Hadoop for Data Science – Concepts You can’t Afford to Miss
Machine Learning courses with 100+ Real-time projects Start Now!!
Looking for the answer to why you need to learn Hadoop for Data Science? You landed on the right page.
Here you will find why Hadoop is must for the data scientist. At the end of this article, I will share a case study where you will learn how Marks & Spencer Company is using Hadoop for its data science requirements. So, without wasting the time let’s move on to the topic-
Currently, data is increasing at an exponential rate. There is a huge demand for processing a high volume of data. One such technology that is responsible for processing large volumes of data is Hadoop. Here is what exactly Hadoop Means –
What is Hadoop?
Apache Hadoop is open-source software that facilitates a network of computers to solve problems that require massive datasets and computation power. Hadoop is highly scalable, that is designed to accommodate computation ranging from a single server to a cluster of thousands of machines.
While Hadoop is written in Java, you can program in Hadoop using multiple languages like Python, C++, Perl, Ruby etc.
The concepts of Big Data like MapReduce became a widespread phenomenon after Google published its research paper that also described its Google File System.
There are three main components of Hadoop –
Hadoop Distributed Filesystem – It is the storage component of Hadoop. Hadoop is a collection of master-slave networks. In HDFS there are two daemons – namenode and datanode that run on the master and slave nodes respectively.
Map-Reduce – This part of Hadoop is responsible for high-level data processing. It facilitates processing of a large amount of data over the cluster of nodes.
YARN – It is used for resource management and job scheduling. In a multi-node cluster, it is difficult to manage, allocate and release the resources. Hadoop Yarn allows to manage and control these resources very efficiently.
To learn everything about Hadoop, you must check the latest Hadoop Tutorial Series.
Hadoop for Data Science
Do Data Scientists need Hadoop?
Answer to this question is a big YES! Hadoop is a must for Data Scientists.
Data Science is a vast field. It stems from multiple interdisciplinary fields like mathematics, statistics, and programming. It is about finding patterns in data.
Data Scientists are trained for extracting, analyzing and generating predictions from the data. It is an umbrella term that incorporates almost every technology that involves the use of data.
The main functionality of Hadoop is storage of Big Data. It also allows the users to store all forms of data, that is, both structured data and unstructured data. Hadoop also provides modules like Pig and Hive for analysis of large scale data.
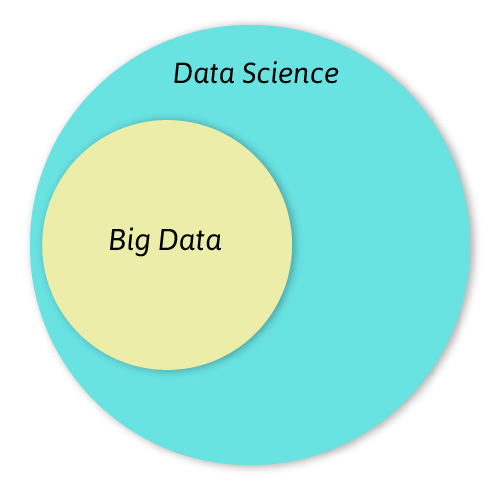
However, the difference between data science and big data is that the former is a discipline that involves all the data operations. As a result, Big Data is a part of Data Science. Since Data Science contains a sea of information, it is not necessary to know Big Data.
However, the knowledge of Hadoop will certainly add up to your expertise, making you versatile at handling a colossal amount of data. This will also increase your value by a substantial margin in the market and give you a competitive edge over others.
Furthermore, as a Data Scientist, knowledge of Machine Learning is a must. Machine Learning algorithms perform much better with a larger dataset.
As such, big data becomes an ideal choice for training machine learning algorithms. Therefore, in order to understand the intricacies of Data Science, knowledge of big data is a must.
