Hadoop Interview Questions and Answers – By Industry Experts
Hadoop Interview Questions and Answers
This blog post on Hadoop interview questions and answers if one of our most important article on Hadoop Blog. Interviews are very critical part of one’s career and it is important to know correct answers of the questions that are asked in the interview to gain enough knowledge and confidence. The Hadoop Interview Questions were prepared by the industry Experts at DataFlair. We have divided the whole post into 10 parts:
- Basic Questions And Answers for Hadoop HDFS Interview
- HDFS Hadoop Interview Question and Answer for Freshers
- Frequently Asked Question in Hadoop HDFS Interview
- HDFS Hadoop Interview Questions and Answers for Experienced
- Advanced Questions for Hadoop Interview
- Basic MapReduce Hadoop Interview Questions and Answers
- MapReduce Hadoop Interview Question and Answer for Freshers
- MapReduce Hadoop Interview Questions and Answers for Experienced
- Top Interview Questions for Hadoop MapReduce
- Advanced Interview Questions and Answers for Hadoop MapReduce
Hadoop Interview Questions for HDFS
These Hadoop Interview Questions and Answers for HDFS are from different components of HDFS. If you want to become a Hadoop Admin or Hadoop developer, then DataFlair is an appropriate place.
We were fully alert while framing these Hadoop Interview questions. Do comment your thoughts in comment section below.
In this section of Hadoop interview questions and answers, we have covered Hadoop interview questions and answers in detail. We have covered HDFS Hadoop interview questions and answers for freshers, HDFS Hadoop interview questions and answers for experienced as well as some advanced Hadoop interview questions and answers.

Hadoop Interview Questions and Answers – By Industry Experts
Basic Questions And Answers for Hadoop Interview
1) What is Hadoop HDFS – Hadoop Distributed File System?
Hadoop distributed file system-HDFS is the primary storage system of Hadoop. HDFS stores very large files running on a cluster of commodity hardware. It works on the principle of storage of less number of large files rather than the huge number of small files. HDFS stores data reliably even in the case of hardware failure. It also provides high throughput access to the application by accessing in parallel.
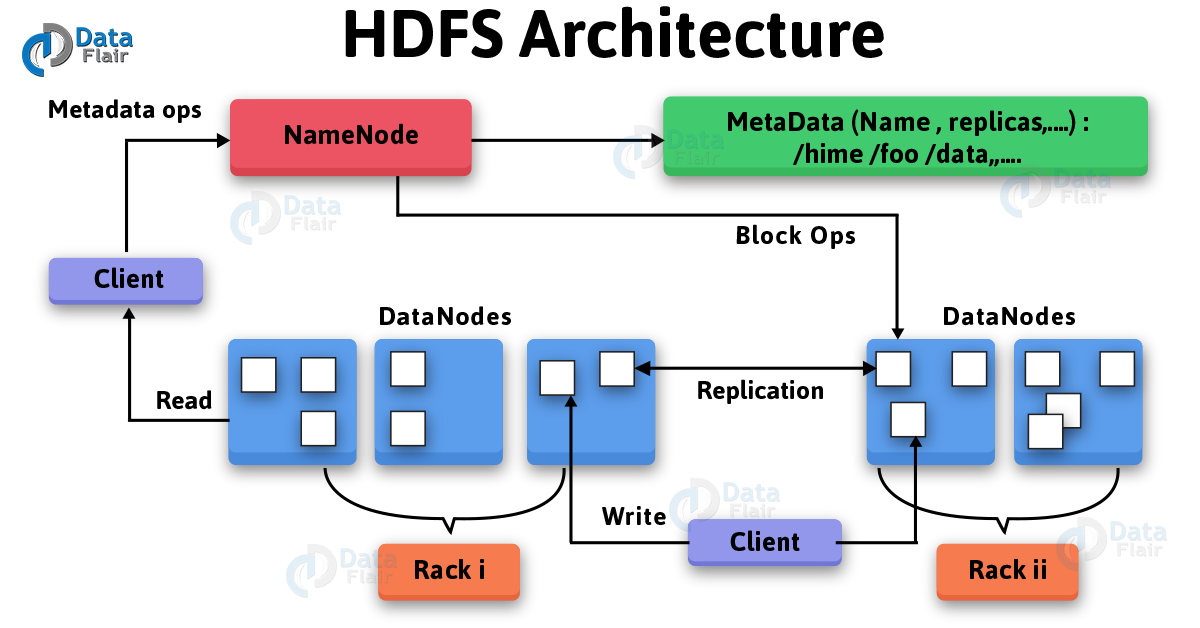
HDFS Architecture
Components of HDFS:
- NameNode – It works as Master in Hadoop cluster. Namenode stores meta-data i.e. number of blocks, replicas and other details. Meta-data is present in memory in the master to provide faster retrieval of data. NameNode maintains and also manages the slave nodes, and assigns tasks to them. It should deploy on reliable hardware as it is the centerpiece of HDFS.
- DataNode – It works as Slave in Hadoop cluster. In Hadoop HDFS, DataNode is responsible for storing actual data in HDFS. It also performs read and writes operation as per request for the clients. DataNodes can deploy on commodity hardware.
2) What are the key features of HDFS?
The various Features of HDFS are:
- Fault Tolerance – In Apache Hadoop HDFS, Fault-tolerance is working strength of a system in unfavorable conditions. Hadoop HDFS is highly fault-tolerant, in HDFS data is divided into blocks and multiple copies of blocks are created on different machines in the cluster. If any machine in the cluster goes down due to unfavorable conditions, then a client can easily access their data from other machines which contain the same copy of data blocks.
- High Availability – HDFS is highly available file system; data gets replicated among the nodes in the HDFS cluster by creating a replica of the blocks on the other slaves present in the HDFS cluster. Hence, when a client wants to access his data, they can access their data from the slaves which contains its blocks and which is available on the nearest node in the cluster. At the time of failure of a node, a client can easily access their data from other nodes.
- Data Reliability – HDFS is a distributed file system which provides reliable data storage. HDFS can store data in the range of 100s petabytes. It stores data reliably by creating a replica of each and every block present on the nodes and hence, provides fault tolerance facility.
- Replication – Data replication is one of the most important and unique features of HDFS. In HDFS, replication data is done to solve the problem of data loss in unfavorable conditions like crashing of the node, hardware failure and so on.
- Scalability – HDFS stores data on multiple nodes in the cluster, when requirement increases we can scale the cluster. There are two scalability mechanisms available: vertical and horizontal.
- Distributed Storage – In HDFS all the features are achieved via distributed storage and replication. In HDFS data is stored in distributed manner across the nodes in the HDFS cluster.
Read about HDFS Features in detail.
3) What is the difference between NAS and HDFS?
- Hadoop distributed file system (HDFS) is the primary storage system of Hadoop. HDFS designs to store very large files running on a cluster of commodity hardware. While Network-attached storage (NAS) is a file-level computer data storage server. NAS provides data access to a heterogeneous group of clients.
- HDFS distribute data blocks across all the machines in a cluster. Whereas NAS, data stores on a dedicated hardware.
- Hadoop HDFS is designed to work with MapReduce Framework. In MapReduce Framework computation move to the data instead of Data to computation. NAS is not suitable for MapReduce, as it stores data separately from the computations.
- Hadoop HDFS runs on the cluster commodity hardware which is cost effective. While a NAS is a high-end storage device which includes high cost.
4) List the various HDFS daemons in HDFS cluster?
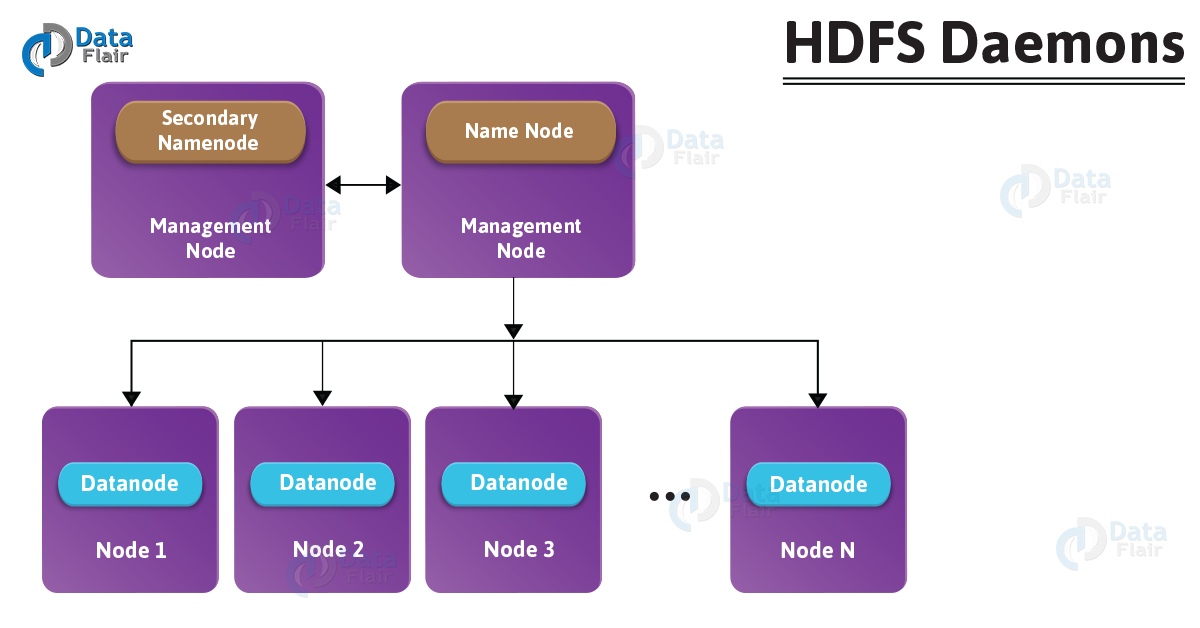
HDFS Daemons
The daemon runs in HDFS cluster are as follows:
- NameNode – It is the master node. It is responsible for storing the metadata of all the files and directories. It also has information about blocks, their location, replicas and other detail.
- Datanode – It is the slave node that contains the actual data. DataNode also performs read and write operation as per request for the clients.
- Secondary NameNode – Secondary NameNode download the FsImage and EditLogs from the NameNode. Then it merges EditLogs with the FsImage periodically. It keeps edits log size within a limit. It stores the modified FsImage into persistent storage. which we can use FsImage in the case of NameNode failure.
5) What is NameNode and DataNode in HDFS?
NameNode – It works as Master in Hadoop cluster. Below listed are the main function performed by NameNode:
- Stores metadata of actual data. E.g. Filename, Path, No. of blocks, Block IDs, Block Location, No. of Replicas, and also Slave related configuration.
- It also manages Filesystem namespace.
- Regulates client access request for actual file data file.
- It also assigns work to Slaves (DataNode).
- Executes file system namespace operation like opening/closing files, renaming files/directories.
- As Name node keep metadata in memory for fast retrieval. So it requires the huge amount of memory for its operation. It should also host on reliable hardware.
DataNode – It works as a Slave in Hadoop cluster. Below listed are the main function performed by DataNode:
- Actually, stores Business data.
- It is the actual worker node, so it handles Read/Write/Data processing.
- Upon instruction from Master, it performs creation/replication/deletion of data blocks.
- As DataNode store all the Business data, so it requires the huge amount of storage for its operation. It should also host on Commodity hardware.
These were some general Hadoop interview questions and answers. Now let us take some Hadoop interview questions and answers specially for freshers.
HDFS Hadoop Interview Question and Answer for Freshers
6) What do you mean by metadata in HDFS?
In Apache Hadoop HDFS, metadata shows the structure of HDFS directories and files. It provides the various information about directories and files like permissions, replication factor. NameNode stores metadata Files which are as follows:
- FsImage – FsImage is an “Image file”. It contains the entire filesystem namespace and stored as a file in the namenode’s local file system. It also contains a serialized form of all the directories and file inodes in the filesystem. Each inode is an internal representation of file or directory’s metadata.
- EditLogs – EditLogs contains all the recent modifications made to the file system of most recent FsImage. When namenode receives a create/update/delete request from the client. Then this request is first recorded to edits file.
If you face any doubt while reading the Hadoop interview questions and answers drop a comment and we will get back to you.
7) What is Block in HDFS?
This one is very important Hadoop interview questions and answers asked in most of the interviews.
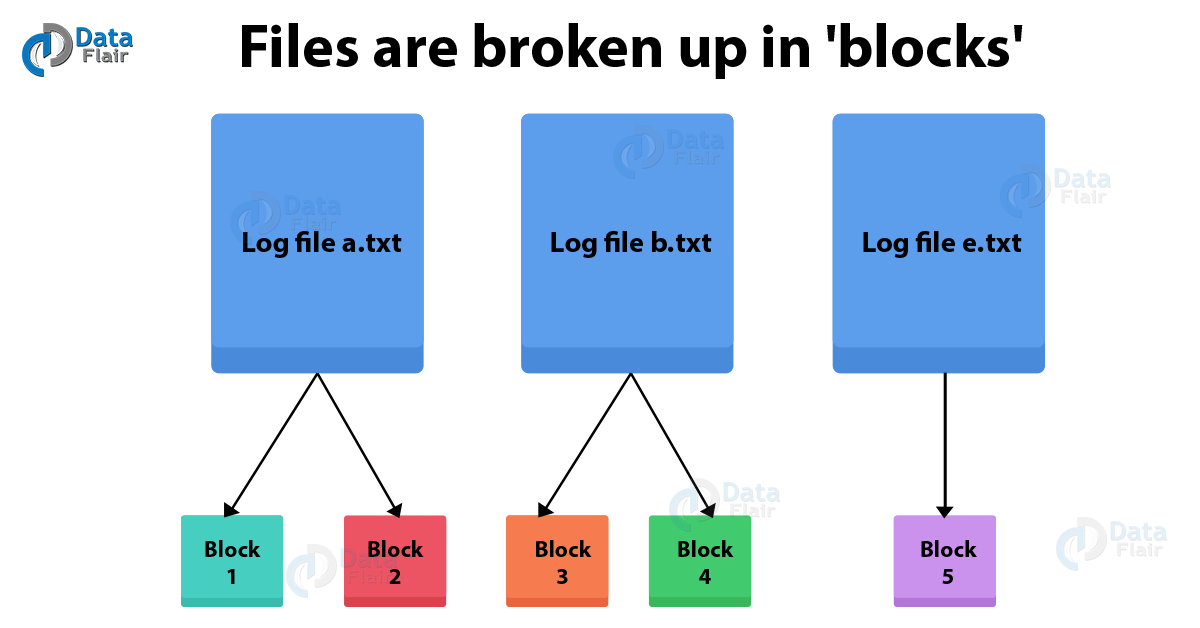
Files are broken up in ‘blocks’
Block is a continuous location on the hard drive where data is stored. In general, FileSystem store data as a collection of blocks. In a similar way, HDFS stores each file as blocks, and distributes it across the Hadoop cluster. HDFS client does not have any control on the block like block location. NameNode decides all such things.
