HBase Compaction and Data Locality in Hadoop
In this Hadoop HBase tutorial of HBase Compaction and Data Locality with Hadoop, we will learn the whole concept of Minor and Major Compaction in HBase, a process by which HBase cleans itself in detail.
Also, we will see Data Locality with Hadoop Compaction because data locality is a solution to data not being available to Mapper.
So, let’s start HBase Compaction and Data Locality in Hadoop.
What is HBase Compaction?
As we know, for read performance, HBase is an optimized distributed data store. But this optimal read performance needs one file per column family. Although, during the heavy writes, it is not always possible to have one file per column family.
Hence, to reduce the maximum number of disk seeks needed for read, HBase tries to combine all HFiles into a large single HFile. So, this process is what we call Compaction.
In other words, Compaction in HBase is a process by which HBase cleans itself, whereas this process is of two types: Minor HBase Compaction as well as Major HBase Compaction.
a. HBase Minor Compaction
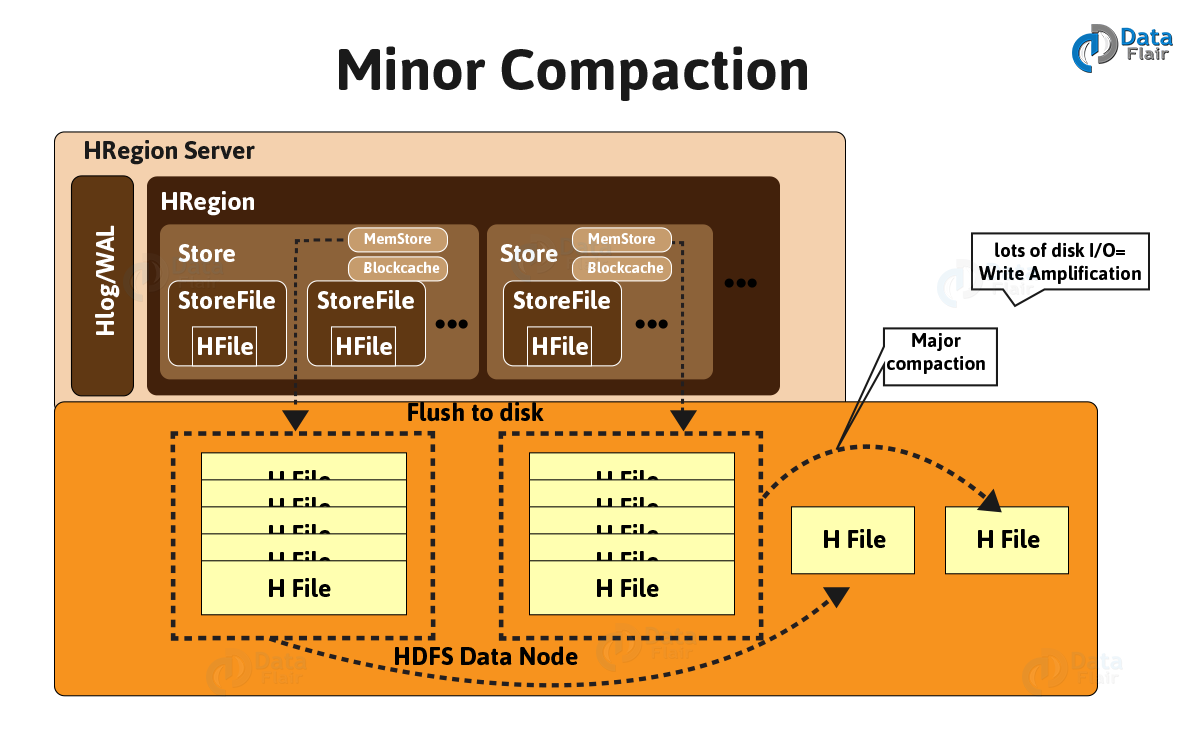
The process of combining the configurable number of smaller HFiles into one large HFile is what we call Minor compaction. Though, it is quite important since, reading particular rows needs many disk reads and may reduce overall performance, without it.
Here are the several processes which involve in HBase Minor Compaction, are:
- By combining smaller Hfiles, it creates bigger Hfile.
- Also, Hfile stores the deleted file along with it.
- To store more data increases space in memory.
- Uses merge sorting.
