Rack Awareness in Hadoop HDFS – An Introductory Guide
Ever thought how NameNode choose the Datanode for storing the data blocks and their replicas?
HDFS stores files across multiple nodes (DataNodes) in a cluster. To get the maximum performance from Hadoop and to improve the network traffic during file read/write, NameNode chooses the DataNodes on the same rack or nearby racks for data read/write. Rack awareness is the concept of choosing the closer DataNode based on rack information.
In this article, we will study the rack awareness concept in detail.
We will first see what is the rack, what is rack awareness, the reason for using rack awareness, block replication policies, and benefits of Rack Awareness.
Let’s start with the introduction of the rack.
What is a rack?
The Rack is the collection of around 40-50 DataNodes connected using the same network switch. If the network goes down, the whole rack will be unavailable. A large Hadoop cluster is deployed in multiple racks.
What is Rack Awareness in Hadoop HDFS?
In a large Hadoop cluster, there are multiple racks. Each rack consists of DataNodes. Communication between the DataNodes on the same rack is more efficient as compared to the communication between DataNodes residing on different racks.
To reduce the network traffic during file read/write, NameNode chooses the closest DataNode for serving the client read/write request. NameNode maintains rack ids of each DataNode to achieve this rack information. This concept of choosing the closest DataNode based on the rack information is known as Rack Awareness.
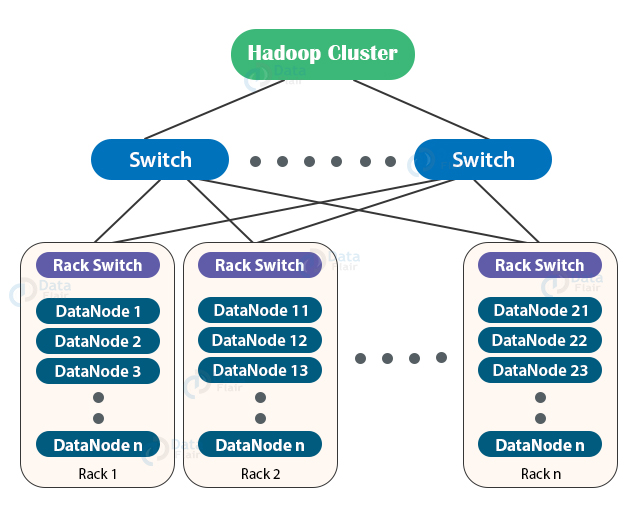
A default Hadoop installation assumes that all the DataNodes reside on the same rack.
Why Rack Awareness?
The reasons for the Rack Awareness in Hadoop are:
- To reduce the network traffic while file read/write, which improves the cluster performance.
- To achieve fault tolerance, even when the rack goes down (discussed later in this article).
- Achieve high availability of data so that data is available even in unfavorable conditions.
- To reduce the latency, that is, to make the file read/write operations done with lower delay.
NameNode uses a rack awareness algorithm while placing the replicas in HDFS.
Let us now study the replica placement via Rack Awareness in Hadoop.
Replica placement via Rack awareness in Hadoop
We know HDFS stores replicas of data blocks of a file to provide fault tolerance and high availability. Also, the network bandwidth between nodes within the rack is higher than the network bandwidth between nodes on a different rack.
If we store replicas on different nodes on the same rack, then it improves the network bandwidth, but if the rack fails (rarely happens), then there will be no copy of data on another rack.
Again, if we store replicas on unique racks, then due to the transfer of blocks to multiple racks while writes increase the cost of writes.
Therefore, NameNode on multiple rack cluster maintains block replication by using inbuilt Rack awareness policies which says:
- Not more than one replica be placed on one node.
- Not more than two replicas are placed on the same rack.
- Also, the number of racks used for block replication should always be smaller than the number of replicas.
For the common case where the replication factor is three, the block replication policy put the first replica on the local rack, a second replica on the different DataNode on the same rack, and a third replica on the different rack.