The default size of the HDFS block is 128 MB, which we can configure as per the requirement. All blocks of the file are of the same size except the last block, which can be the same size or smaller.
If the data size is less than the block size, then block size will be equal to the data size. For example, if the file size is 129 MB, then 2 blocks will be created for it. One block will be of default size 128 MB and other will be 1 MB only and not 128 MB as it will waste the space (here block size is equal to data size). Hadoop is intelligent enough not to waste rest of 127 MB. So it is allocating 1Mb block only for 1MB data.
The major advantages of storing data in such block size are that it saves disk seek time.
Read about HDFS Data Blocks in Detail.
8) Why is Data Block size set to 128 MB in Hadoop?
Because of the following reasons Block size is 128 MB:
- To reduce the disk seeks (IO). Larger the block size, lesser the file blocks. Thus, less number of disk seeks. And block can transfer within respectable limits and that to parallelly.
- HDFS have huge datasets, i.e. terabytes and petabytes of data. If we take 4 KB block size for HDFS, just like Linux file system, which has 4 KB block size. Then we would be having too many blocks and therefore too much of metadata. Managing this huge number of blocks and metadata will create huge overhead. Which is something which we don’t want? So, the block size is set to 128 MB.
On the other hand, block size can’t be so large. Because the system will wait for a very long time for the last unit of data processing to finish its work.
9) What is the difference between a MapReduce InputSplit and HDFS block?
Tip for these type of Hadoop interview questions and answers: Start with the definition of Block and InputSplit and answer in a comparison language and then cover its data representation, size, and example and that too in a comparison language.
By definition-
- Block- Block in Hadoop is the continuous location on the hard drive where HDFS store data. In general, FileSystem store data as a collection of blocks. In a similar way, HDFS stores each file as blocks, and distributes it across the Hadoop cluster.
- InputSplit- InputSplit represents the data which individual Mapper will process. Further split divides into records. Each record (which is a key-value pair) will be processed by the map.
Data representation-
- Block-It is the physical representation of data.
- InputSplit- It is the logical representation of data. Thus, during data processing in MapReduce program or other processing techniques use InputSplit. In MapReduce, important thing is that InputSplit does not contain the input data. Hence, it is just a reference to the data.
Size-
- Block- The default size of the HDFS block is 128 MB which is configured as per our requirement. All blocks of the file are of the same size except the last block. The last Block can be of same size or smaller. In Hadoop, the files split into 128 MB blocks and then stored into Hadoop Filesystem.
- InputSplit- Split size is approximately equal to block size, by default.
Example-
Consider an example, where we need to store the file in HDFS. HDFS stores files as blocks. Block is the smallest unit of data that can store or retrieved from the disk. The default size of the block is 128MB. HDFS break files into blocks and stores these blocks on different nodes in the cluster. We have a file of 130 MB, so HDFS will break this file into 2 blocks.
Now, if one wants to perform MapReduce operation on the blocks, it will not process, as the 2nd block is incomplete. InputSplit solves this problem. InputSplit will form a logical grouping of blocks as a single block. As the InputSplit include a location for the next block. It also includes the byte offset of the data needed to complete the block.
From this, we can conclude that InputSplit is only a logical chunk of data. i.e. it has just the information about blocks address or location. Thus, during MapReduce execution, Hadoop scans through the blocks and create InputSplits.
Read InputSplit vs HDFS Blocks in Hadoop in detail.
10) How can one copy a file into HDFS with a different block size to that of existing block size configuration?
By using bellow commands one can copy a file into HDFS with a different block size:
–Ddfs.blocksize=block_size, where block_size is in bytes.
So, consider an example to explain it in detail:
Suppose, you want to copy a file called test.txt of size, say of 128 MB, into the hdfs. And for this file, you want the block size to be 32MB (33554432 Bytes) in place of the default (128 MB). So, can issue the following command:
Hadoop fs –Ddfs.blocksize=33554432-copyFromlocal/home/dataflair/test.txt/sample_hdfs.
Now, you can check the HDFS block size associated with this file by:
hadoop fs –stat %o/sample_hdfs/test.txt
You can also check it by using the NameNode web UI for seeing the HDFS directory.
These are very common type of Hadoop interview questions and answers faced during the interview of a fresher.
Frequently Asked Question in Hadoop Interview
11) Which one is the master node in HDFS? Can it be commodity hardware?
Name node is the master node in HDFS. The NameNode stores metadata and works as High Availability machine in HDFS. It requires high memory (RAM) space, so NameNode needs to be a high-end machine with good memory space. It cannot be a commodity as the entire HDFS works on it.
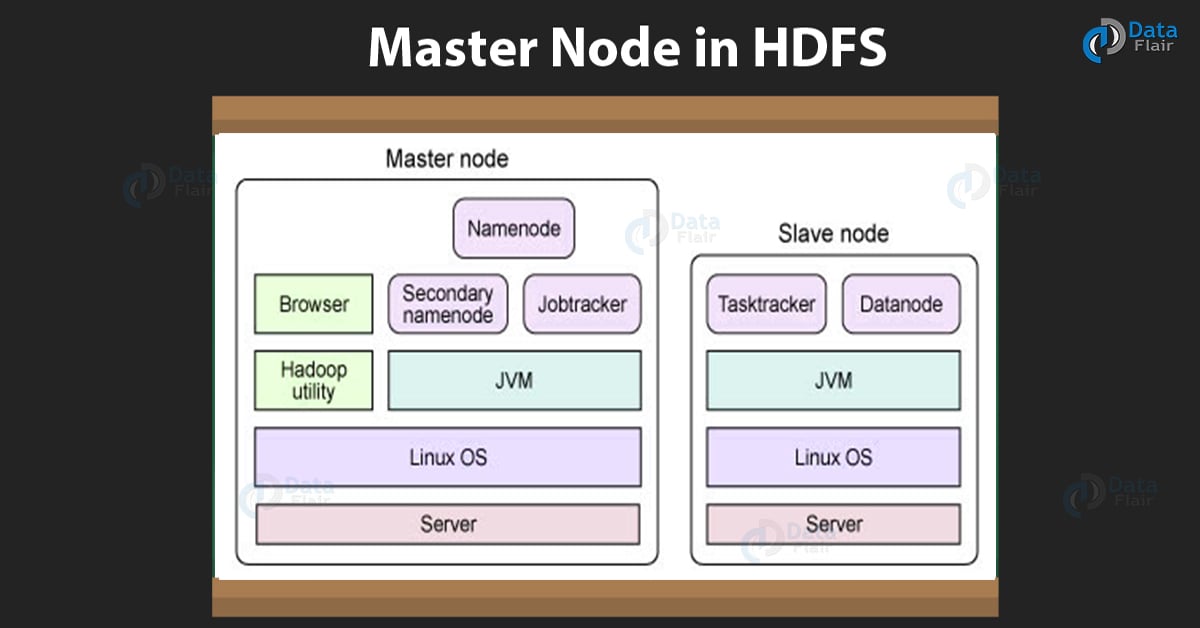
Masternode in HDFS
12) In HDFS, how Name node determines which data node to write on?
Answer these type of Hadoop interview questions answers very shortly and to the point.
Namenode contains Metadata i.e. number of blocks, replicas, their location, and other details. This meta-data is available in memory in the master for faster retrieval of data. NameNode maintains and manages the Datanodes, and assigns tasks to them.
13) What is a Heartbeat in Hadoop?
Heartbeat is the signals that NameNode receives from the DataNodes to show that it is functioning (alive).

Heartbeat in Hadoop
NameNode and DataNode do communicate using Heartbeat. If after a certain time of heartbeat DataNode does not send any response to NameNode, then that Node is dead. So, NameNode in HDFS will create new replicas of those blocks on other DataNodes.
Heartbeats carry information about total storage capacity. It also, carry the fraction of storage in use, and the number of data transfers currently in progress.
The default heartbeat interval is 3 seconds. One can change it by using dfs.heartbeat.interval in hdfs-site.xml.
14) Can multiple clients write into a Hadoop HDFS file concurrently?
Multiple clients cannot write into a Hadoop HDFS file at the same time. Apache Hadoop follows single writer multiple reader models. When HDFS client opens a file for writing, then NameNode grant a lease. Now suppose, some other client wants to write into that file. It asks NameNode for a write operation in Hadoop. NameNode first checks whether it has granted the lease for writing into that file to someone else or not. If someone else acquires the lease, then it will reject the write request of the other client.
Read HDFS Data Write Operation in detail.
15) How data or file is read in Hadoop HDFS?
To read from HDFS, the first client communicates to namenode for metadata. The Namenode responds with details of No. of blocks, Block IDs, Block Location, No. of Replicas. Then, the client communicates with Datanode where the blocks are present. Clients start reading data parallel from the Datanode. It read on the basis of information received from the namenodes.
Once an application or HDFS client receives all the blocks of the file, it will combine these blocks to form a file. To improve read performance, the location of each block ordered by their distance from the client. HDFS selects the replica which is closest to the client. This reduces the read latency and bandwidth consumption. It first read the block in the same node. Then another node in the same rack, and then finally another Datanode in another rack.
Read HDFS Data Read Operation in detail.
16) Does HDFS allow a client to read a file which is already opened for writing?
Yes, the client can read the file which is already opened for writing. But, the problem in reading a file which is currently open for writing, lies in the consistency of data. HDFS does not provide the surety that the data which it has written into the file will be visible to a new reader. For this, one can call the hflush operation. It will push all the data in the buffer into write pipeline. Then the hflush operation will wait for acknowledgments from the datanodes. Hence, by doing this, the data that client has written into the file before the hflush operation visible to the reader for sure.
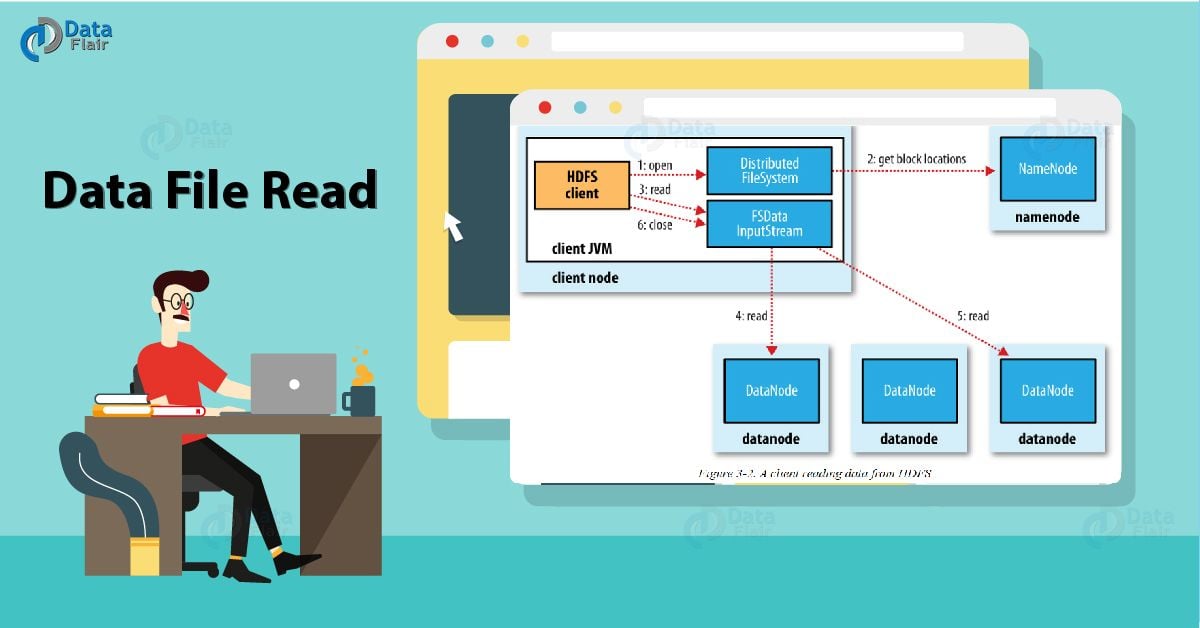
Dara file read
If you encounter any doubt or query in the Hadoop interview questions, feel free to ask us in the comment section below and our support team will get back to you.
17) Why is Reading done in parallel and writing is not in HDFS?
Client read data parallelly because by doing so the client can access the data fast. Reading in parallel makes the system fault tolerant. But the client does not perform the write operation in Parallel. Because writing in parallel might result in data inconsistency.
Suppose, you have a file and two nodes are trying to write data into a file in parallel. Then the first node does not know what the second node has written and vice-versa. So, we can not identify which data to store and access.
