Hadoop Architecture in Detail – HDFS, Yarn & MapReduce
Hadoop now has become a popular solution for today’s world needs. The design of Hadoop keeps various goals in mind. These are fault tolerance, handling of large datasets, data locality, portability across heterogeneous hardware and software platforms etc. In this blog, we will explore the Hadoop Architecture in detail. Also, we will see Hadoop Architecture Diagram that helps you to understand it better.
So, let’s explore Hadoop Architecture.
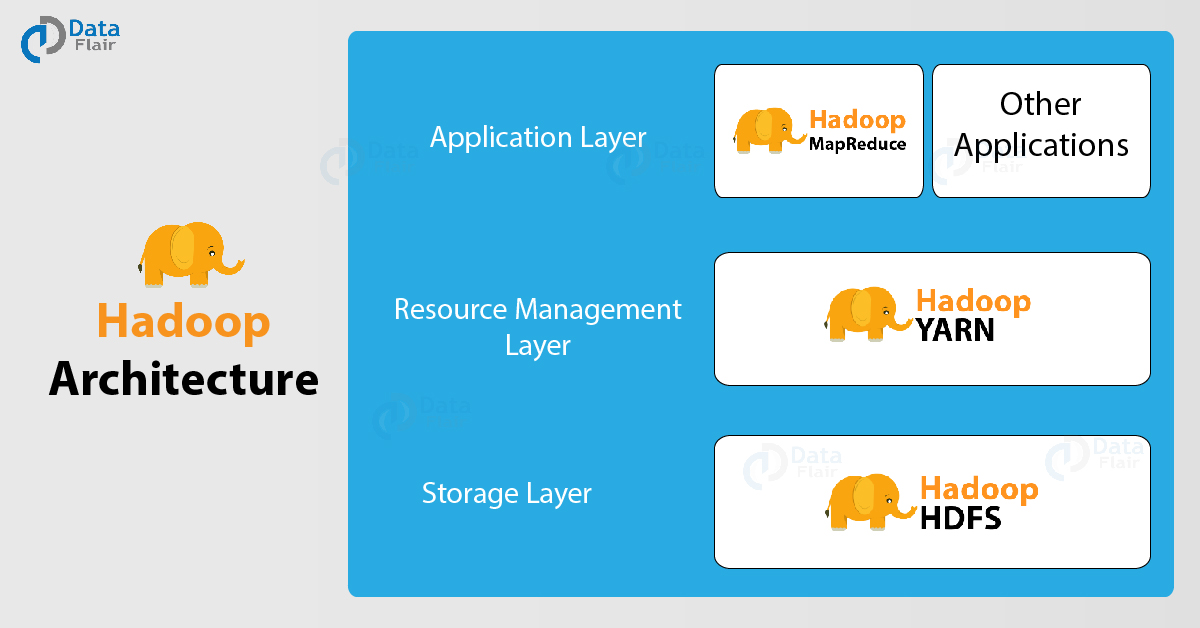
What is Hadoop Architecture?
Hadoop has a master-slave topology. In this topology, we have one master node and multiple slave nodes. Master node’s function is to assign a task to various slave nodes and manage resources. The slave nodes do the actual computing. Slave nodes store the real data whereas on master we have metadata. This means it stores data about data. What does metadata comprise that we will see in a moment?
Hadoop Application Architecture in Detail
Hadoop Architecture comprises three major layers. They are:-
- HDFS (Hadoop Distributed File System)
- Yarn
- MapReduce
1. HDFS
HDFS stands for Hadoop Distributed File System. It provides for data storage of Hadoop. HDFS splits the data unit into smaller units called blocks and stores them in a distributed manner. It has got two daemons running. One for master node – NameNode and other for slave nodes – DataNode.
a. NameNode and DataNode
HDFS has a Master-slave architecture. The daemon called NameNode runs on the master server. It is responsible for Namespace management and regulates file access by the client. DataNode daemon runs on slave nodes. It is responsible for storing actual business data. Internally, a file gets split into a number of data blocks and stored on a group of slave machines. Namenode manages modifications to file system namespace. These are actions like the opening, closing and renaming files or directories. NameNode also keeps track of mapping of blocks to DataNodes. This DataNodes serves read/write request from the file system’s client. DataNode also creates, deletes and replicates blocks on demand from NameNode.
