History of Hadoop – The complete evolution of Hadoop Ecosytem
Let’s take a look at the history of Hadoop and its evolution in the last two decades and why it continues to be the backbone of the big data industry.
Hadoop is an open-source software framework for storing and processing large datasets ranging in size from gigabytes to petabytes. Hadoop was developed at the Apache Software Foundation.
In 2008, Hadoop defeated the supercomputers and became the fastest system on the planet for sorting terabytes of data.
This article describes the evolution of Hadoop over a period.
History of Hadoop
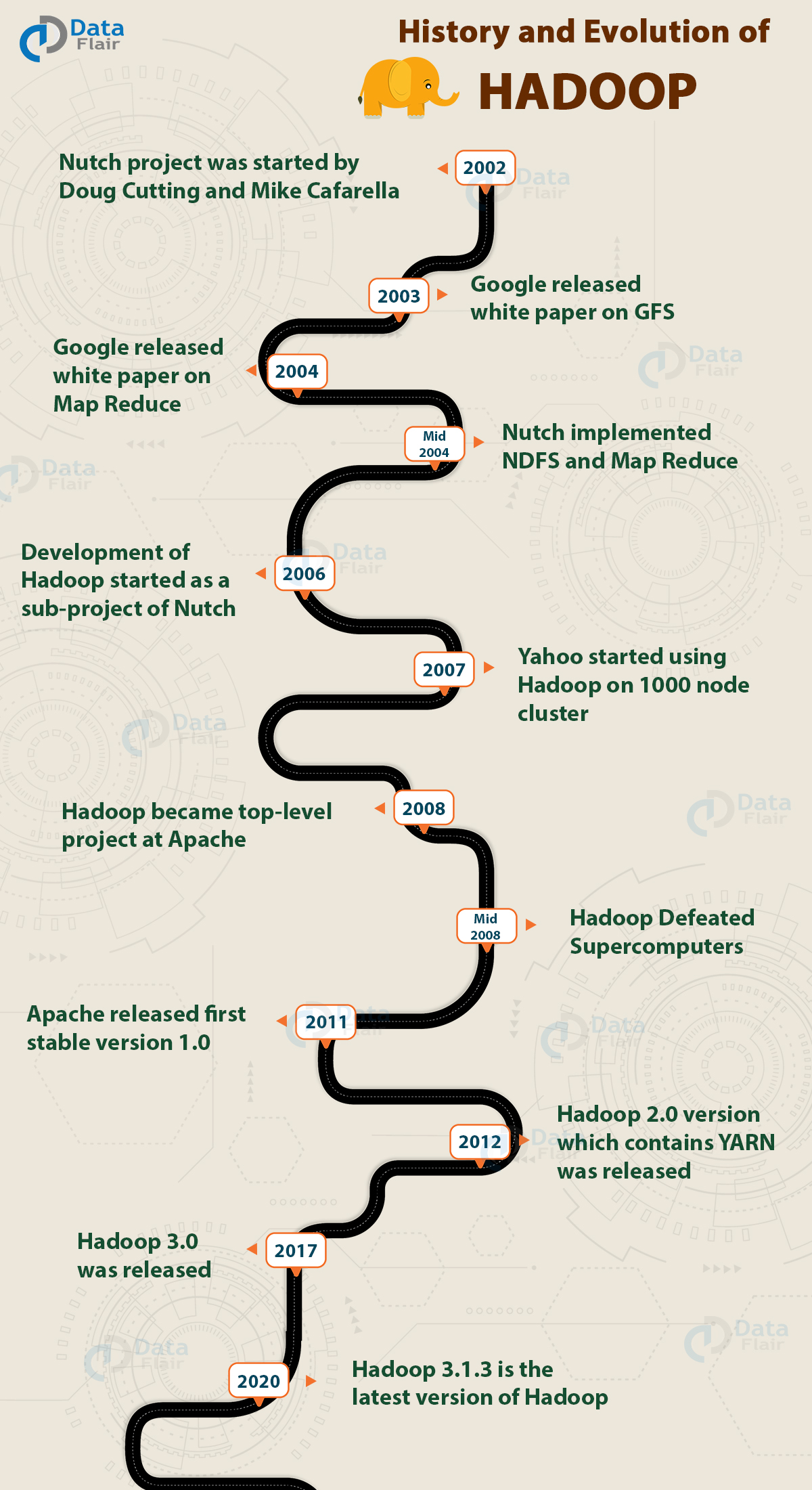
2002
It all started in the year 2002 with the Apache Nutch project.