Client in Hadoop writes data in pipeline anatomy. There are various benefits of a pipeline write:
- More efficient bandwidth consumption for the client – The client only has to transfer one replica to the first datanode in the pipeline write. So, each node only gets and send one replica over the network (except the last datanode only receives data). This results in balanced bandwidth consumption. As compared to the client writing three replicas into three different datanodes.
- Smaller sent/ack window to maintain – The client maintains a much smaller sliding window. Sliding window record which blocks in the replica is sending to the DataNodes. It also records which blocks are waiting for acks to confirm the write has been done. In a pipeline write, the client appears to write data to only one datanode.
18) What is the problem with small files in Apache Hadoop?
Hadoop is not suitable for small data. Hadoop HDFS lacks the ability to support the random reading of small files. Small file in HDFS is smaller than the HDFS block size (default 128 MB). If we are storing these huge numbers of small files, HDFS can’t handle these lots of files. HDFS works with the small number of large files for storing large datasets. It is not suitable for a large number of small files. A large number of many small files overload NameNode since it stores the namespace of HDFS.
Solution –
- HAR (Hadoop Archive) Files – HAR files deal with small file issue. HAR has introduced a layer on top of HDFS, which provides interface for file accessing. Using Hadoop archive command we can create HAR files. These file runs a MapReduce job to pack the archived files into a smaller number of HDFS files. Reading through files in as HAR is not more efficient than reading through files in HDFS.
- Sequence Files – Sequence Files also deal with small file problem. In this, we use the filename as key and the file contents as the value. Suppose we have 10,000 files, each of 100 KB, we can write a program to put them into a single sequence file. Then one can process them in a streaming fashion.
19) What is throughput in HDFS?
The amount of work done in a unit time is known as Throughput. Below are the reasons due to HDFS provides good throughput:
- Hadoop works on Data Locality principle. This principle state that moves computation to data instead of data to computation. This reduces network congestion and therefore, enhances the overall system throughput.
- The HDFS is Write Once and Read Many Model. It simplifies the data coherency issues as the data written once, one can not modify it. Thus, provides high throughput data access.
20) Comparison between Secondary NameNode and Checkpoint Node in Hadoop?
Secondary NameNode download the FsImage and EditLogs from the NameNode. Then it merges EditLogs with the FsImage periodically. Secondary NameNode stores the modified FsImage into persistent storage. So, we can use FsImage in the case of NameNode failure. But it does not upload the merged FsImage with EditLogs to active namenode. While Checkpoint node is a node which periodically creates checkpoints of the namespace.
Checkpoint Node in Hadoop first downloads FsImage and edits from the active NameNode. Then it merges them (FsImage and edits) locally, and at last, it uploads the new image back to the active namenode.
The above 7-20 Hadoop interview questions and answers were for freshers, However, experienced can also go through these Hadoop interview questions and answers for revising the basics.
HDFS Hadoop Interview Questions and Answers for Experienced
21) What is a Backup node in Hadoop?
Backup node provides the same checkpointing functionality as the Checkpoint node (Checkpoint node is a node which periodically creates checkpoints of the namespace. Checkpoint Node downloads FsImage and edits from the active NameNode, merges them locally, and uploads the new image back to the active NameNode). In Hadoop, Backup node keeps an in-memory, up-to-date copy of the file system namespace, which is always synchronized with the active NameNode state.
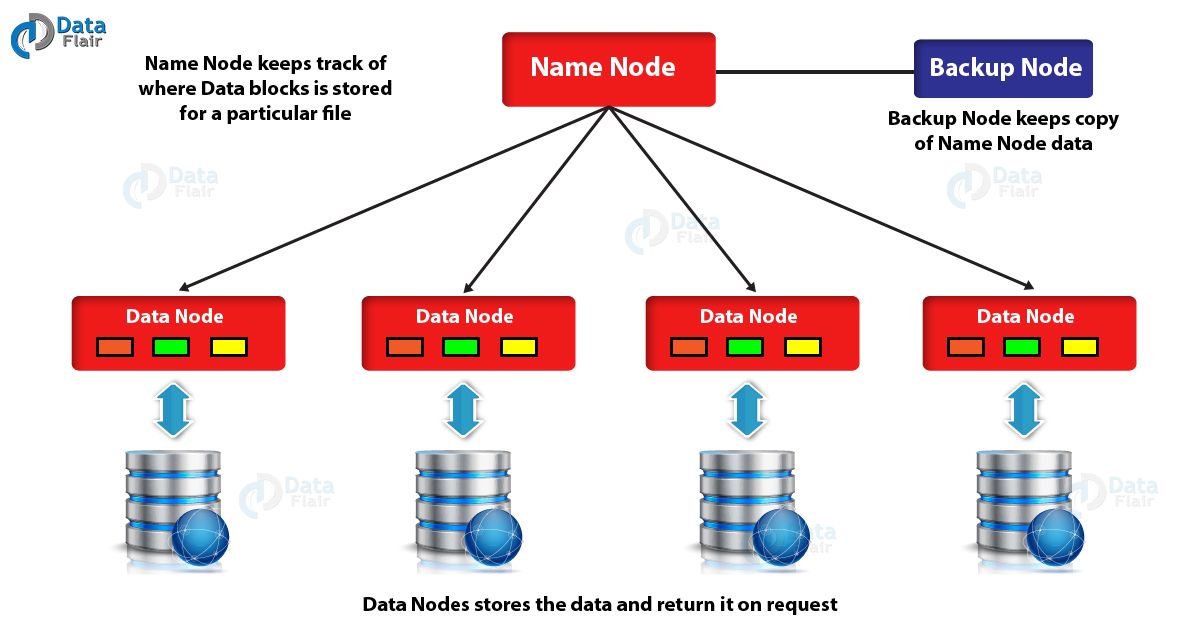
Backup node in hadoop
The Backup node does not need to download FsImage and edits files from the active NameNode in order to create a checkpoint, as would be required with a Checkpoint node or Secondary Namenode since it already has an up-to-date state of the namespace state in memory. The Backup node checkpoint process is more efficient as it only needs to save the namespace into the local FsImage file and reset edits. One Backup node is supported by the NameNode at a time. No checkpoint nodes may be registered if a Backup node is in use.
22) How does HDFS ensure Data Integrity of data blocks stored in HDFS?
Data Integrity ensures the correctness of the data. But, it is possible that the data will get corrupted during I/O operation on the disk. Corruption can occur due to various reasons network faults, or buggy software. Hadoop HDFS client software implements checksum checking on the contents of HDFS files.

HDFS Federation Architecture
In Hadoop, when a client creates an HDFS file, it computes a checksum of each block of the file. Then stores these checksums in a separate hidden file in the same HDFS namespace. When a client retrieves file contents it first checks. Then it verifies that the data it received from each Datanode matches the checksum. Checksum stored in the associated checksum file. And if not, then the client can opt to retrieve that block from another DataNode that has a replica of that block.
23) What do you mean by the NameNode High Availability in hadoop?
In Hadoop 1.x, NameNode is a single point of Failure (SPOF). If namenode fails, all clients would be unable to read, write file or list files. In such event, the whole Hadoop system would be out of service until new namenode is up.
Hadoop 2.0 overcomes SPOF. Hadoop 2.x provide support for multiple NameNode. High availability feature gives an extra NameNode (active standby NameNode) to Hadoop architecture. This extra NameNode configured for automatic failover. If active NameNode fails, then Standby Namenode takes all its responsibility. And cluster work continuously.
The initial implementation of namenode high availability provided for single active/standby namenode. However, some deployment requires high degree fault-tolerance. Hadoop 3.x enable this feature by allowing the user to run multiple standby namenode. The cluster tolerates the failure of 2 nodes rather than 1 by configuring 3 namenode & 5 journal nodes.
Read about HDFS NameNode High Availability.
24) What is Fault Tolerance in Hadoop HDFS?
Fault-tolerance in HDFS is working strength of a system in unfavorable conditions. Unfavorable conditions are the crashing of the node, hardware failure and so on. HDFS control faults by the process of replica creation. When client stores a file in HDFS, Hadoop framework divide the file into blocks. Then client distributes data blocks across different machines present in HDFS cluster. And, then create the replica of each block is on other machines present in the cluster.
HDFS, by default, creates 3 copies of a block on other machines present in the cluster. If any machine in the cluster goes down or fails due to unfavorable conditions. Then also, the user can easily access that data from other machines in which replica of the block is present.
Read about HDFS Fault Tolerance in detail.
25) Describe HDFS Federation.
In Hadoop 1.0, HDFS architecture for entire cluster allows only single namespace.
Limitations-
- Namespace layer and storage layer are tightly coupled. This makes alternate implementation of namenode difficult. It also restricts other services to use block storage directly.
- A namespace is not scalable like datanode. Scaling in HDFS cluster is horizontally by adding datanodes. But we can’t add more namespace to an existing cluster.
- There is no separation of the namespace. So, there is no isolation among tenant organization that is using the cluster.
In Hadoop 2.0, HDFS Federation overcomes this limitation. It supports too many NameNode/ Namespaces to scale the namespace horizontally. In HDFS federation isolate different categories of application and users to different namespaces. This improves Read/ write operation throughput adding more namenodes.
Read about HDFS Federation in detail.
26) What is the default replication factor in Hadoop and how will you change it?
The default replication factor is 3. One can change replication factor in following three ways:
- By adding this property to hdfs-site.xml:
[php]<property>
<name>dfs.replication</name>
<value>5</value>
<description>Block Replication</description>
</property>[/php] - One can also change the replication factor on a per-file basis using the command:
[php]hadoop fs –setrep –w 3 / file_location[/php] - One can also change replication factor for all the files in a directory by using:
[php]hadoop fs –setrep –w 3 –R / directoey_location[/php]
27) Why Hadoop performs replication, although it results in data redundancy?
In HDFS, Replication provides the fault tolerance. Replication is one of the unique features of HDFS. Data Replication solves the issue of data loss in unfavorable conditions. Unfavorable conditions are the hardware failure, crashing of the node and so on.
HDFS by default creates 3 replicas of each block across the cluster in Hadoop. And we can change it as per the need. So if any node goes down, we can recover data on that node from the other node. In HDFS, Replication will lead to the consumption of a lot of space. But the user can always add more nodes to the cluster if required. It is very rare to have free space issues in practical cluster. As the very first reason to deploy HDFS was to store huge data sets. Also, one can change the replication factor to save HDFS space. Or one can also use different codec provided by the Hadoop to compress the data.
28) What is Rack Awareness in Apache Hadoop?
In Hadoop, Rack Awareness improves the network traffic while reading/writing file. In Rack Awareness NameNode chooses the DataNode which is closer to the same rack or nearby rack. NameNode achieves Rack information by maintaining the rack ids of each DataNode. Thus, this concept chooses Datanodes based on the Rack information.
HDFS NameNode makes sure that all the replicas are not stored on the single rack or same rack. It follows Rack Awareness Algorithm to reduce latency as well as fault tolerance.
Default replication factor is 3. Therefore according to Rack Awareness Algorithm:
- The first replica of the block will store on a local rack.
- The next replica will store on another datanode within the same rack.
- And the third replica stored on the different rack.
In Hadoop, we need Rack Awareness for below reason: It improves-
- Data high availability and reliability.
- The performance of the cluster.
- Network bandwidth.
Read about HDFS Rack Awareness in detail.
29) Explain the Single point of Failure in Hadoop?
In Hadoop 1.0, NameNode is a single point of Failure (SPOF). If namenode fails, all clients would unable to read/write files. In such event, whole Hadoop system would be out of service until new namenode is up.
Hadoop 2.0 overcomes this SPOF by providing support for multiple NameNode. High availability feature provides an extra NameNode to hadoop architecture. This feature provides automatic failover. If active NameNode fails, then Standby-Namenode takes all the responsibility of active node. And cluster continues to work.
The initial implementation of Namenode high availability provided for single active/standby namenode. However, some deployment requires high degree fault-tolerance. So new version 3.0 enable this feature by allowing the user to run multiple standby namenode. The cluster tolerates the failure of 2 nodes rather than 1 by configuring 3 namenode & 5 journalnodes.
30) Explain Erasure Coding in Apache Hadoop?
For several purposes, HDFS, by default, replicates each block three times. Replication also provides the very simple form of redundancy to protect against the failure of datanode. But replication is very expensive. 3 x replication scheme results in 200% overhead in storage space and other resources.
Hadoop 2.x introduced a new feature called “Erasure Coding” to use in the place of Replication. It also provides the same level of fault tolerance with less space store and 50% storage overhead.
Erasure Coding uses Redundant Array of Inexpensive Disk (RAID). RAID implements Erasure Coding through striping. In which it divides logical sequential data (such as a file) into the smaller unit (such as bit, byte or block). After that, it stores data on different disk.
Encoding – In this, RAID calculates and sort Parity cells for each strip of data cells. Then, recover error through the parity. Erasure coding extends a message with redundant data for fault tolerance. Its codec operates on uniformly sized data cells. In Erasure Coding, codec takes a number of data cells as input and produces parity cells as the output.
There are two algorithms available for Erasure Coding:
- XOR Algorithm
- Reed-Solomon Algorithm
Read about Erasure Coding in detail
31) What is Balancer in Hadoop?
Data may not always distribute uniformly across the datanodes in HDFS due to following reasons:
- A lot of deletes and writes
- Disk replacement
Data Blocks allocation strategy tries hard to spread new blocks uniformly among all the datanodes. In a large cluster, each node has different capacity. While quite often you need to delete some old nodes, also add new nodes for more capacity.
The addition of new datanode becomes a bottleneck due to below reason:
- When Hadoop framework allocates all the new blocks and read from new datanode. This will overload the new datanode.