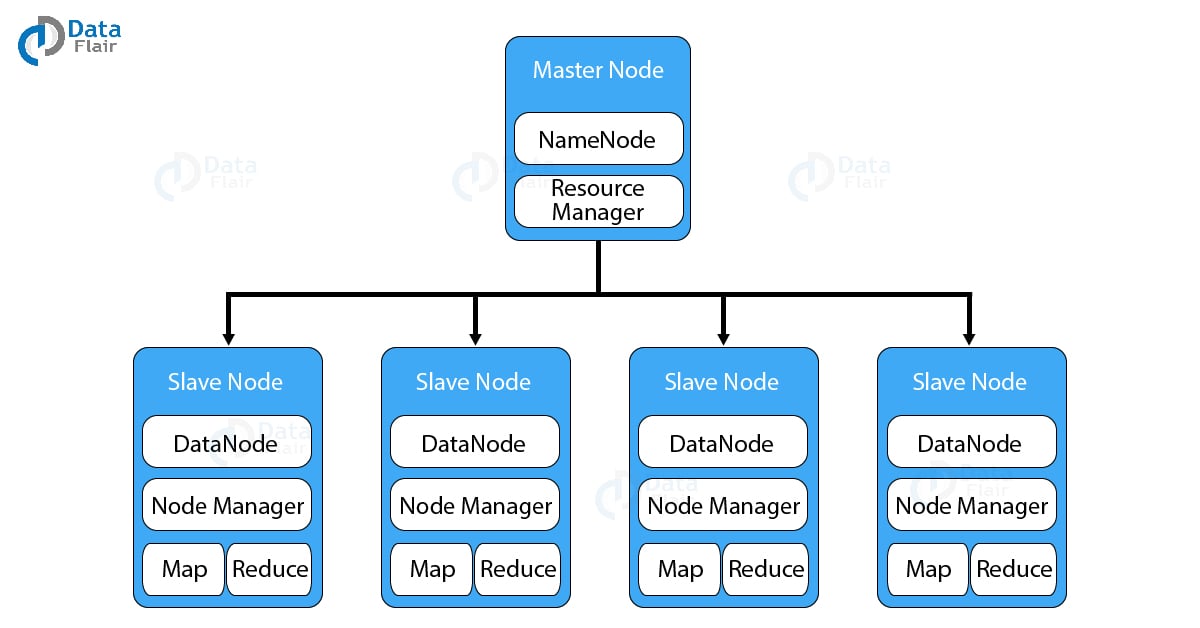
Java is the native language of HDFS. Hence one can deploy DataNode and NameNode on machines having Java installed. In a typical deployment, there is one dedicated machine running NameNode. And all the other nodes in the cluster run DataNode. The NameNode contains metadata like the location of blocks on the DataNodes. And arbitrates resources among various competing DataNodes.
You must read about Hadoop High Availability Concept
b. Block in HDFS
Block is nothing but the smallest unit of storage on a computer system. It is the smallest contiguous storage allocated to a file. In Hadoop, we have a default block size of 128MB or 256 MB.

One should select the block size very carefully. To explain why so let us take an example of a file which is 700MB in size. If our block size is 128MB then HDFS divides the file into 6 blocks. Five blocks of 128MB and one block of 60MB. What will happen if the block is of size 4KB? But in HDFS we would be having files of size in the order terabytes to petabytes. With 4KB of the block size, we would be having numerous blocks. This, in turn, will create huge metadata which will overload the NameNode. Hence we have to choose our HDFS block size judiciously.
c. Replication Management
To provide fault tolerance HDFS uses a replication technique. In that, it makes copies of the blocks and stores in on different DataNodes. Replication factor decides how many copies of the blocks get stored. It is 3 by default but we can configure to any value.