In 2002, Doug Cutting and Mike Cafarella were working on Apache Nutch Project that aimed at building a web search engine that would crawl and index websites.
After a lot of research, Mike Cafarella and Doug Cutting estimated that it would cost around $500,000 in hardware with a monthly running cost of $30,000 for a system supporting a one-billion-page index.
This project proved to be too expensive and thus found infeasible for indexing billions of webpages. So they were looking for a feasible solution that would reduce the cost.
2003
Meanwhile, In 2003 Google released a search paper on Google distributed File System (GFS) that described the architecture for GFS that provided an idea for storing large datasets in a distributed environment. This paper solved the problem of storing huge files generated as a part of the web crawl and indexing process. But this is half of a solution to their problem.
2004
In 2004, Nutch’s developers set about writing an open-source implementation, the Nutch Distributed File System (NDFS).
In 2004, Google introduced MapReduce to the world by releasing a paper on MapReduce. This paper provided the solution for processing those large datasets. It gave a full solution to the Nutch developers.
Google provided the idea for distributed storage and MapReduce. Nutch developers implemented MapReduce in the middle of 2004.
2006
The Apache community realized that the implementation of MapReduce and NDFS could be used for other tasks as well. In February 2006, they came out of Nutch and formed an independent subproject of Lucene called “Hadoop” (which is the name of Doug’s kid’s yellow elephant).
As the Nutch project was limited to 20 to 40 nodes cluster, Doug Cutting in 2006 itself joined Yahoo to scale the Hadoop project to thousands of nodes cluster.
2007
In 2007, Yahoo started using Hadoop on 1000 nodes cluster.
2008
In January 2008, Hadoop confirmed its success by becoming the top-level project at Apache.
By this time, many other companies like Last.fm, Facebook, and the New York Times started using Hadoop.
Hadoop Defeated supercomputers
In April 2008, Hadoop defeated supercomputers and became the fastest system on the planet by sorting an entire terabyte of data.
In November 2008, Google reported that its Mapreduce implementation sorted 1 terabyte in 68 seconds.
In April 2009, a team at Yahoo used Hadoop to sort 1 terabyte in 62 seconds, beaten Google MapReduce implementation.
Various Release of Hadoop
2011 – 2012
On 27 December 2011, Apache released Hadoop version 1.0 that includes support for Security, Hbase, etc.
On 10 March 2012, release 1.0.1 was available. This is a bug fix release for version 1.0.
On 23 May 2012, the Hadoop 2.0.0-alpha version was released. This release contains YARN.
The second (alpha) version in the Hadoop-2.x series with a more stable version of YARN was released on 9 October 2012.
2017 – now
On 13 December 2017, release 3.0.0 was available
On 25 March 2018, Apache released Hadoop 3.0.1, which contains 49 bug fixes in Hadoop 3.0.0.
On 6 April 2018, Hadoop release 3.1.0 came that contains 768 bug fixes, improvements, and enhancements since 3.0.0.
Later, in May 2018, Hadoop 3.0.3 was released.
On 8 August 2018, Apache 3.1.1 was released.
Hadoop 3.1.3 is the latest version of Hadoop.
Wondering to install Hadoop 3.1.3? Follow the Step-by-step Installation tutorial and install it now!
Summary
That’s the History of Hadoop in brief points.
I hope after reading this article, you understand Hadoop’s journey and how Hadoop confirmed its success and became the most popular big data analysis tool.
Now it is your turn to take a ride and evolve yourself in the Big Data industry with the Hadoop course.
Keep Executing!!
Did we exceed your expectations?
If Yes, share your valuable feedback on Google