HDFS provides a tool called Balancer that analyzes block placement and balances across the datanodes.
These are very common type of Hadoop interview questions and answers faced during the interview of an experienced professional.
32) What is Disk Balancer in Apache Hadoop?
Disk Balancer is a command line tool, which distributes data evenly on all disks of a datanode. This tool operates against a given datanode and moves blocks from one disk to another.
Disk balancer works by creating and executing a plan (set of statements) on the datanode. Thus, the plan describes how much data should move between two disks. A plan composes multiple steps. Move step has source disk, destination disk and the number of bytes to move. And the plan will execute against an operational datanode.
By default, disk balancer is not enabled. Hence, to enable diskbalnecr dfs.disk.balancer.enabled must be set true in hdfs-site.xml.
When we write new block in hdfs, then, datanode uses volume choosing the policy to choose the disk for the block. Each directory is the volume in hdfs terminology. Thus, two such policies are: Round-robin and Available space
- Round-robin distributes the new blocks evenly across the available disks.
- Available space writes data to the disk that has maximum free space (by percentage).
Read about HDFS Disk Balancer in detail.
33) What is active and passive NameNode in Hadoop?
In Hadoop 1.0, NameNode is a single point of Failure (SPOF). If namenode fails, then all clients would be unable to read, write file or list files. In such event, whole Hadoop system would be out of service until new namenode is up.
Hadoop 2.0 overcomes this SPOF. Hadoop 2.0 provides support for multiple NameNode. High availability feature provides an extra NameNode to Hadoop architecture for automatic failover.
- Active NameNode – It is the NameNode which works and runs in the cluster. It is also responsible for all client operations in the cluster.
- Passive NameNode – It is a standby namenode, which has similar data as active NameNode. It simply acts as a slave, maintains enough state to provide a fast failover, if necessary.
If Active NameNode fails, then Passive NameNode takes all the responsibility of active node. The cluster works continuously.
34) How is indexing done in Hadoop HDFS?
Apache Hadoop has a unique way of indexing. Once Hadoop framework store the data as per the Data Bock size. HDFS will keep on storing the last part of the data which will say where the next part of the data will be. In fact, this is the base of HDFS.
35) What is a Block Scanner in HDFS?
Block scanner verify whether the data blocks stored on each DataNodes are correct or not. When Block scanner detects corrupted data block, then following steps occur:
- First of all, DataNode report NameNode about the corrupted block.
- After that, NameNode will start the process of creating a new replica. It creates new replica using the correct replica of the corrupted block present in other DataNodes.
- When the replication count of the correct replicas matches the replication factor 3, then delete corrupted block
36) How to perform the inter-cluster data copying work in HDFS?
HDFS use distributed copy command to perform the inter-cluster data copying. That is as below:
[php] hadoop distcp hdfs://<source NameNode> hdfs://<target NameNode> [/php]
DistCp (distributed copy) is a tool also used for large inter/intra-cluster copying. It uses
MapReduce to affect its distribution, error handling and recovery and reporting. This distributed copy tool enlarges a list of files and directories into the input to map tasks.
37) What are the main properties of hdfs-site.xml file?
hdfs-site.xml – It specifies configuration setting for HDFS daemons in Hadoop. It also provides default block replication and permission checking on HDFS.
The three main hdfs-site.xml properties are:
- dfs.name.dir gives you the location where NameNode stores the metadata (FsImage and edit logs). It also specifies where DFS should locate, on the disk or onto the remote directory.
- dfs.data.dir gives the location of DataNodes where it stores the data.
- fs.checkpoint.dir is the directory on the file system. Hence, on this directory secondary NameNode stores the temporary images of edit logs.
38) How can one check whether NameNode is working or not?
One can check the status of the HDFS NameNode in several ways. Most usually, one uses the jps command to check the status of all daemons running in the HDFS.
39) How would you restart NameNode?
NameNode is also known as Master node. It stores meta-data i.e. number of blocks, replicas, and other details. NameNode maintains and manages the slave nodes, and assigns tasks to them.
By following two methods, you can restart NameNode:
- First stop the NameNode individually using ./sbin/hadoop-daemons.sh stop namenode command. Then, start the NameNode using ./sbin/hadoop-daemons.sh start namenode command.
- Use ./sbin/stop-all.sh and then use ./sbin/start-all.sh command which will stop all the demons first. Then start all the daemons.
The above Hadoop interview questions and answers were for experienced but freshers can also refer these Hadoop interview questions and answers for in depth knowledge. Now let’s move forward with some advanced Hadoop interview questions and answers.
Advanced Questions for Hadoop Interview
40) How NameNode tackle Datanode failures in Hadoop?
HDFS has a master-slave architecture in which master is namenode and slave are datanode. HDFS cluster has single namenode that manages file system namespace (metadata) and multiple datanodes that are responsible for storing actual data in HDFs and performing the read-write operation as per request for the clients.
NameNode receives Heartbeat and block report from Datanode. Heartbeat receipt implies that the datanode is alive and functioning properly and block report contains a list of all blocks on a datanode. When NameNode observes that DataNode has not sent heartbeat message after a certain amount of time, the datanode is marked as dead. The namenode replicates the blocks of the dead node to another datanode using the replica created earlier. Hence, NameNode can easily handle Datanode failure.
41) Is Namenode machine same as DataNode machine as in terms of hardware in Hadoop?
NameNode is highly available server, unlike DataNode. NameNode manages the File System Namespace. It also maintains the metadata information. Metadata information is the number of blocks, their location, replicas and other details. It also executes file system execution such as naming, closing, opening files/directories.
Because of the above reasons, NameNode requires higher RAM for storing the metadata for millions of files. Whereas, DataNode is responsible for storing actual data in HDFS. It performs read and write operation as per request of the clients. Therefore, Datanode needs to have a higher disk capacity for storing huge data sets.
42) If DataNode increases, then do we need to upgrade NameNode in Hadoop?
Namenode stores meta-data i.e. number of blocks, their location, replicas. In Hadoop, meta-data is present in memory in the master for faster retrieval of data. NameNode manages and maintains the slave nodes, and assigns tasks to them. It regulates client’s access to files.
It also executes file system execution such as naming, closing, opening files/directories. During Hadoop installation, framework determines NameNode based on the size of the cluster. Mostly we don’t need to upgrade the NameNode because it does not store the actual data. But it stores the metadata, so such requirement rarely arise.
43) Explain what happens if, during the PUT operation, HDFS block is assigned a replication factor 1 instead of the default value 3?
Replication factor can be set for the entire cluster to adjust the number of replicated block. It ensures high data availability.
The cluster will have n-1 duplicated blocks, for every block that are present in HDFS. So, if the replication factor during PUT operation is set to 1 in place of the default value 3. Then it will have a single copy of data. If one set replication factor 1. And if DataNode crashes under any circumstances, then an only single copy of the data would lose.
44) What are file permissions in HDFS? how does HDFS check permissions for files/directory?
Hadoop distributed file system (HDFS) implements a permissions model for files/directories.
For each files/directory, one can manage permissions for a set of 3 distinct user classes: owner, group, others
There are also 3 different permissions for each user class: Read (r), write (w), execute(x)
- For files, the w permission is to write to the file and the r permission is to read the file.
- For directories, w permission is to create or delet the directory. The r permission is to list the contents of the directory.
- The X permission is to access a child of the directory.
HDFS check permissions for files or directory:
- We can also check the owner’s permissions, if the user name matches the owner of directory.
- If the group matches the directory’s group, then Hadoop tests the user’s group permissions.
- Hadoop tests the “other” permission, when owner and the group names doesn’t match.
- If none of the permissions checks succeed, then client’s request is denied.
45) How one can format Hadoop HDFS?
One can format HDFS by using bin/hadoop namenode –format command.
$bin/hadoop namenode –format$ command formats the HDFS via NameNode.
Formatting implies initializing the directory specified by the dfs.name.dir variable. When you run this command on existing files system, then, you will lose all your data stored on your NameNode.
Hadoop NameNode directory contains the FsImage and edit files. This hold the basic information’s about Hadoop file system. So, this basic information includes like which user created files etc.
Hence, when we format the NameNode, then it will delete above information from directory. This information is present in the hdfs-site.xml as dfs.namenode.name.dir. So, formatting a NameNode will not format the DataNode.
NOTE: Never format, up and running Hadoop Filesystem. You will lose data stored in the HDFS.
46) What is the process to change the files at arbitrary locations in HDFS?
HDFS doesn’t support modifications at arbitrary offsets in the file or multiple writers. But a single writer writes files in append-only format. Writes to a file in HDFS are always made at the end of the file.
47) Differentiate HDFS & HBase.
Data write process
- HDFS- Append method
- HBase- Bulk incremental, random write
Data read process
- HDFS- Table scan
- HBase- Table scan/random read/small range scan
Hive SQL querying
- HDFS- Excellent
- HBase- Average
These are some advanced Hadoop interview questions and answers for HDFS that will help you in answer many more interview questions in the best manner
48) What is meant by streaming access?
HDFS works on the principle of “write once, read many”. Its focus is on fast and accurate data retrieval. Steaming access means reading the complete data instead of retrieving a single record from the database.
49) How to transfer data from Hive to HDFS?
One can transfer data from Hive by writing the query:
hive> insert overwrite directory ‘/’ select * from emp;
Hence, the output you receive will be stored in part files in the specified HDFS path.
50) How to add/delete a Node to the existing cluster?
To add a Node to the existing cluster follow:
Add the host name/Ip address in dfs.hosts/slaves file. Then, refresh the cluster with
$hadoop dfsamin -refreshNodes
To delete a Node to the existing cluster follow:
Add the hostname/Ip address to dfs.hosts.exclude/remove the entry from slaves file. Then, refresh the cluster with $hadoop dfsamin -refreshNodes
$hadoop dfsamin -refreshNodes
51) How to format the HDFS? How frequently it will be done?
These type of Hadoop Interview Questions and Answers are also taken very short and to the point. Giving very lengthy answer here is unnecessary and may lead to negative points.
$hadoop namnode -format.
Note: Format the HDFS only once that to during initial cluster setup.
52) What is the importance of dfs.namenode.name.dir in HDFS?
dfs.namenode.name.dir contains the fsimage file for namenode.
We should configure it to write to atleast two filesystems on physical hosts/namenode/secondary namenode. Because if we lose FsImage file we will lose entire HDFS file system. Also there is no other recovery mechanism if there is no FsImage file available.
Number 40-52 were the advanced Hadoop interview question and answer to get indepth knowledge in handling difficult Hadoop interview questions and answers.
This was all about the Hadoop Interview Questions and Answers
These questions are frequently asked Hadoop interview questions and answers. You can read here some more Hadoop HDFS interview questions and answers.
After going through these top Hadoop Interview questions and answers you will be able to confidently face a interview and will be able to answer Hadoop Interview questions and answers asked in your interview in the best manner. These Hadoop Interview Questions are suggested by the experts at DataFlair
Key –
Q.1 – Q.5 Basic Hadoop Interview Questions
Q.6 – Q.10 HDFS Hadoop interview questions and answers for freshers
Q. 11- Q. 20 Frequently asked Questions in Hadoop Interview
Q.21 – Q39 were the HDFS Hadoop interview questions and answer for experienced
Q.40 – Q.52 were the advanced HDFS Hadoop interview questions and answers
These Hadoop interview questions and answers are categorized so that you can pay more attention to questions specified for you, however, it is recommended that you go through all the Hadoop interview questions and answers for complete understanding.
If you have any more doubt or query on Hadoop Interview Questions and Answers, Drop a comment and our support team will be happy to help you. Now let’s jump to our second part of Hadoop Interview Questions i.e. MapReduce Interview Questions and Answers.
Hadoop Interview Questions and Answers for MapReduce
It is difficult to pass the Hadoop interview as it is fast and growing technology. To get you through this tough path the MapReduce Hadoop interview questions and answers will serve as the backbone. This section contains the commonly asked MapReduce Hadoop interview questions and answers.
In this section on MapReduce Hadoop interview questions and answers, we have covered 50+ Hadoop interview questions and answers for MapReduce in detail. We have covered MapReduce Hadoop interview questions and answers for freshers, MapReduce Hadoop interview questions and answers for experienced as well as some advanced Mapreduce Hadoop interview questions and answers.
These MapReduce Hadoop Interview Questions are framed by keeping in mind the need of an era, and the trending pattern of the interview that is being followed by the companies. The interview questions of Hadoop MapReduce are dedicatedly framed by the company experts to help you to reach your goal.

Top 50 MapReduce Hadoop Interview Questions and Answers for Hadoop Jobs.
Basic MapReduce Hadoop Interview Questions and Answers
53) What is MapReduce in Hadoop?
Hadoop MapReduce is the data processing layer. It is the framework for writing applications that process the vast amount of data stored in the HDFS.