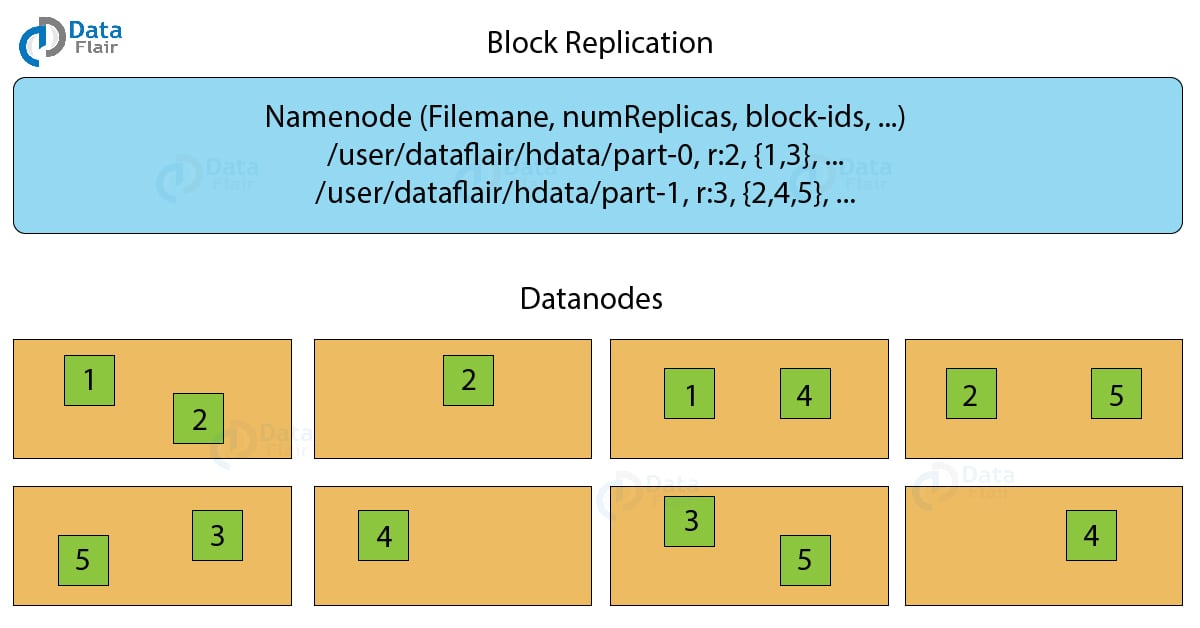
The above figure shows how the replication technique works. Suppose we have a file of 1GB then with a replication factor of 3 it will require 3GBs of total storage.
To maintain the replication factor NameNode collects block report from every DataNode. Whenever a block is under-replicated or over-replicated the NameNode adds or deletes the replicas accordingly.
d. What is Rack Awareness?
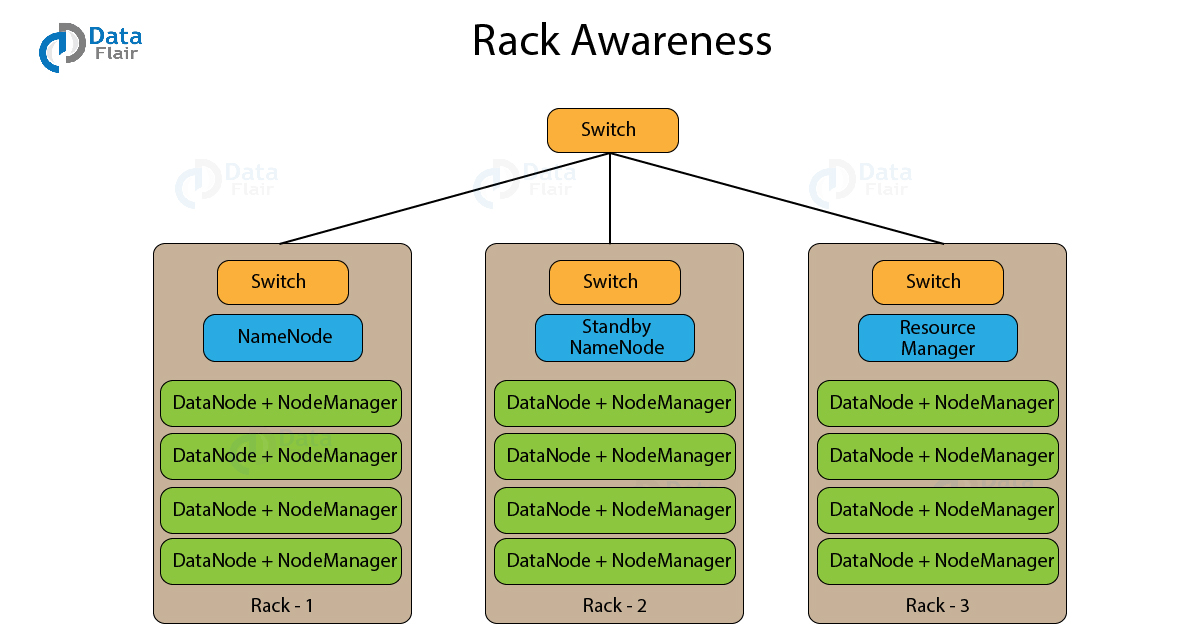
A rack contains many DataNode machines and there are several such racks in the production. HDFS follows a rack awareness algorithm to place the replicas of the blocks in a distributed fashion. This rack awareness algorithm provides for low latency and fault tolerance. Suppose the replication factor configured is 3. Now rack awareness algorithm will place the first block on a local rack. It will keep the other two blocks on a different rack. It does not store more than two blocks in the same rack if possible.
2. MapReduce
MapReduce is the data processing layer of Hadoop. It is a software framework that allows you to write applications for processing a large amount of data. MapReduce runs these applications in parallel on a cluster of low-end machines. It does so in a reliable and fault-tolerant manner.
MapReduce job comprises a number of map tasks and reduces tasks. Each task works on a part of data. This distributes the load across the cluster. The function of Map tasks is to load, parse, transform and filter data. Each reduce task works on the sub-set of output from the map tasks. Reduce task applies grouping and aggregation to this intermediate data from the map tasks.
The input file for the MapReduce job exists on HDFS. The inputformat decides how to split the input file into input splits. Input split is nothing but a byte-oriented view of the chunk of the input file. This input split gets loaded by the map task. The map task runs on the node where the relevant data is present. The data need not move over the network and get processed locally.
