possibility of the web-based attack through Yarn.
In Yarn, the AM has a responsibility to provide a web UI and send that link to RM.
RM runs as trusted user, and provide visiting that web address will treat it and link it provides to them as trusted when in reality the AM is running as non-trusted user, application Proxy mitigate this risk by warning the user that they are connecting to an untrusted site.
Yarn Docker Container Executor
Docker combines an easy to use interface to Linux container with easy to construct files for those containers. Docker generates light weighted virtual machine. The Docker Container Executor allows the Yarn NodeManager to launch yarn container to Docker container.
Hence, these containers provide a custom software environment in which user’s code run, isolated from a software environment of NodeManager.
Hence, Docker for YARN provides both consistency (all YARN containers will have similar environment) and isolation (no interference with other components installed on the same machine).
Yarn Timeline Server
The storage and retrieval of application’s current and historic information in a generic fashion is addressed by the timeline service in Yarn.
1. Persisting application specific information
The collection or retrieval of information completely specific to a specific application or framework. For Example, Hadoop MapReduce framework consists the pieces of information about the map task, reduce task and counters.
Application developer publishes their specific information to the Timeline Server via TimeLineClient in the application Master or application container.
2. Persisting general information about completed applications
Generic information includes application-level data such as:
- Queue-name
- User information and the like set in the ApplicationSubmissionContext
- Info about each application-attempt
- A list of application-attempts that ran for an application
- The list of containers run under each application-attempt
- Information about each container
Yarn Timeline service version 2
It is the major iteration of the timeline server. Thus, V2 addresses two major challenges:
- The previous version does not well scale up beyond small cluster.
- And single instance available for the write and read.
Hence, In the v2 there is a different collector for write and read, it uses distributed collector, one collector for each Yarn application.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





Very nicely explained YARN features, architecture and high availability of YARN in Hadoop2
Very nicely explained YARN features and characteristics that make it so popular and useful in industry.
very useful for me…
Please upload more about Yarn..
Very nice YARN document and it is useful to increase my knowledge in hadoop