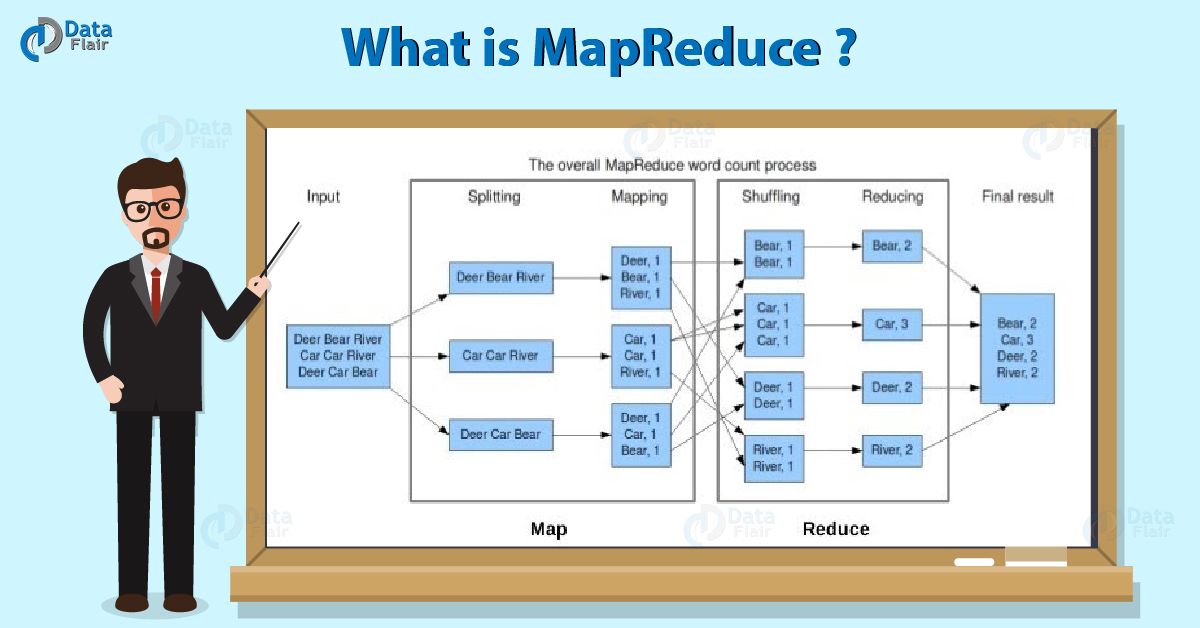
What is MapReduce
It processes a huge amount of data in parallel by dividing the job into a set of independent tasks (sub-job). In Hadoop, MapReduce works by breaking the processing into phases: Map and Reduce.
- Map – It is the first phase of processing. In which we specify all the complex logic/business rules/costly code. The map takes a set of data and converts it into another set of data. It also breaks individual elements into tuples (key-value pairs).
- Reduce – It is the second phase of processing. In which we specify light-weight processing like aggregation/summation. The output from the map is the input to Reducer. Then, Reducer combines tuples (key-value) based on the key. And then, modifies the value of the key accordingly.
Read about Hadoop MapReduce in Detail.
54) What is the need of MapReduce in Hadoop?
In Hadoop, when we have stored the data in HDFS, how to process this data is the first question that arises? Transferring all this data to a central node for processing is not going to work. And we will have to wait forever for the data to transfer over the network. Google faced this same problem with its Distributed Goggle File System (GFS). It solved this problem using a MapReduce data processing model.
Challenges before MapReduce
- Time-consuming – By using single machine we cannot analyze the data (terabytes) as it will take a lot of time.
- Costly – All the data (terabytes) in one server or as database cluster which is very expensive. And also hard to manage.
MapReduce overcome these challenges
- Time-efficient – If we want to analyze the data. We can write the analysis code in Map function. And the integration code in Reduce function and execute it. Thus, this MapReduce code will go to every machine which has a part of our data and executes on that specific part. Hence instead of moving terabytes of data, we just move kilobytes of code. So this type of movement is time-efficient.
- Cost-efficient – It distributes the data over multiple low config machines.
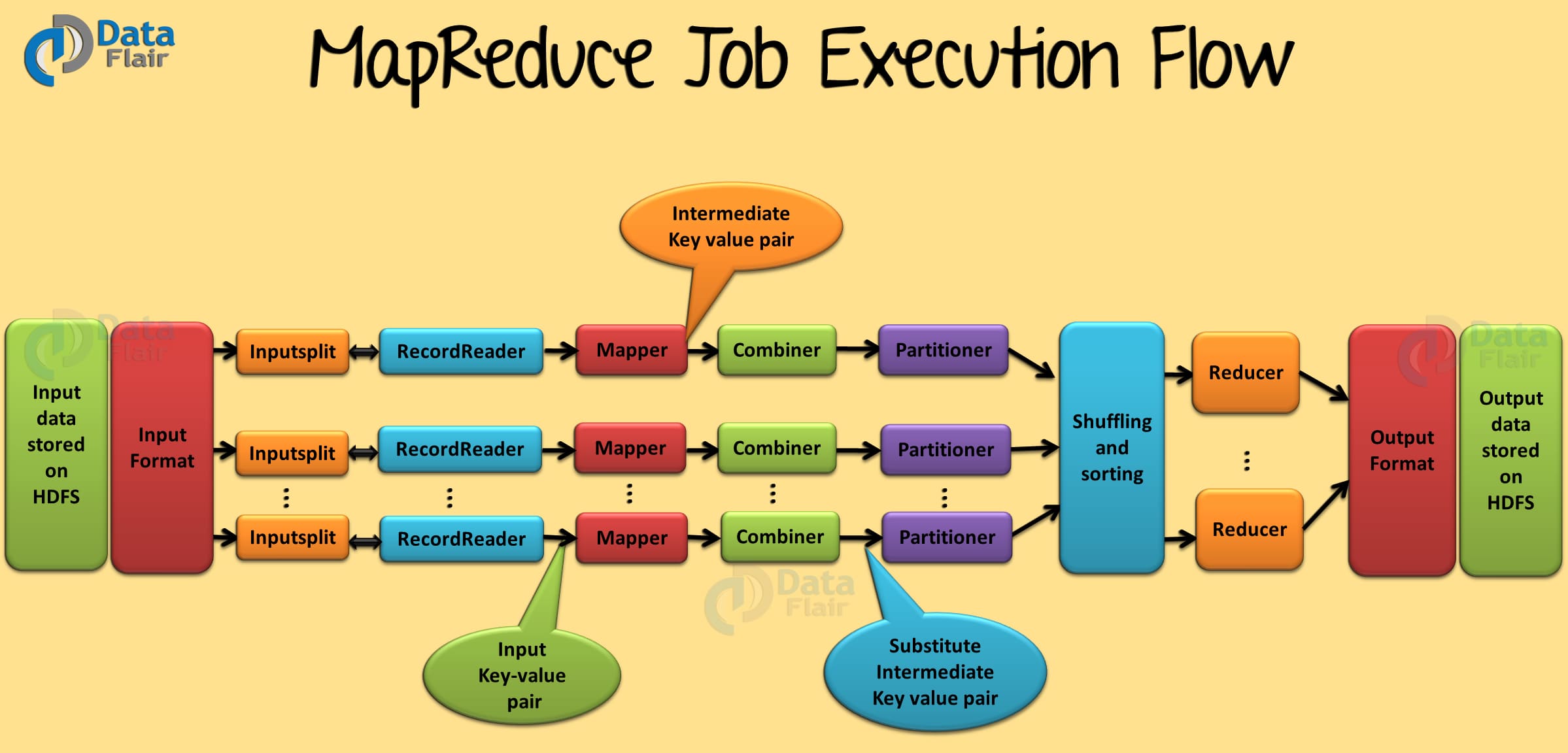
Hadoop MapReduce Job Execution Flow Diagram
55) What is Mapper in Hadoop?
Mapper task processes each input record (from RecordReader) and generates a key-value pair. This key-value pairs generated by mapper is completely different from the input pair. The Mapper store intermediate-output on the local disk. Thus, it does not store its output on HDFS. It is temporary data and writing on HDFS will create unnecessary multiple copies. Mapper only understands key-value pairs of data. So before passing data to the mapper, it, first converts the data into key-value pairs.
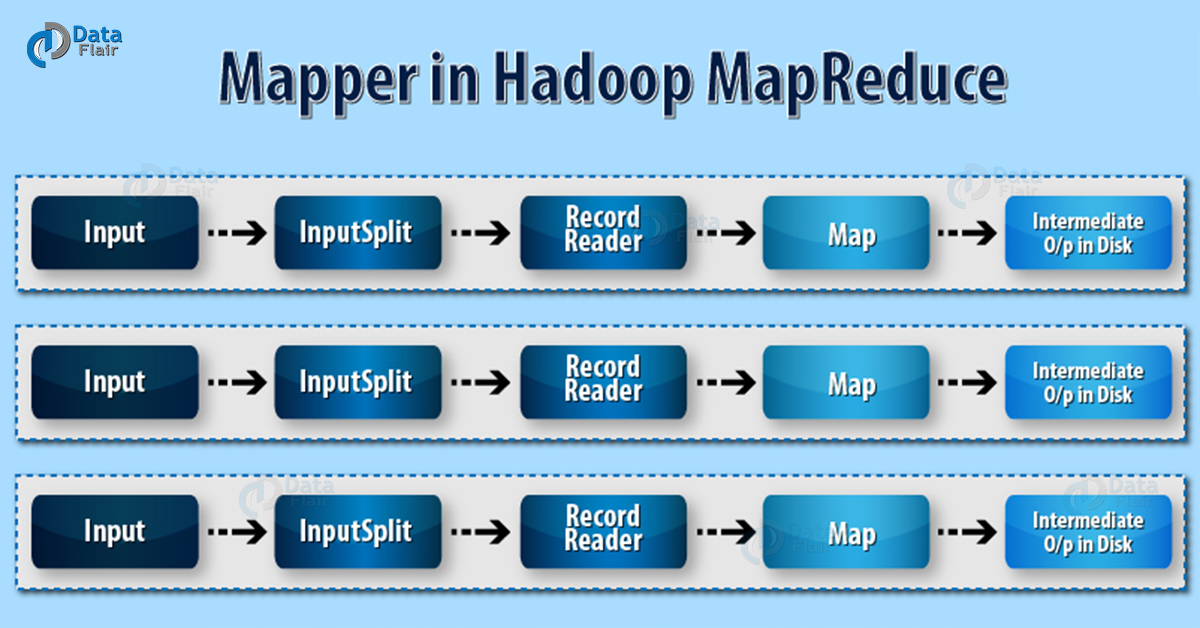
MapReduce Mapper
Mapper only understands key-value pairs of data. So before passing data to the mapper, it, first converts the data into key-value pairs. InputSplit and RecordReader convert data into key-value pairs. Input split is the logical representation of data. RecordReader communicates with the InputSplit and converts the data into Kay-value pairs. Hence
- Key is a reference to the input value.
- Value is the data set on which to operate.
Number of maps depends on the total size of the input. i.e. the total number of blocks of the input files. Mapper= {(total data size)/ (input split size)} If data size= 1 Tb and input split size= 100 MB Hence, Mapper= (1000*1000)/100= 10,000
Mapper= {(total data size)/ (input split size)} If data size= 1 Tb and input split size= 100 MB Hence, Mapper= (1000*1000)/100= 10,000
If data size= 1 Tb and input split size= 100 MB HenceMapper= (1000*1000)/100= 10,000
Mapper= (1000*1000)/100= 10,000
56) What is Reducer in Hadoop?
Reducer takes the output of the Mapper (intermediate key-value pair) as the input. After that, it runs a reduce function on each of them to generate the output. Thus the output of the reducer is the final output, which it stored in HDFS. Usually, in Reducer, we do aggregation or summation sort of computation. Reducer has three primary phases-
- Shuffle- The framework, fetches the relevant partition of the output of all the Mappers for each reducer via HTTP.
- Sort- The framework groups Reducers inputs by the key in this Phase. Shuffle and sort phases occur simultaneously.
- Reduce- After shuffling and sorting, reduce task aggregates the key-value pairs. In this phase, call the reduce (Object, Iterator, OutputCollector, Reporter) method for each <key, (list of values)> pair in the grouped inputs.
Reducer in Hadoop MapReduce
With the help of Job.setNumreduceTasks(int) the user set the number of reducers for the job.
Hence, right number of reducers is 0.95 or 1.75 multiplied by (<no. of nodes>*<no. of maximum container per node>)
57) How to set mappers and reducers for MapReduce jobs?
One can configure JobConf to set number of mappers and reducers.
- For Mapper – job.setNumMaptasks()
- For Reducer – job.setNumreduceTasks()
These were some general MapReduce Hadoop interview questions and answers. Now let us take some Mapreduce Hadoop interview questions and answers specially for freshers.
MapReduce Hadoop Interview Question and Answer for Freshers
58) What is the key- value pair in Hadoop MapReduce?
Hadoop MapReduce implements a data model, which represents data as key-value pairs. Both input and output to MapReduce Framework should be in Key-value pairs only. In Hadoop, if a schema is static we can directly work on the column instead of key-value. But, the schema is not static we will work on keys and values. Keys and values are not the intrinsic properties of the data. But the user analyzing the data chooses a key-value pair.
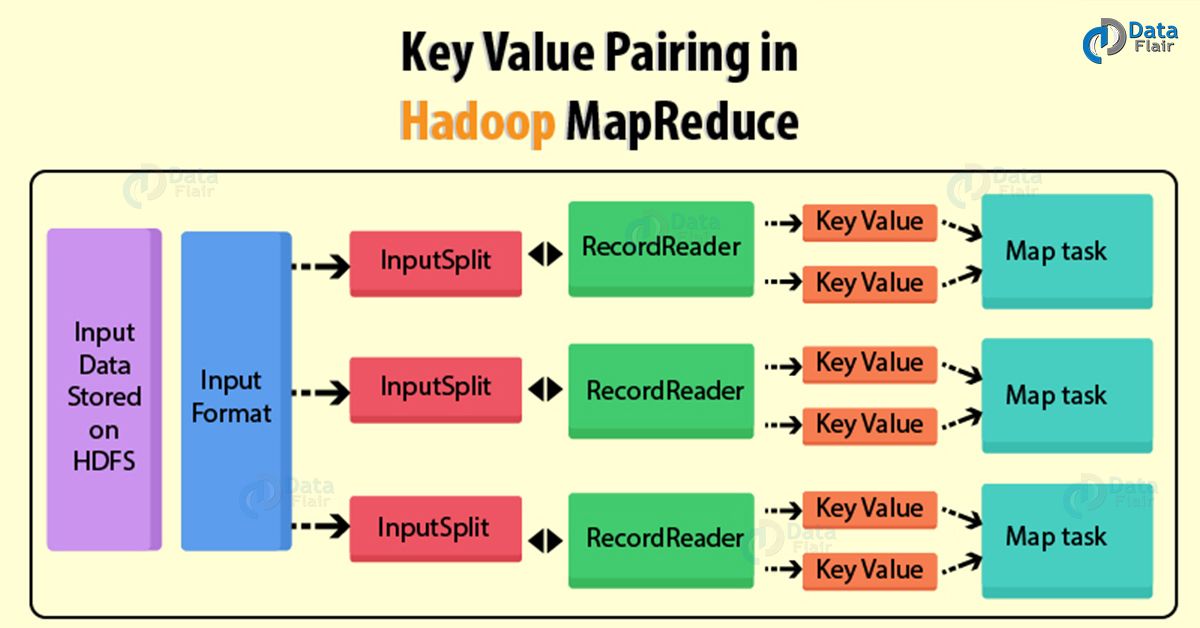
Hadoop MapReduce Key Value Pair
A Key-value pair in Hadoop MapReduce generate in following way:
- InputSplit – It is the logical representation of data. InputSplit represents the data which individual Mapper will process.