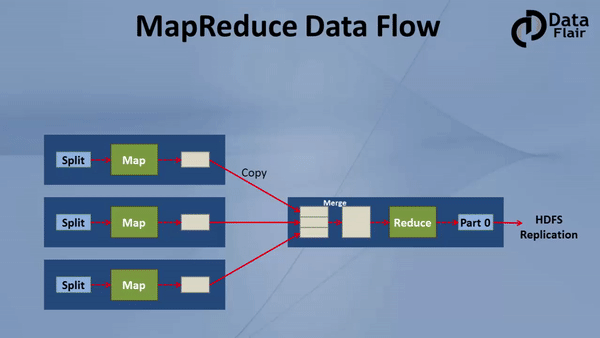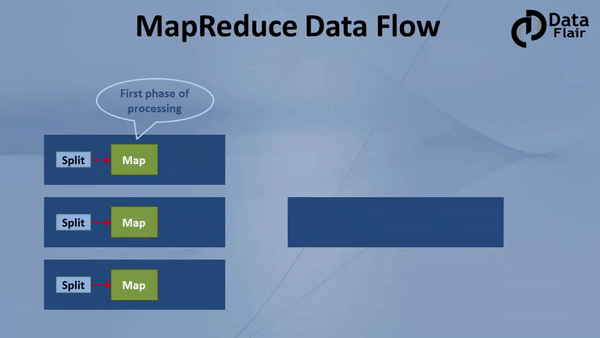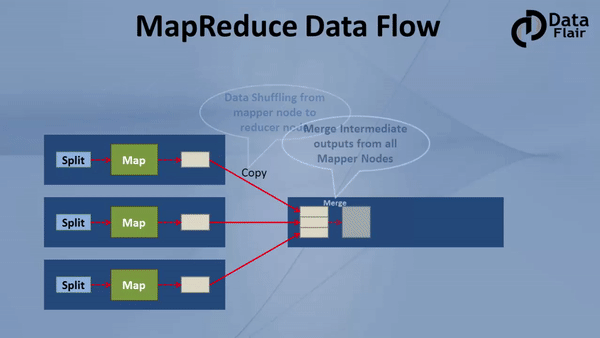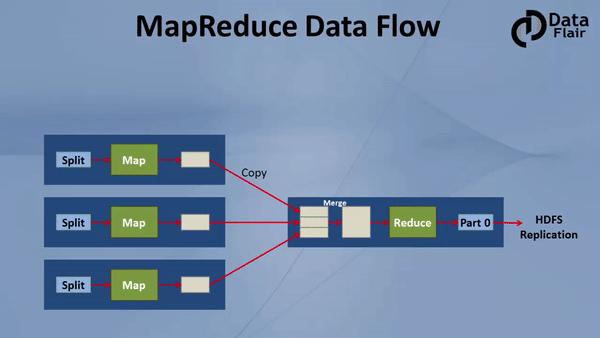
i. Map Task
The Map task run in the following phases:-
a. RecordReader
The recordreader transforms the input split into records. It parses the data into records but does not parse records itself. It provides the data to the mapper function in key-value pairs. Usually, the key is the positional information and value is the data that comprises the record.
b. Map
In this phase, the mapper which is the user-defined function processes the key-value pair from the recordreader. It produces zero or multiple intermediate key-value pairs.
The decision of what will be the key-value pair lies on the mapper function. The key is usually the data on which the reducer function does the grouping operation. And value is the data which gets aggregated to get the final result in the reducer function.
c. Combiner
The combiner is actually a localized reducer which groups the data in the map phase. It is optional. Combiner takes the intermediate data from the mapper and aggregates them. It does so within the small scope of one mapper. In many situations, this decreases the amount of data needed to move over the network. For example, moving (Hello World, 1) three times consumes more network bandwidth than moving (Hello World, 3). Combiner provides extreme performance gain with no drawbacks. The combiner is not guaranteed to execute. Hence it is not of overall algorithm.
d. Partitioner