Hadoop – A First Step towards Data Science
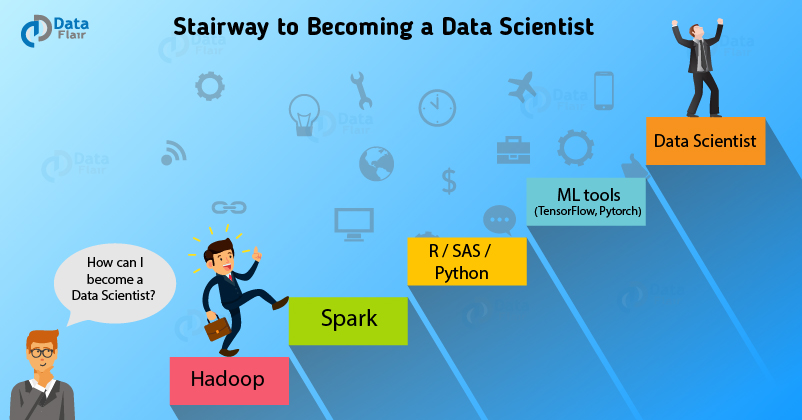
As the above image clearly shows the steps for becoming a Data Scientist, where Hadoop is must and a very first step.
Hadoop is one the popular big data platform that is most widely used for data operations involving large scale data. In order to take your first step towards becoming a fully-fledged data scientist, you must have the knowledge of handling large volumes of data as well as unstructured data.
For this purpose, Hadoop proves to be an ideal platform that allows its users to solve problems that involve massive amounts of data.
Furthermore, Hadoop is an ideal data platform that provides you with not only the capability to handle large scale data but also analyze it using various extensions like Mahout and Hive.
Therefore, learning the entire breadth and width of Hadoop will provide you with the capability to handle diverse data operations which is the main task of a data scientist. Since, it constitutes a major portion of Data Science, learning Hadoop as an initial tool will provide you all the necessary knowledge.
It is the right time to Start your Big Data Hadoop Traning before someone else takes the opportunity
In the Hadoop ecosystem, writing machine learning code in Java over map-reduce becomes a very complicated procedure. Performing machine learning operations like classification, regression, clustering into a MapReduce framework become a difficult task.
In order to facilitate ease in analyzing data, Apache released two main components in Hadoop called Pig and Hive.
Furthermore, for carrying out machine learning operations on the data, Apache software foundation released Apache Mahout. Apache Mahout runs on the top of Hadoop that uses MapReduce as its principle paradigm.
A Data Scientist needs to be inclusive about all the data related operations. Therefore, having expertise at Big Data and Hadoop will allow you to develop a comprehensive architecture analyzes a colossal amount of data.
Why Hadoop?
Hadoop a Scalable Solution for Big Data
Hadoop Ecosystem has been hailed for its reliability and scalability. With the massive increase in information, it becomes increasingly difficult for the database systems to accommodate growing information.
Hadoop provides a scalable and a fault-tolerant architecture that allows massive information to be stored without any loss. Hadoop fosters two types of scalability:
Vertical Scalability – In vertical scaling, we add more resources (like CPUs) to the single node. In this way, we increase the hardware capacity of our Hadoop system. We can further add more RAM and CPU to it in order to enhance its power and make it more robust.
Horizontal Scalability – In Horizontal Scaling, we add more nodes or systems to the distributed software system. Unlike vertical scalability’s method of increasing capacity, we can add more machines without halting the system.
This eliminates the issue of downtime and gives maximum efficiency while scaling out. This also renders multiple machines that are working in parallel.
Anatomy of Hadoop
Some of the major components of Hadoop are –
- Hadoop Distributed File System (HDFS)
- MapReduce
- YARN
- Hive
- Pig
- HBase
For obtaining an in-depth insight of Hadoop, refer to the Hadoop Ecosystem blog by DataFlair.
Impact of Hadoop Usage on Data Scientist

Over the past few years, Hadoop has been increasingly used for implementing data science tools in the industries. With the assimilation of big data and data science, industries have been able to fully leverage data science. There are four main ways in which Hadoop has impacted Data Scientists –
1. Exploring Data with large scale datasets
Data Scientists are required to handle large volume of data. Previously, data scientists were confined to the local machine for storing their datasets. However, with the increase in data and a massive requirement for analyzing big data, Hadoop provides an environment for exploratory data analysis.
With Hadoop, you can write a MapReduce job, HIVE or a PIG script and launch it directly on Hadoop over to full dataset to obtain results.
2. Pre-processing Large Scale Data
Data Science roles require most of the data preprocessing to be carried out with data acquisition, transformation, cleanup, and feature extraction. This step is required to transform raw data into standardized feature vectors.