- RecordReader – It converts the split into records which are in form of Key-value pairs. That is suitable for reading by the mapper.
By Default RecordReader uses TextInputFormat for converting data into a key-value pair. - Key – It is the byte offset of the beginning of the line within the file.
- Value – It is the contents of the line, excluding line terminators. For
For Example, file content is- on the top of the crumpetty Tree
Key- 0
Value- on the top of the crumpetty Tree
Read about MapReduce Key-value pair in detail.
59) What is the need of key-value pair to process the data in MapReduce?
Hadoop MapReduce works on unstructured and semi-structured data apart from structured data. One can read the Structured data like the ones stored in RDBMS by columns.
But handling unstructured data is feasible using key-value pairs. The very core idea of MapReduce work on the basis of these pairs. Framework map data into a collection of key-value pairs by mapper and reducer on all the pairs with the same key.
In most of the computations- Map operation applies on each logical “record” in our input. This computes a set of intermediate key-value pairs. Then apply reduce operation on all the values that share the same key. This combines the derived data properly.
Thus, we can say that key-value pairs are the best solution to work on data problems on MapReduce.
60) What are the most common InputFormats in Hadoop?
In Hadoop, Input files store the data for a MapReduce job. Input files which stores data typically reside in HDFS. Thus, in MapReduce, InputFormat defines how these input files split and read. InputFormat creates InputSplit.
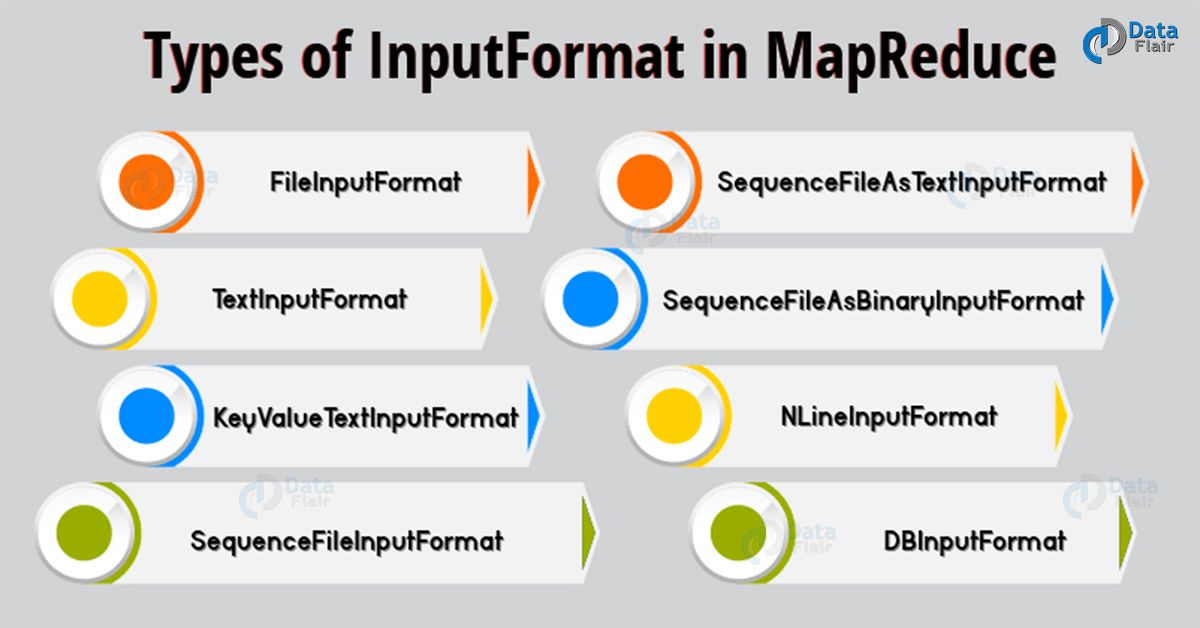
Types of InputFormat in MapReduce
Most common InputFormat are:
- FileInputFormat – For all file-based InputFormat it is the base class . It also specifies input directory where data files are present. FileInputFormat also read all files. And, then divides these files into one or more InputSplits.
- TextInputFormat – It is the default InputFormat of MapReduce. It uses each line of each input file as a separate record. Thus, performs no parsing.
Key- byte offset.
Value- It is the contents of the line, excluding line terminators. - KeyValueTextInputFormat – It also treats each line of input as a separate record. But the main difference is that TextInputFormat treats entire line as the value. While the KeyValueTextInputFormat breaks the line itself into key and value by the tab character (‘/t’).
Key- Everything up to tab character.
Value- Remaining part of the line after tab character. - SequenceFileInputFormat – It reads sequence files.
Key & Value- Both are user-defined.
Read about Mapreduce InputFormat in detail.
61) Explain InputSplit in Hadoop?
InputFormat creates InputSplit. InputSplit is the logical representation of data. Further Hadoop framework divides InputSplit into records. Then mapper will process each record. The size of split is approximately equal to HDFS block size (128 MB). In MapReduce program, Inputsplit is user defined. So, the user can control split size based on the size of data.
InputSplit in mapreduce has a length in bytes. It also has set of storage locations (hostname strings). It use storage location to place map tasks as close to split’s data as possible. According to the inputslit size each Map tasks process. So that the largest one gets processed first, this minimize the job runtime. In MapReduce, important thing is that InputSplit is just a reference to the data, not contain input data.
By calling ‘getSplit()’ client who is running job calculate the split for the job . And then send to the application master and it will use their storage location to schedule map tasks. And that will process them on the cluster. In MapReduce, split is send to the createRecordReader() method. It will create RecordReader for the split in mapreduce job. Then RecordReader generate record (key-value pair). Then it passes to the map function.
Read about MapReduce InputSplit in detail.
62) Explain the difference between a MapReduce InputSplit and HDFS block.
Tip for these type of Mapreduce Hadoop interview questions and and answers: Start with the definition of Block and InputSplit and answer in a comparison language and then cover its data representation, size and example and that too in a comparison language.
By definition-
- Block – It is the smallest unit of data that the file system store. In general, FileSystem store data as a collection of blocks. In a similar way, HDFS stores each file as blocks, and distributes it across the Hadoop cluster.
- InputSplit – InputSplit represents the data which individual Mapper will process. Further split divides into records. Each record (which is a key-value pair) will be processed by the map.
Size-
- Block – The default size of the HDFS block is 128 MB which is configured as per our requirement. All blocks of the file are of the same size except the last block. The last Block can be of same size or smaller. In Hadoop, the files split into 128 MB blocks and then stored into Hadoop Filesystem.
- InputSplit – Split size is approximately equal to block size, by default.
Data representation-
- Block – It is the physical representation of data.
- InputSplit – It is the logical representation of data. Thus, during data processing in MapReduce program or other processing techniques use InputSplit. In MapReduce, important thing is that InputSplit does not contain the input data. Hence, it is just a reference to the data.
Read more differences between MapReduce InputSplit and HDFS block.
63) What is the purpose of RecordReader in hadoop?
RecordReader in Hadoop uses the data within the boundaries, defined by InputSplit. It creates key-value pairs for the mapper. The “start” is the byte position in the file. Thus at ‘start the RecordReader should start generating key-value pairs. And the “end” is where it should stop reading records
RecordReader in MapReduce job load data from its source. And then, converts the data into key-value pairs suitable for reading by the mapper. RecordReader communicates with the InputSplit until it does not read the complete file. The MapReduce framework defines RecordReader instance by the InputFormat. By, default RecordReader also uses TextInputFormat for converting data into key-value pairs.
TextInputFormat provides 2 types of RecordReader : LineRecordReader and SequenceFileRecordReader.
LineRecordReader in Hadoop is the default RecordReader that TextInputFormat provides. Hence, each line of the input file is the new value and the key is byte offset.
SequenceFileRecordReader in Hadoop reads data specified by the header of a sequence file.
Read about MapReduce RecordReder in detail.
64) What is Combiner in Hadoop?
In MapReduce job, Mapper Generate large chunks of intermediate data. Then pass it to reduce for further processing. All this leads to enormous network congestion. Hadoop MapReduce framework provides a function known as Combiner. It plays a key role in reducing network congestion.
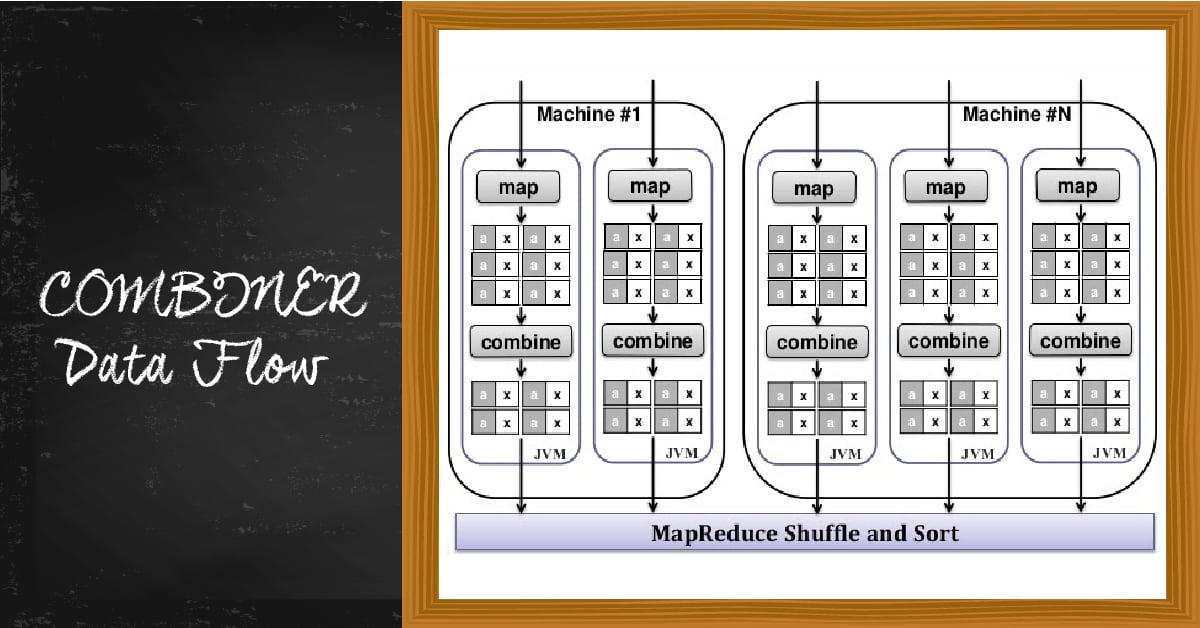
Combiner Dataflow
The Combiner in Hadoop is also known as Mini-reducer that performs local aggregation on the mapper’s output. This reduces the data transfer between mapper and reducer and increases the efficiency.
There is no guarantee of execution of Ccombiner in Hadoop i.e. Hadoop may or may not execute a combiner. Also if required it may execute it more than 1 times. Hence, your MapReduce jobs should not depend on the Combiners execution.
Read about MapReduce Combiner in detail.
65) Explain about the partitioning, shuffle and sort phase in MapReduce?
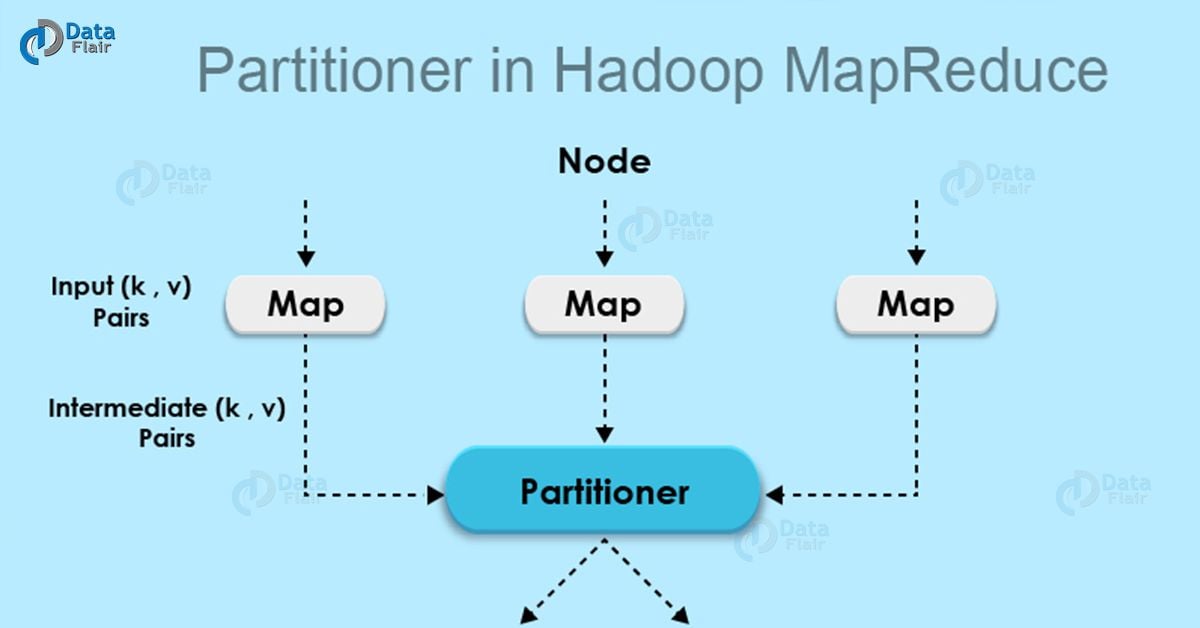
Hadoop Partitioned
Partitioning Phase – Partitioning specifies that all the values for each key are grouped together. Then make sure that all the values of a single key go on the same Reducer. Thus allows even distribution of the map output over the Reducer.