Partitioner pulls the intermediate key-value pairs from the mapper. It splits them into shards, one shard per reducer. By default, partitioner fetches the hashcode of the key. The partitioner performs modulus operation by a number of reducers: key.hashcode()%(number of reducers). This distributes the keyspace evenly over the reducers. It also ensures that key with the same value but from different mappers end up into the same reducer. The partitioned data gets written on the local file system from each map task. It waits there so that reducer can pull it.
b. Reduce Task
The various phases in reduce task are as follows:
i. Shuffle and Sort
The reducer starts with shuffle and sort step. This step downloads the data written by partitioner to the machine where reducer is running. This step sorts the individual data pieces into a large data list. The purpose of this sort is to collect the equivalent keys together. The framework does this so that we could iterate over it easily in the reduce task. This phase is not customizable. The framework handles everything automatically. However, the developer has control over how the keys get sorted and grouped through a comparator object.
ii. Reduce
The reducer performs the reduce function once per key grouping. The framework passes the function key and an iterator object containing all the values pertaining to the key.
We can write reducer to filter, aggregate and combine data in a number of different ways. Once the reduce function gets finished it gives zero or more key-value pairs to the outputformat. Like map function, reduce function changes from job to job. As it is the core logic of the solution.
iii. OutputFormat
This is the final step. It takes the key-value pair from the reducer and writes it to the file by recordwriter. By default, it separates the key and value by a tab and each record by a newline character. We can customize it to provide richer output format. But none the less final data gets written to HDFS.