Hadoop makes large scale data-preprocessing an easy task for the data scientists. It provides tools like MapReduce, PIG, and Hive for efficiently handling large scale data.
3. Enforcing Data Agility
As opposed to traditional databases systems that required a strict schema structure, Hadoop facilitates a flexible schema for its users. This flexible schema or “schema on read” eliminates the need for schema redesign whenever a new field is needed.
4. Facilitating Large Scale Data Mining
It is proven that with larger datasets, machine learning algorithms train better and provide better results. Techniques like clustering, outlier detection, product recommenders provide a wide range of statistical techniques.
Traditionally, machine learning engineers had to deal with a limited amount of data, which ultimately resulted in the low performance of their models. However, with the help of Hadoop ecosystem that provides linear scalable storage, you can store all the data in RAW format.
Marks & Spencer Case Study – Using Big Data to Analyze Customer Behavior
Marks & Spencer is a major multinational retail company. It adopted Hadoop to have in-depth insight into customer behavior.
It scrutinizes data from multiple sources thereby giving a comprehensive understanding of the consumer behavior. M&S manages the efficient use of data to grasp customer insights.
It adopts a 360-degree view to have a comprehensive understanding of the customer purchase patterns and shopping across multiple channels. It makes the best use of Hadoop to not only store massive amounts of information but also analyzes it to develop in-depth insights about the customers.
During peak seasons like Christmas, where stocks often get depleted, Marks & Spencer are using big data analytics to track purchasing patterns of the customers in order to avert that from happening. It makes use of an effective data visualization tool to analyze information.
Therefore, creating conjunction of Hadoop and Predictive Analytics. Therefore, we realize that big data is one of the core components of data science and analytics.
Furthermore, Marks & Spencer has become one of the first industries to have a data-literate workforce. In one of the first initiatives, M&S is educating its employees about Machine Learning & Data Science.
It is your time to start learning Hadoop with industry experts. Select the best Hadoop training and upgrade one more skill for Data Science.
Summary
Hadoop is one of the original tools used in big data. It allows companies to store and process massive amounts of data across many computers. The Hadoop ecosystem includes HDFS (Hadoop Distributed File System) for storage and MapReduce for processing. It also works with tools like Hive, Pig, and Sqoop to make handling data easier. Hadoop made it possible to deal with terabytes and petabytes of data without expensive servers.
In data science, Hadoop is used to store raw data before analysis. For example, sensor logs, social media data, or website clickstreams are stored in Hadoop. You can then use Hive (SQL-like queries) to access and filter this data. Although tools like Spark have taken the lead in fast processing, Hadoop still plays a key role in batch processing and archival storage for long-term data.
Knowing Hadoop helps you understand the structure of big data systems. It teaches how distributed systems work, how to store structured and unstructured data, and how to manage resources in a cluster. Learning Hadoop prepares you for real-world challenges where data volume is too large for simple tools. Even today, many data lakes are built on Hadoop infrastructure, and it’s widely used in banks, telecoms, and retail industries.
Was this article useful? Please share your feedback through comments. This will help us to publish more such interesting content for you.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Hello Sir,
My name is Balaji, a Data science aspirant, I have lot of confusion regarding technical skills required to get a job in Data science field as a fresher in India, I have seen some of the companies asking
Big Data tools like: “Hadoop, Spark, Pig, Hive, HBase, Sqoop, MapReduce, Cassandra etc”
Business Analytic tools like: “SAS, R, Tableau, Microsoft Power BI, QlikSense”
cloud computing like: AWS, AZURE
SQL and No SQL
Linux etc
Kindly mail me what are the important technical skills, required to become a data scientist
Thanks & Regards
Hello sir, I have lot of confusion regarding technical skills required to get a job in Data science field as a fresher in India, I have seen some of the companies asking
Big Data tools like: “Hadoop, Spark, Pig, Hive, HBase, Sqoop, MapReduce, Cassandra etc” Business Analytic tools (like: “SAS, R, Tableau, Microsoft Power BI, QlikSense), cloud computing l(ike: AWS, AZURE), SQL, No SQL and Linux etc
Kindly mail me what are the important technical skills, required to become a data scientist