HBase Compaction
b. HBase Major compaction
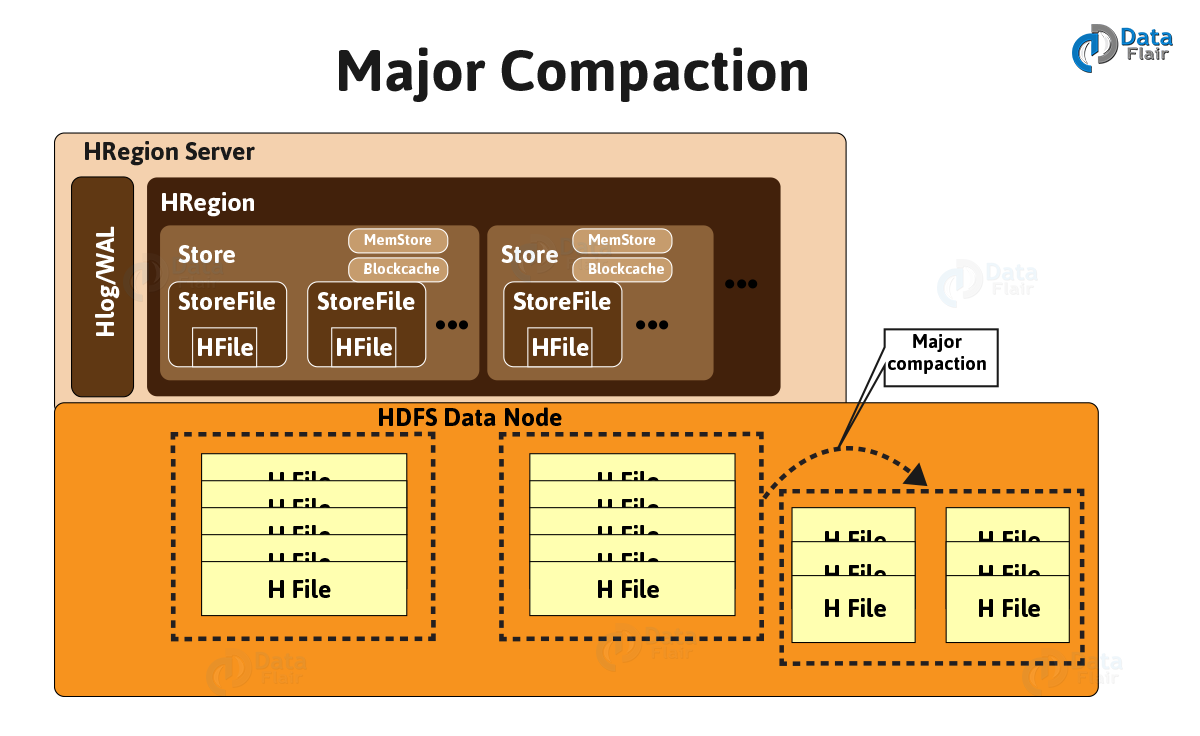
Whereas, a process of combining the StoreFiles of regions into a single StoreFile, is what we call HBase Major Compaction. Also, it deletes remove and expired versions. As a process, it merges all StoreFiles into single StoreFile and also runs every 24 hours.
However, the region will split into new regions after compaction, if the new larger StoreFile is greater than a certain size (defined by property).
Well, the HBase Major Compaction in HBase is the other way to go around:
- Data present per column family in one region is accumulated to 1 Hfile.
- All deleted files or expired cells are deleted permanently, during this process.
- Increase read performance of newly created Hfile.
- It accepts lots of I/O.
- Possibilities for traffic congestion.
- The other name of major compaction process is Write amplification Process.
- And it is must schedule this process at a minimum bandwidth of network I/O.
HBase Major Compaction
HBase Compaction Tuning
a. Short Description of HBase Compaction:
Now, to enhance performance and stability of the HBase cluster, we can use some hidden HBase compaction configuration like below.
b. Disabling Automatic Major Compactions in HBase
Generally, HBase users ask to possess a full management of major compaction events hence the method to do that is by setting HBase.hregion.majorcompaction to 0, disable periodic automatic major compactions in HBase.
However, it does not offer 100% management of major compactions, yet, by HBase automatically, minor compactions can be promoted to major ones, sometimes, although, we’ve got another configuration choice, luckily, that will help during this case.
c. Maximum HBase Compaction Selection Size
Control compaction process in HBase is another option:
hbase.hstore.compaction.max.size (by default value is set to LONG.MAX_VALUE)
In HBase 1.2+ we have as well:
hbase.hstore.compaction.max.size.offpeak
d. Off-peak Compactions in HBase
Further, we can use off-peak configuration settings, if our deployment has off-peak hours.
Here are HBase Compaction Configuration options must set, to enable off peak compaction:
hbase.offpeak.start.hour= 0..23
hbase.offpeak.end.hour= 0..23
Compaction file ratio for off peak 5.0 (by default) or for peak hours is 1.2.