3. YARN
YARN or Yet Another Resource Negotiator is the resource management layer of Hadoop. The basic principle behind YARN is to separate resource management and job scheduling/monitoring function into separate daemons. In YARN there is one global ResourceManager and per-application ApplicationMaster. An Application can be a single job or a DAG of jobs.
Inside the YARN framework, we have two daemons ResourceManager and NodeManager. The ResourceManager arbitrates resources among all the competing applications in the system. The job of NodeManger is to monitor the resource usage by the container and report the same to ResourceManger. The resources are like CPU, memory, disk, network and so on.
The ApplcationMaster negotiates resources with ResourceManager and works with NodeManger to execute and monitor the job.
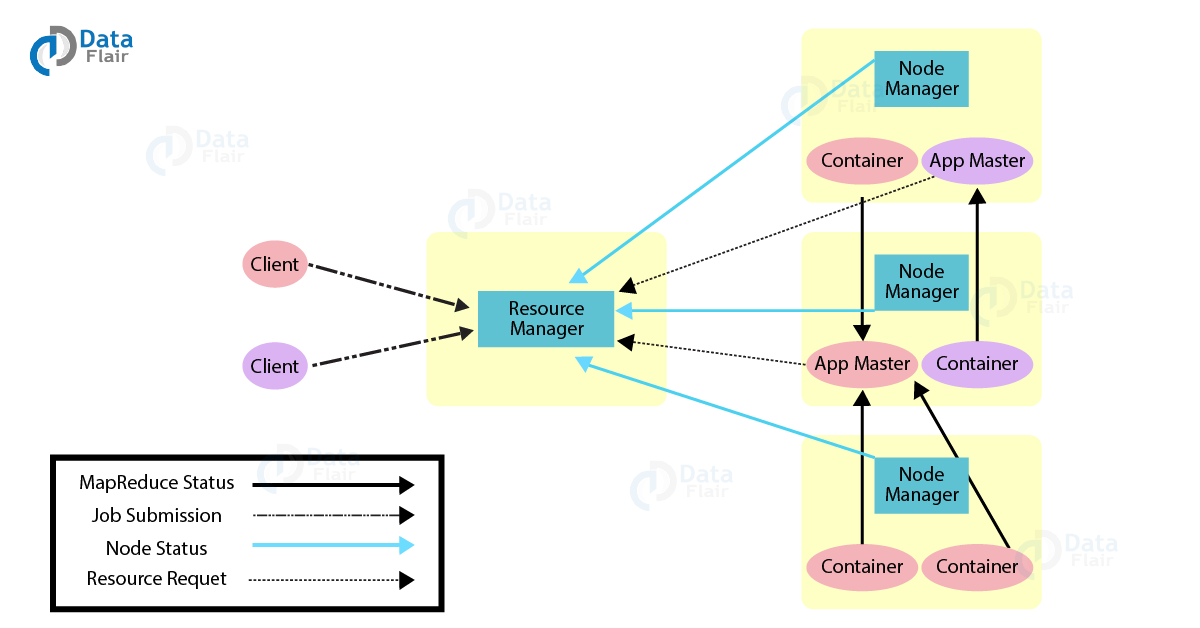
The ResourceManger has two important components – Scheduler and ApplicationManager
i. Scheduler
Scheduler is responsible for allocating resources to various applications. This is a pure scheduler as it does not perform tracking of status for the application. It also does not reschedule the tasks which fail due to software or hardware errors. The scheduler allocates the resources based on the requirements of the applications.
ii. Application Manager
Following are the functions of ApplicationManager
- Accepts job submission.
- Negotiates the first container for executing ApplicationMaster. A container incorporates elements such as CPU, memory, disk, and network.
- Restarts the ApplicationMaster container on failure.
Functions of ApplicationMaster:-
- Negotiates resource container from Scheduler.
- Tracks the resource container status.
- Monitors progress of the application.