Shuffle Phase – It is the process by which the system sorts the key-value output of the map tasks. After that it transfer to the reducer.
Sort Phase – Mapper generate the intermediate key-value pair. Before starting of Reducer, map reduce framework sort these key-value pairs by the keys. It also helps reducer to easily distinguish when a new reduce task should start. Thus saves time for the reducer.
Read about Shuffling and Sorting in detail
66) What does a “MapReduce Partitioner” do?
Partitioner comes int the picture, if we are working on more than one reducer. Partitioner controls the partitioning of the keys of the intermediate map-outputs. By hash function, the key (or a subset of the key) is used to derive the partition. Partitioning specifies that all the values for each key grouped together. And it make sure that all the values of single key goes on the same reducer. Thus allowing even distribution of the map output over the reducers. It redirects the Mappers output to the reducers by determining which reducer is responsible for the particular key.
The total number of partitioner is equal to the number of Reducer. Partitioner in Hadoop will divide the data according to the number of reducers. Thus, single reducer process the data from the single partitioner.
Read about MapReduce Partitioner in detail.
67) If no custom partitioner is defined in Hadoop then how is data partitioned before it is sent to the reducer?
So, Hadoop MapReduce by default uses ‘HashPartitioner’.
It uses the hashCode() method to determine, to which partition a given (key, value) pair will be sent. HashPartitioner also has a method called getPartition.
HashPartitioner also takes key.hashCode() & integer>MAX_VALUE. It takes these code to finds the modulus using the number of reduce tasks. Suppose there are 10 reduce tasks, then getPartition will return values 0 through 9 for all keys.
Public class HashPartitioner<k, v>extends Partitioner<k, v>
{
Public int getpartitioner(k key, v value, int numreduceTasks)
{
Return (key.hashCode() & Integer.Max_VALUE) % numreduceTasks;
}
}These are very common type of MapReduce Hadoop interview questions and answers faced during the interview of a Fresher.
68) How to write a custom partitioner for a Hadoop MapReduce job?
This is one of the most common MapReduce Hadoop interview question and answer
It stores the results uniformly across different reducers, based on the user condition.
By setting a Partitioner to partition by the key, we can guarantee that records for the same key will go the same reducer. It also ensures that only one reducer receives all the records for that particular key.
By the following steps, we can write Custom partitioner for a Hadoop MapReduce job:
- Create a new class that extends Partitioner Class.
- Then, Override method getPartition, in the wrapper that runs in the MapReduce.
- By using method set Partitioner class, add the custom partitioner to the job. Or add the custom partitioner to the job as config file.
69) What is shuffling and sorting in Hadoop MapReduce?
Shuffling and Sorting takes place after the completion of map task. Shuffle and sort phase in Hadoop occurs simultaneously.
- Shuffling- Shuffling is the process by which the system sorts the key-value output of the map tasks and transfer it to the reducer. Shuffle phase is important for reducers, otherwise, they would not have any input. As shuffling can start even before the map phase has finished. So this saves some time and completes the task in lesser time.
- Sorting- Mapper generate the intermediate key-value pair. Before starting of reducer, mapreduce framework sort these key-value pair by the keys. It also helps reducer to easily distinguish when a new reduce task should start. Thus saves time for the reducer.
Shuffling and sorting are not performed at all if you specify zero reducer (setNumReduceTasks(0))
Read about Shuffling and Sorting in detail.
70) Why aggregation cannot be done in Mapper?
Mapper task processes each input record (From RecordReader) and generates a key-value pair. The Mapper store intermediate-output on the local disk.
We cannot perform aggregation in mapper because:
- Sorting takes place only on the Reducer function. Thus there is no provision for sorting in the mapper function. Without sorting aggregation is not possible.
- To perform aggregation, we need the output of all the Mapper function. Thus, which may not be possible to collect in the map phase. Because mappers may be running on different machines where the data blocks are present.
- If we will try to perform aggregation of data at mapper, it requires communication between all mapper functions. Which may be running on different machines. Thus, this will consume high network bandwidth and can cause network bottlenecking.
71) Explain map-only job?
MapReduce is the data processing layer of Hadoop. It is the framework for writing applications that process the vast amount of data stored in the HDFS. It processes the huge amount of data in parallel by dividing the job into a set of independent tasks (sub-job). In Hadoop, MapReduce have 2 phases of processing: Map and Reduce.
In Map phase we specify all the complex logic/business rules/costly code. Map takes a set of data and converts it into another set of data. It also break individual elements into tuples (key-value pairs). In Reduce phase we specify light-weight processing like aggregation/summation. Reduce takes the output from the map as input. After that it combines tuples (key-value) based on the key. And then, modifies the value of the key accordingly.
Consider a case where we just need to perform the operation and no aggregation required. Thus, in such case, we will prefer “Map-Only job” in Hadoop. In Map-Only job, the map does all task with its InputSplit and the reducer do no job. Map output is the final output.
This we can achieve by setting job.setNumreduceTasks(0) in the configuration in a driver. This will make a number of reducer 0 and thus only mapper will be doing the complete task.
Read about map-only job in Hadoop Mapreduce in detail.
72) What is SequenceFileInputFormat in Hadoop MapReduce?
SequenceFileInputFormat is an InputFormat which reads sequence files. Sequence files are binary files that stores sequences of binary key-value pairs. These files are block-compress. Thus, Sequence files provide direct serialization and deserialization of several arbitrary data types.
Here Key and value- Both are user-defined.
SequenceFileAsTextInputFormat is variant of SequenceFileInputFormat. It converts the sequence file’s key value to text objects. Hence, by calling ‘tostring()’ it performs conversion on the keys and values. Thus, this InputFormat makes sequence files suitable input for streaming.
SequenceFileAsBinaryInputFormat is variant of SequenceFileInputFormat. Hence, by using this we can extract the sequence file’s keys and values as an opaque binary object.
The above 58 – 72 MapReduce Hadoop interview questions and answers were for freshers, However experienced can also go through these MapReduce Hadoop interview questions and answers for revising the basics.
MapReduce Hadoop Interview questions and Answers for Experienced
73) What is KeyValueTextInputFormat in Hadoop?
KeyValueTextInputFormat- It treats each line of input as a separate record. It breaks the line itself into key and value. Thus, it uses the tab character (‘/t’) to break the line into a key-value pair.
Key- Everything up to tab character.
Value- Remaining part of the line after tab character.
Consider the following input file, where → represents a (horizontal) tab character:
But→ his face you could not see
Account→ of his beaver hat Hence,
Output:
Key- But
Value- his face you could not see
Key- Account
Value- of his beaver hat
74) Differentiate Reducer and Combiner in Hadoop MapReduce?
Combiner- The combiner is Mini-Reducer that perform local reduce task. It run on the Map output and produces the output to reducer input. Combiner is usually used for network optimization.
Reducer- Reducer takes a set of an intermediate key-value pair produced by the mapper as the input. Then runs a reduce function on each of them to generate the output. An output of the reducer is the final output.
- Unlike a reducer, the combiner has a limitation . i.e. the input or output key and value types must match the output types of the mapper.
- Combiners can operate only on a subset of keys and values . i.e. combiners can execute on functions that are commutative.
- Combiner functions take input from a single mapper. While reducers can take data from multiple mappers as a result of partitioning.
75) Explain the process of spilling in MapReduce?
Map task processes each input record (from RecordReader) and generates a key-value pair. The Mapper does not store its output on HDFS. Thus, this is temporary data and writing on HDFS will create unnecessary multiple copies. The Mapper writes its output into the circular memory buffer (RAM). Size of the buffer is 100 MB by default. We can also change it by using mapreduce.task.io.sort.mb property.
Now, spilling is a process of copying the data from the memory buffer to disc. It takes place when the content of the buffer reaches a certain threshold size. So, background thread by default starts spilling the contents after 80% of the buffer size has filled. Therefore, for a 100 MB size buffer, the spilling will start after the content of the buffer reach a size of 80MB.
76) What happen if number of reducer is set to 0 in Hadoop?
If we set the number of reducer to 0:
- Then no reducer will execute and no aggregation will take place.
- In such case we will prefer “Map-only job” in Hadoop. In map-Only job, the map does all task with its InputSplit and the reducer do no job. Map output is the final output.
In between map and reduce phases there is key, sort, and shuffle phase. Sort and shuffle phase are responsible for sorting the keys in ascending order. Then grouping values based on same keys. This phase is very expensive. If reduce phase is not required we should avoid it. Avoiding reduce phase would eliminate sort and shuffle phase as well. This also saves network congestion. As in shuffling an output of mapper travels to reducer,when data size is huge, large data travel to reducer.
77) What is Speculative Execution in Hadoop?
MapReduce breaks jobs into tasks and run these tasks parallely rather than sequentially. Thus reduces execution time. This model of execution is sensitive to slow tasks as they slow down the overall execution of a job. There are various reasons for the slowdown of tasks like hardware degradation. But it may be difficult to detect causes since the tasks still complete successfully. Although it takes more time than the expected time.
Hadoop framework doesn’t try to fix and diagnose slow running task. It tries to detect them and run backup tasks for them. This process is called Speculative execution in Hadoop. These backup tasks are called Speculative tasks in Hadoop.
First of all Hadoop framework launch all the tasks for the job in Hadoop MapReduce. Then it launch speculative tasks for those tasks that have been running for some time (one minute). And the task that have not made any much progress, on average, as compared with other tasks from the job.
If the original task completes before the speculative task. Then it will kill speculative task . On the other hand, it will kill the original task if the speculative task finishes before it.
Read about Speculative Execution in detail.
78) What counter in Hadoop MapReduce?
Counters in MapReduce are useful Channel for gathering statistics about the MapReduce job. Statistics like for quality control or for application-level. They are also useful for problem diagnosis.

Context Object
Counters validate that:
- Number of bytes read and write within map/reduce job is correct or not
- The number of tasks launches and successfully run in map/reduce job is correct or not.
- The amount of CPU and memory consumed is appropriate for our job and cluster nodes.
There are two types of counters:
- Built-In Counters – In Hadoop there are some built-In counters for every job. These report various metrics, like, there are counters for the number of bytes and records. Thus, this allows us to confirm that it consume the expected amount of input. Also make sure that it produce the expected amount of output.
- User-Defined Counters – Hadoop MapReduce permits user code to define a set of counters. These are then increased as desired in the mapper or reducer. For example, in Java, use ‘enum’ to define counters.
Read about Counters in detail.
79) How to submit extra files(jars,static files) for MapReduce job during runtime in Hadoop?
MapReduce framework provides Distributed Cache to caches files needed by the applications. It can cache read-only text files, archives, jar files etc.
An application which needs to use distributed cache to distribute a file should make sure that the files are available on URLs.
URLs can be either hdfs:// or http://.
Now, if the file is present on the hdfs:// or http://urls. Then, user mentions it to be cache file to distribute. This framework will copy the cache file on all the nodes before starting of tasks on those nodes. The files are only copied once per job. Applications should not modify those files.
80) What is TextInputFormat in Hadoop?
TextInputFormat is the default InputFormat. It treats each line of the input file as a separate record. For unformatted data or line-based records like log files, TextInputFormat is useful. By default, RecordReader also uses TextInputFormat for converting data into key-value pairs. So,
- Key- It is the byte offset of the beginning of the line.
- Value- It is the contents of the line, excluding line terminators.
File content is- on the top of the building
so,
Key- 0
Value- on the top of the building
TextInputFormat also provides below 2 types of RecordReader-
- LineRecordReader
- SequenceFileRecordReader
Top Interview Quetions for Hadoop MapReduce
81) How many Mappers run for a MapReduce job?
Number of mappers depends on 2 factors:
- Amount of data we want to process along with block size. It is driven by the number of inputsplit. If we have block size of 128 MB and we expect 10TB of input data, we will have 82,000 maps. Ultimately InputFormat determines the number of maps.
- Configuration of the slave i.e. number of core and RAM available on slave. The right number of map/node can between 10-100. Hadoop framework should give 1 to 1.5 cores of processor for each mapper. For a 15 core processor, 10 mappers can run.
In MapReduce job, by changing block size we can control number of Mappers . By Changing block size the number of inputsplit increases or decreases.
By using the JobConf’s conf.setNumMapTasks(int num) we can increase the number of map task.
Mapper= {(total data size)/ (input split size)}
If data size= 1 Tb and input split size= 100 MB
Mapper= (1000*1000)/100= 10,000
82) How many Reducers run for a MapReduce job?
Answer these type of MapReduce Hadoop interview questions answers very shortly and to the point.