Both can be changed:
hbase.hstore.compaction.ratio
hbase.hstore.compaction.ratio.offpeak
As much high the file ratio value will be, the more will be the aggressive (frequent) compaction. So, for the majority of deployments, default values are fine.
Data Locality in Hadoop
As we know, in Hadoop, Datasets is stored in HDFS. Basically, it is divided into blocks as well as stored among the data nodes in a Hadoop cluster. Though, the individual Mappers will process the blocks (input splits), while a MapReduce job is executed against the dataset.
However, data has to copy over the network from the data node that has data to the data node that is executing the Mapper task, when data is not available for Mapper in the same node. So, it is what we call data Locality in Hadoop.
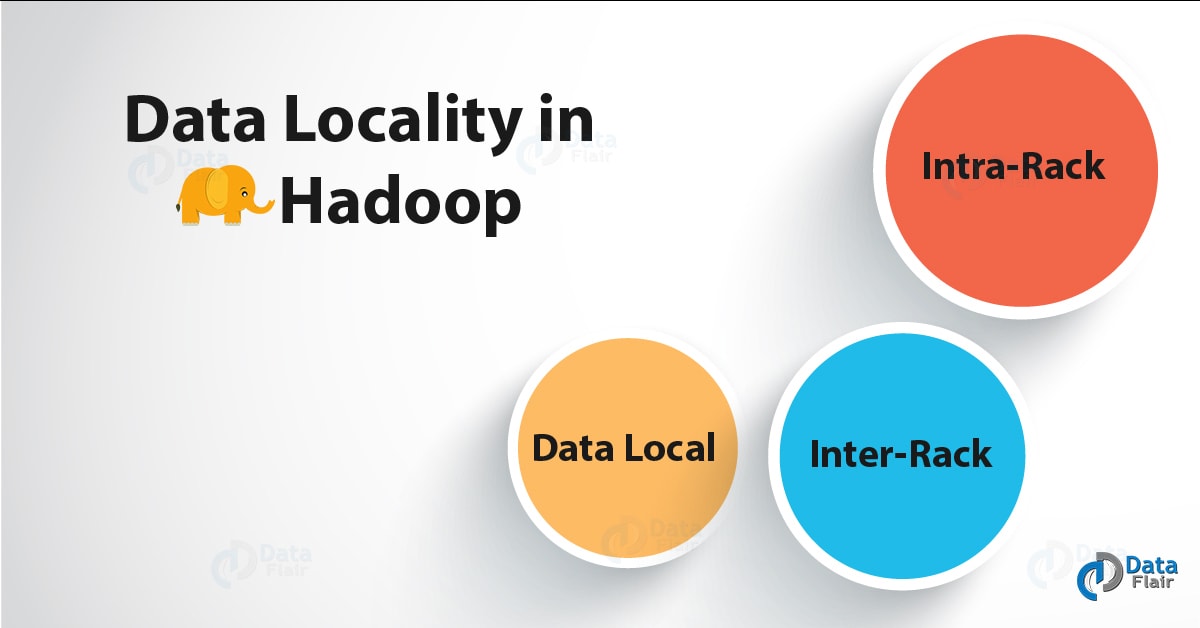
In Hadoop, there are 3 categories of Data Locality, such as:
Data Locality in Hadoop
1. Data Local Data Locality
Data local data locality is when data is located on the same node as the mapper working on the data. In this case, the proximity of data is very near to computation. Basically, it is the highly preferable option.
2. Intra-Rack Data Locality
However, because of resource constraints, it is always not possible to execute the Mapper on the same node. Hence at that time, the Mapper executes on another node within the same rack as the node that has data. So, this is what we call intra-rack data locality.
3. Inter-Rack Data Locality
Well, there is a case when we are not able to achieve intra-rack locality as well as data locality because of resource constraints.
So, at that time we need to execute the mapper on nodes on different racks, and also then the data copy from the node that has data to the node executing mapper between racks.
So, this is what we call inter-rack data locality. Although, this option is less preferable.
So, this was all in HBase Compaction and Data Locality in Hadoop. Hope you like our explanation.
Conclusion: HBase Compaction
Hence, in this Hadoop HBase tutorial of HBase Compaction and Data Locality, we have seen the cleaning process of HBase that is HBase Compaction. Also, we have seen a solution to data not being available to Mapper, Apache Hadoop Data Locality in detail.
Hope it helps! Please share your experience through comments on our HBase Compaction explanation.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google