We can scale the YARN beyond a few thousand nodes through YARN Federation feature. This feature enables us to tie multiple YARN clusters into a single massive cluster. This allows for using independent clusters, clubbed together for a very large job.
iii. Features of Yarn
YARN has the following features:-
a. Multi-tenancy
YARN allows a variety of access engines (open-source or propriety) on the same Hadoop data set. These access engines can be of batch processing, real-time processing, iterative processing and so on.
b. Cluster Utilization
With the dynamic allocation of resources, YARN allows for good use of the cluster. As compared to static map-reduce rules in previous versions of Hadoop which provides lesser utilization of the cluster.
c. Scalability
Any data center processing power keeps on expanding. YARN’s ResourceManager focuses on scheduling and copes with the ever-expanding cluster, processing petabytes of data.
d. Compatibility
MapReduce program developed for Hadoop 1.x can still on this YARN. And this is without any disruption to processes that already work.
Best Practices For Hadoop Architecture Design
i. Embrace Redundancy Use Commodity Hardware
Many companies venture into Hadoop by business users or analytics group. The infrastructure folks peach in later. These people often have no idea about Hadoop. The result is the over-sized cluster which increases the budget many folds. Hadoop was mainly created for availing cheap storage and deep data analysis. To achieve this use JBOD i.e. Just a Bunch Of Disk. Also, use a single power supply.
ii. Start Small and Keep Focus
Many projects fail because of their complexity and expense. To avoid this start with a small cluster of nodes and add nodes as you go along. Start with a small project so that infrastructure and development guys can understand the internal working of Hadoop.
iii. Create Procedure For Data Integration
One of the features of Hadoop is that it allows dumping the data first. And we can define the data structure later. We can get data easily with tools such as Flume and Sqoop. But it is essential to create a data integration process. This includes various layers such as staging, naming standards, location etc. Make proper documentation of data sources and where they live in the cluster.
iv. Use Compression Technique
Enterprise has a love-hate relationship with compression. There is a trade-off between performance and storage. Although compression decreases the storage used it decreases the performance too. But Hadoop thrives on compression. It can increase storage usage by 80%.
v. Create Multiple Environments
It is a best practice to build multiple environments for development, testing, and production. As Apache Hadoop has a wide ecosystem, different projects in it have different requirements. Hence there is a need for a non-production environment for testing upgrades and new functionalities.
Summary
Hence, in this Hadoop Application Architecture, we saw the design of Hadoop Architecture is such that it recovers itself whenever needed. Its redundant storage structure makes it fault-tolerant and robust. We are able to scale the system linearly. The MapReduce part of the design works on the principle of data locality. The Map-Reduce framework moves the computation close to the data. Therefore decreasing network traffic which would otherwise have consumed major bandwidth for moving large datasets. Thus overall architecture of Hadoop makes it economical, scalable and efficient big data technology.
Hadoop Architecture is a very important topic for your Hadoop Interview. We recommend you to once check most asked Hadoop Interview questions. You will get many questions from Hadoop Architecture.
Did you enjoy reading Hadoop Architecture? Do share your thoughts with us.
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





Beautifully explained, I am new to Hadoop concepts but because of these articles I am gaining lot of confidence very quick.
Hey Rachna,
Thank you for visiting DataFlair. Hadoop is a popular and widely-used Big Data framework used in Data Science as well. We are glad you found our tutorial on “Hadoop Architecture” informative. If you are interested in Hadoop, DataFlair also provides a Big Data Hadoop course. You can check the details and grab the opportunity.
I heard in one of the videos for Hadoop default block size is 64MB can you please let me know which one is correct.
May I also know why do we have two default block sizes 128 MB and 256 MB can we consider anyone size or any specific reason for this
Hello Nandini,
The default block size in Hadoop 1 is 64 MB, but after the release of Hadoop 2, the default block size in all the later releases of Hadoop is 128 MB. We do not have two different default sizes. The default size is 128 MB, which can be configured to 256 MB depending on our requirement. We choose block size depending on the cluster capacity.
For example, if we have commodity hardware having 8 GB of RAM, then we will keep the block size little smaller like 64 MB. However, if we have high-end machines in the cluster having 128 GB of RAM, then we will keep block size as 256 MB to optimize the MapReduce jobs.
useful infromation