With the help of Job.setNumreduceTasks(int) the user set the number of reduces for the job. To set the right number of reducesrs use the below formula:
0.95 Or 1.75 multiplied by (<no. of nodes> * <no. of maximum container per node>).
As the map finishes, all the reducers can launch immediately and start transferring map output with 0.95. With 1.75, faster nodes finsihes first round of reduces and launch second wave of reduces .
With the increase of number of reducers:
- Load balancing increases.
- Cost of failures decreases.
- Framework overhead increases.
These are very common type of MapReduce Hadoop interview questions and answers faced during the interview of an experienced professional.
83) How to sort intermediate output based on values in MapReduce?
Hadoop MapReduce automatically sorts key-value pair generated by the mapper. Sorting takes place on the basis of keys. Thus, to sort intermediate output based on values we need to use secondary sorting.
There are two possible approaches:
- First, using reducer, reducer reads and buffers all the value for a given key. Then, do an in-reducer sort on all the values. Reducer will receive all the values for a given key (huge list of values), this cause reducer to run out of memory. Thus, this approach can work well if number of values is small.
- Second, using MapReduce paradigm. It sort the reducer input values, by creating a composite key” (using value to key conversion approach) . i.e.by adding a part of, or entire value to, the natural key to achieve sorting technique. This approach is scalable and will not generate out of, memory errors.
We need custom partitioner to make that all the data with same key (composite key with the value) . So, data goes to the same reducer and custom comparator. In Custom comparator the data grouped by the natural key once it arrives at the reducer.
84) What is purpose of RecordWriter in Hadoop?
Reducer takes mapper output (intermediate key-value pair) as an input. Then, it runs a reducer function on them to generate output (zero or more key-value pair). So, the output of the reducer is the final output.
RecordWriter writes these output key-value pair from the Reducer phase to output files. OutputFormat determines, how RecordWriter writes these key-value pairs in Output files. Hadoop provides OutputFormat instances which help to write files on the in HDFS or local disk.
85) What are the most common OutputFormat in Hadoop?
Reducer takes mapper output as input and produces output (zero or more key-value pair). RecordWriter writes these output key-value pair from the Reducer phase to output files. So, OutputFormat determines, how RecordWriter writes these key-value pairs in Output files.
FileOutputFormat.setOutputpath() method used to set the output directory. So, every Reducer writes a separate in a common output directory.
Most common OutputFormat are:
- TextOutputFormat – It is the default OutputFormat in MapReduce. TextOutputFormat writes key-value pairs on individual lines of text files. Keys and values of this format can be of any type. Because TextOutputFormat turns them to string by calling toString() on them.
- SequenceFileOutputFormat – This OutputFormat writes sequences files for its output. It is also used between MapReduce jobs.
- SequenceFileAsBinaryOutputFormat – It is another form of SequenceFileInputFormat. which writes keys and values to sequence file in binary format.
- DBOutputFormat – We use this for writing to relational databases and HBase. Then, it sends the reduce output to a SQL table. It accepts key-value pairs, where the key has a type extending DBwritable.
Read about outputFormat in detail.
86) What is LazyOutputFormat in Hadoop?
FileOutputFormat subclasses will create output files (part-r-nnnn), even if they are empty. Some applications prefer not to create empty files, which is where LazyOutputFormat helps.
LazyOutputFormat is a wrapper OutputFormat. It make sure that the output file should create only when it emit its first record for a given partition.
To use LazyOutputFormat, call its SetOutputFormatClass() method with the JobConf.
To enable LazyOutputFormat, streaming and pipes supports a – lazyOutput option.
87) How to handle record boundaries in Text files or Sequence files in MapReduce InputSplits?
InputSplit’s RecordReader in MapReduce will “start” and “end” at a record boundary.
In SequenceFile, every 2k bytes has a 20 bytes sync mark between the records. And, the sync marks between the records allow the RecordReader to seek to the start of the InputSplit. It contains a file, length and offset. It also find the first sync mark after the start of the split. And, the RecordReader continues processing records until it reaches the first sync mark after the end of the split.
Similarly, Text files use newlines instead of sync marks to handle record boundaries.
88) What are the main configuration parameters in a MapReduce program?
The main configuration parameters are:
- Input format of data.
- Job’s input locations in the distributed file system.
- Output format of data.
- Job’s output location in the distributed file system.
- JAR file containing the mapper, reducer and driver classes
- Class containing the map function.
- Class containing the reduce function..
89) Is it mandatory to set input and output type/format in MapReduce?
No, it is mandatory.
Hadoop cluster, by default, takes the input and the output format as ‘text’.
TextInputFormat – MapReduce default InputFormat is TextInputFormat. It treats each line of each input file as a separate record and also performs no parsing. For unformatted data or line-based records like log files, TextInputFormat is also useful. By default, RecordReader also uses TextInputFormat for converting data into key-value pairs.
TextOutputFormat- MapReduce default OutputFormat is TextOutputFormat. It also writes (key, value) pairs on individual lines of text files. Its keys and values can be of any type.
90) What is Identity Mapper?
Identity Mapper is the default Mapper provided by Hadoop. When MapReduce program has not defined any mapper class then Identity mapper runs. It simply passes the input key-value pair for the reducer phase. Identity Mapper does not perform computation and calculations on the input data. So, it only writes the input data into output.
The class name is org.apache.hadoop.mapred.lib.IdentityMapper
91) What is Identity reducer?
Identity Reducer is the default Reducer provided by Hadoop. When MapReduce program has not defined any mapper class then Identity mapper runs. It does not mean that the reduce step will not take place. It will take place and related sorting and shuffling will also take place. But there will be no aggregation. So you can use identity reducer if you want to sort your data that is coming from the map but don’t care for any grouping.
The above MapReduce Hadoop interview questions and answers i.e Q. 73 – Q. 91 were for experienced but freshers can also refer these MapReduce Hadoop interview questions and answers for in depth knowledge. Now let’s move forward with some advanced MapReduce Hadoop interview questions and answers.
Advanced Interview Questions and Answers for Hadoop MapReduce
92) What is Chain Mapper?
We can use multiple Mapper classes within a single Map task by using Chain Mapper class. The Mapper classes invoked in a chained (or piped) fashion. The output of the first becomes the input of the second, and so on until the last mapper. The Hadoop framework write output of the last mapper to the task’s output.
The key benefit of this feature is that the Mappers in the chain do not need to be aware that they execute in a chain. And, this enables having reusable specialized Mappers. We can combine these mappers to perform composite operations within a single task in Hadoop.
Hadoop framework take Special care when create chains. The key/values output by a Mapper are valid for the following mapper in the chain.
The class name is org.apache.hadoop.mapred.lib.ChainMapper
This is one of the very important Mapreduce Hadoop interview questions and answers
93) What are the core methods of a Reducer?
Reducer process the output the mapper. After processing the data, it also produces a new set of output, which it stores in HDFS. And, the core methods of a Reducer are:
- setup()- Various parameters like the input data size, distributed cache, heap size, etc this method configure. Function Definition- public void setup (context)
- reduce() – Reducer call this method once per key with the associated reduce task. Function Definition- public void reduce (key, value, context)
- cleanup() – Reducer call this method only once at the end of reduce task for clearing all the temporary files. Function Definition- public void cleanup (context)
94) What are the parameters of mappers and reducers?
The parameters for Mappers are:
- LongWritable(input)
- text (input)
- text (intermediate output)
- IntWritable (intermediate output)
The parameters for Reducers are:
- text (intermediate output)
- IntWritable (intermediate output)
- text (final output)
- IntWritable (final output)
95) What is the difference between TextinputFormat and KeyValueTextInputFormat class?
TextInputFormat – It is the default InputFormat. It treats each line of the input file as a separate record. For unformatted data or line-based records like log files, TextInputFormat is also useful. So,
- Key- It is byte offset of the beginning of the line within the file.
- Value- It is the contents of the line, excluding line terminators.
KeyValueTextInputFormat – It is like TextInputFormat. The reason is it also treats each line of input as a separate record. But the main difference is that TextInputFormat treats entire line as the value. While the KeyValueTextInputFormat breaks the line itself into key and value by the tab character (‘/t’). so,
- Key- Everything up to tab character.
- Value- Remaining part of the line after tab character.
For example, consider a file contents as below:
AL#Alabama
AR#Arkansas
FL#Florida
So, TextInputFormat
Key value
0 AL#Alabama 14
AR#Arkansas 23
FL#Florida
So, KeyValueTextInputFormat
Key value
AL Alabama
AR Arkansas
FL Florida
These are some of the advanced MapReduce Hadoop interview Questions and answers
96) How is the splitting of file invoked in Hadoop ?
InputFormat is responsible for creating InputSplit, which is the logical representation of data. Further Hadoop framework divides split into records. Then, Mapper process each record (which is a key-value pair).
By running getInputSplit() method Hadoop framework invoke Splitting of file . getInputSplit() method belongs to Input Format class (like FileInputFormat) defined by the user.
97) How many InputSplits will be made by hadoop framework?
InputFormat is responsible for creating InputSplit, which is the logical representation of data. Further Hadoop framework divides split into records. Then, Mapper process each record (which is a key-value pair).
MapReduce system use storage locations to place map tasks as close to split’s data as possible. By default, split size is approximately equal to HDFS block size (128 MB).
For, example the file size is 514 MB,
128MB: 1st block, 128Mb: 2nd block, 128Mb: 3rd block,
128Mb: 4th block, 2Mb: 5th block
So, 5 InputSplit is created based on 5 blocks.
If in case you have any confusion about any MapReduce Hadoop Interview Questions, do let us know by leaving a comment. we will be glad to solve your queries.
98) Explain the usage of Context Object.
With the help of Context Object, Mapper can easily interact with other Hadoop systems. It also helps in updating counters. So counters can report the progress and provide any application-level status updates.
It contains configuration details for the job.
99) When is it not recommended to use MapReduce paradigm for large scale data processing?
For iterative processing use cases it is not suggested to use MapReduce. As it is not cost effective, instead Apache Pig can be used for the same.
100) What is the difference between RDBMS with Hadoop MapReduce?
Size of Data
- RDBMS- Traditional RDBMS can handle upto gigabytes of data.
- MapReduce- Hadoop MapReduce can hadnle upto petabytes of data or more.
Updates
- RDBMS- Read and Write multiple times.
- MapReduce- Read many times but write once model.
Schema
- RDBMS- Static Schema that needs to be pre-defined.
- MapReduce- Has a dynamic schema
Processing Model
- RDBMS- Supports both batch and interactive processing.
- MapReduce- Supports only batch processing.
Scalability
- RDBMS- Non-Linear
- MapReduce- Linear
101) Define Writable data types in Hadoop MapReduce.
Hadoop reads and writes data in a serialized form in the writable interface. The Writable interface has several classes like Text, IntWritable, LongWriatble, FloatWritable, BooleanWritable. Users are also free to define their personal Writable classes as well.
102) Explain what does the conf.setMapper Class do in MapReduce?
Conf.setMapperclass sets the mapper class. Which includes reading data and also generating a key-value pair out of the mapper.
Number 40-52 were the advanced HDFS Hadoop interview question and answer to get indepth knowledge in handling difficult Hadoop interview questions and answers.
This was all about the Hadoop Interview Questions and Answers
These questions are frequently asked MapReduce Hadoop interview questions and answers. You can read here some more Hadoop MapReduce interview questions and answers.
After going through these MapReduce Hadoop Interview questions and answers you will be able to confidently face a interview and will be able to answer MapReduce Hadoop Interview questions and answers asked in your interview in the best manner. These MapReduce Hadoop Interview Questions are suggested by the experts at DataFlair
Key –
Q.53 – Q57 Basic MapReduce Hadoop interview questions and answers
Q.58 – Q72 MapReduce Hadoop interview questions and answer for Freshers
Q.73 -Q. 80 Hadoop MapReduce Interview Questions for Experienced
Q.81 – Q.91 Top questions asked in Hadoop Interview
Q.92 – Q.102 were the advanced MapReduce Hadoop interview questions and answers
These MapReduce Hadoop interview questions and answers are categorized so that you can pay more attention to questions specified for you, however, it is recommended that you go through all the Hadoop interview questions and answers for complete understanding.
If you have any more doubt or query on Hadoop Interview Questions and Answers for Mapreduce, Drop a comment and our support team will be happy to help you.
Hope the tutorial on Hadoop interview questions and answers was helpful to you.
See Also –
- Hadoop Interview Questions and Answers for freshers and experienced
- Top 50 Hadoop Interview Questions and Answers
- Top 50+ Hadoop HDFS Interview Questions and Answers
- Top 60 Hadoop MapReduce Interview Questions and Answers
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





superb work done !!!!!!!!!!
very good job
Glad, you like our article of Hadoop Interview Questions and Answers. I hope by reading all these questions, now you are ready to crack the Hadoop Interview in one go. Still, if you think you need more preparations then you must visit the Hadoop Interview Questions Part 2, specially designed by Hadoop experts for both freshers and experienced in Hadoop Technology.
Here is the link for you –
https://data-flair.training/blogs/top-100-hadoop-interview-questions-and-answers/
We wish you luck for a bright future in Hadoop.
I have gone through the question(7) regarding ‘what is block in HDFS ?’ and got an idea regarding the last block size could be less than equal to 128 MB , so can you please elaborate that whether the remaining space 127 MB(suppose the last block size is 1 MB) can be utilized by other files ?
Thanks in advance.
This is a good interview question, Let me explain with an example if the file size is 129 MB & block size is default 128 MB then 2 blocks will be created:
– 1st block: block size: 128 MB which contains 128 MB data
– 2nd block: block size: 1 MB which contains 1 MB data
HDFS is smart, it won’t allocate 128 MB for the last block, rather it will allocate just 1 MB block (which is equal to the data size)