Also, while re-replicating a block, if the existing replica is one, place the second replica on a different rack. If the existing replicas are two and are on the same rack, then place the third replica on a different rack.
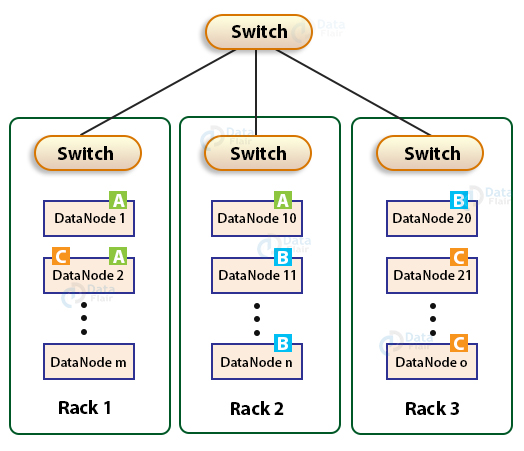
This policy improves write performance and network traffic without compromising fault tolerance.
Rack Awareness Example
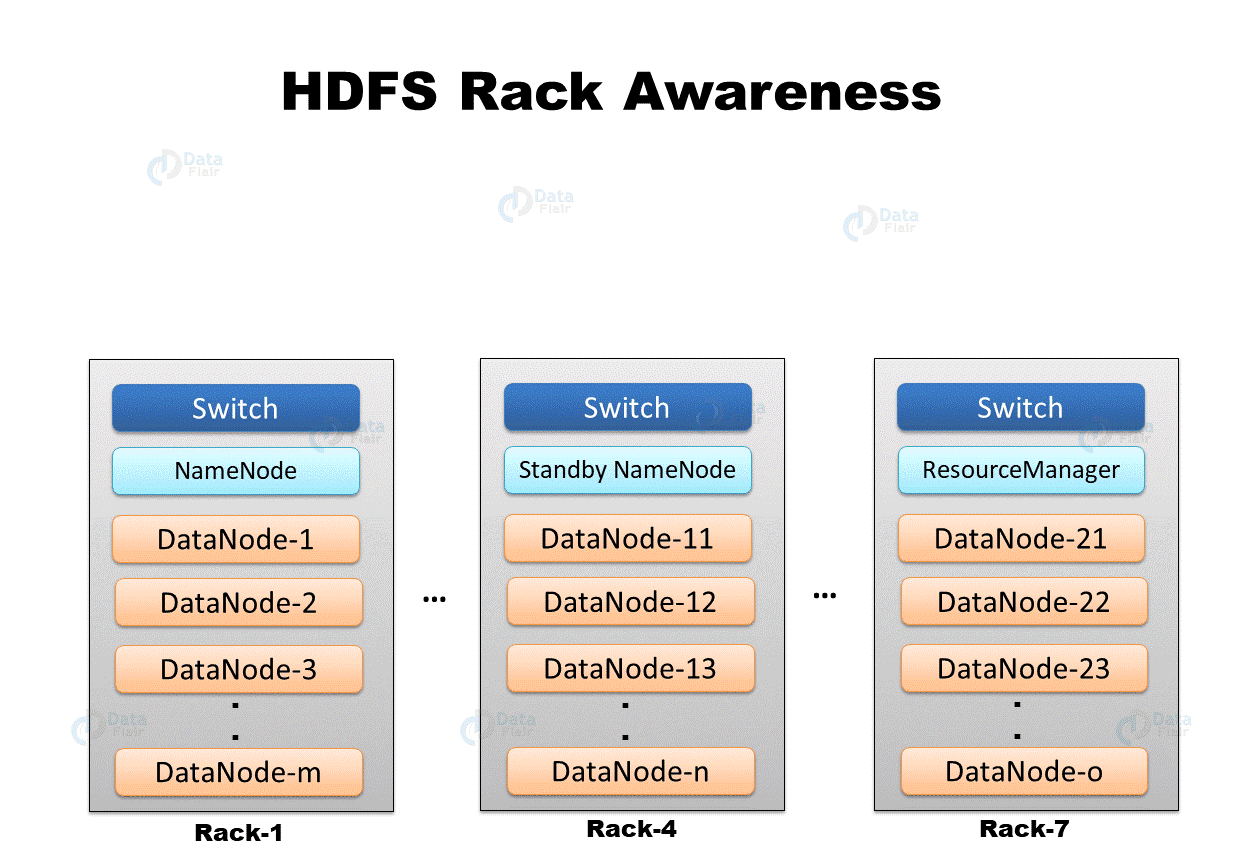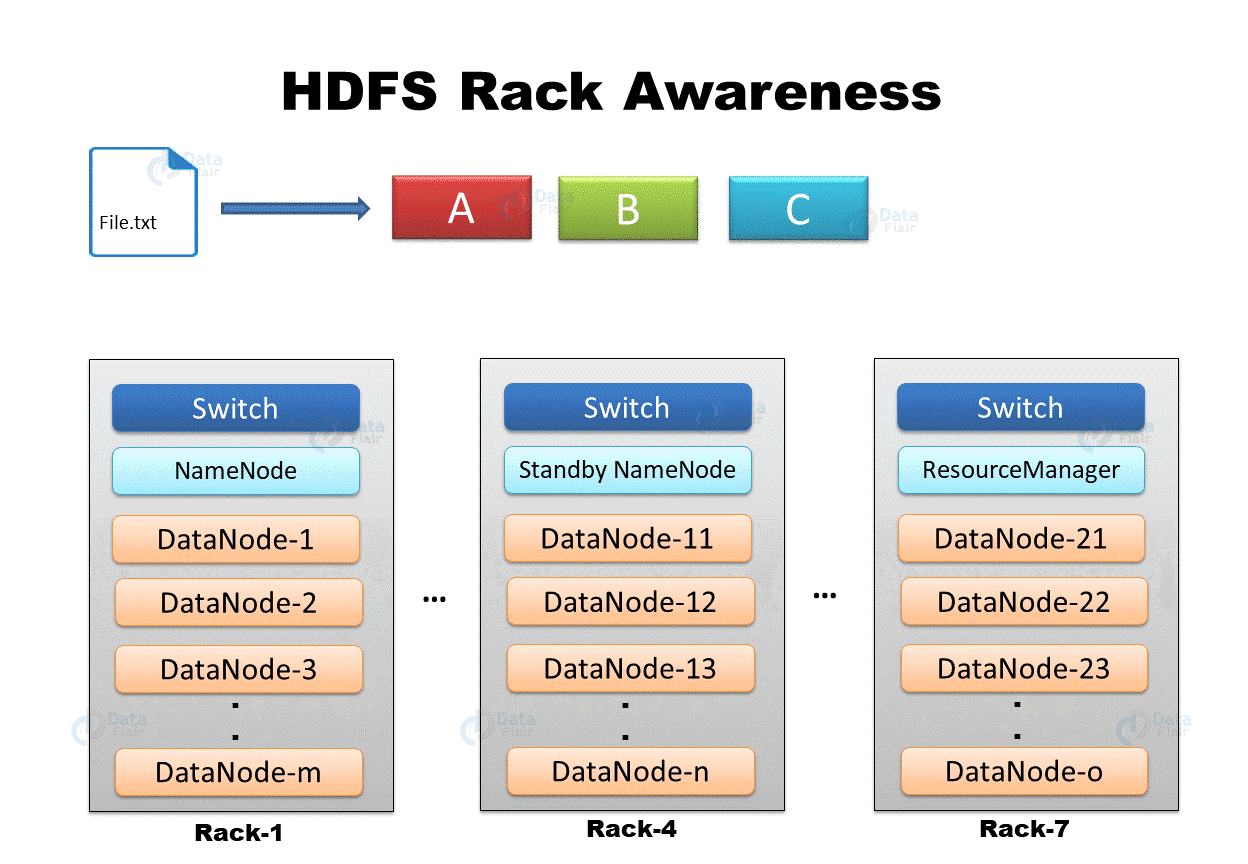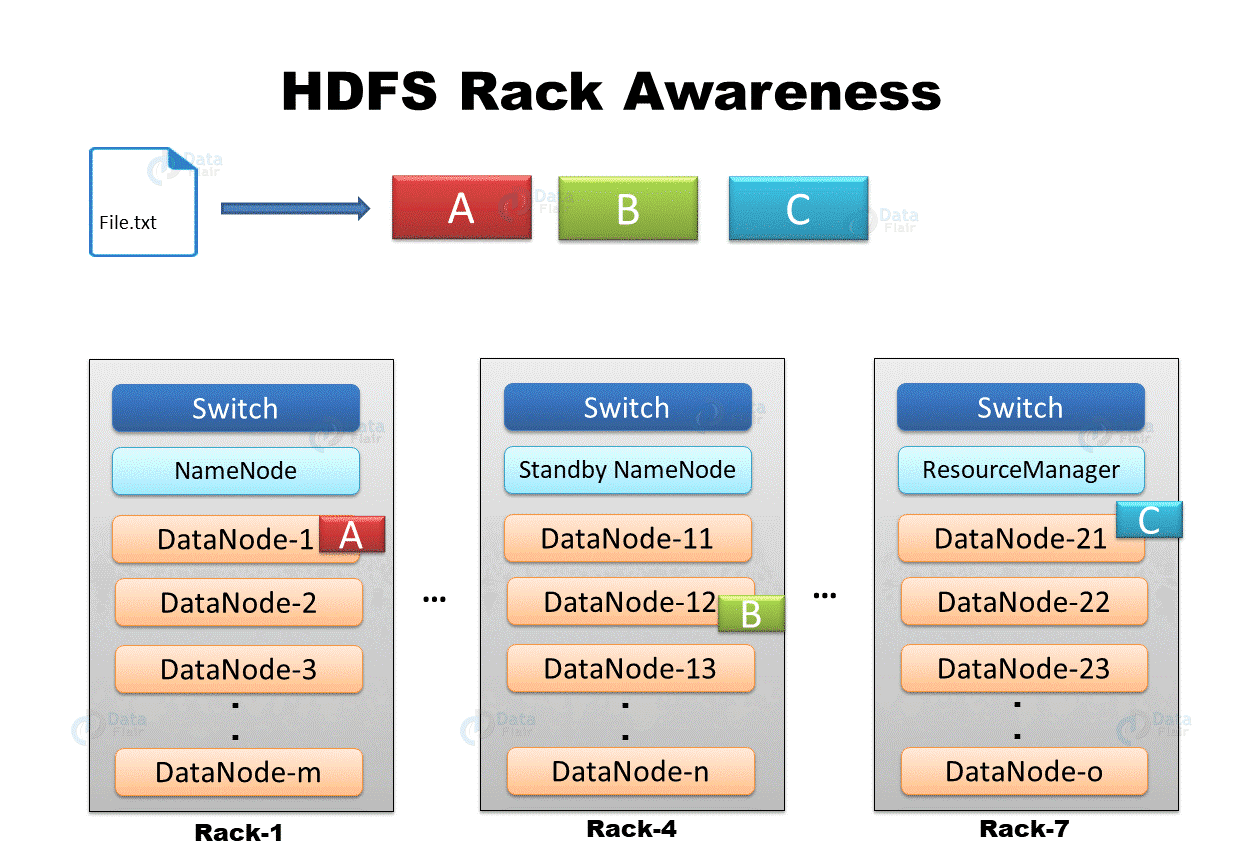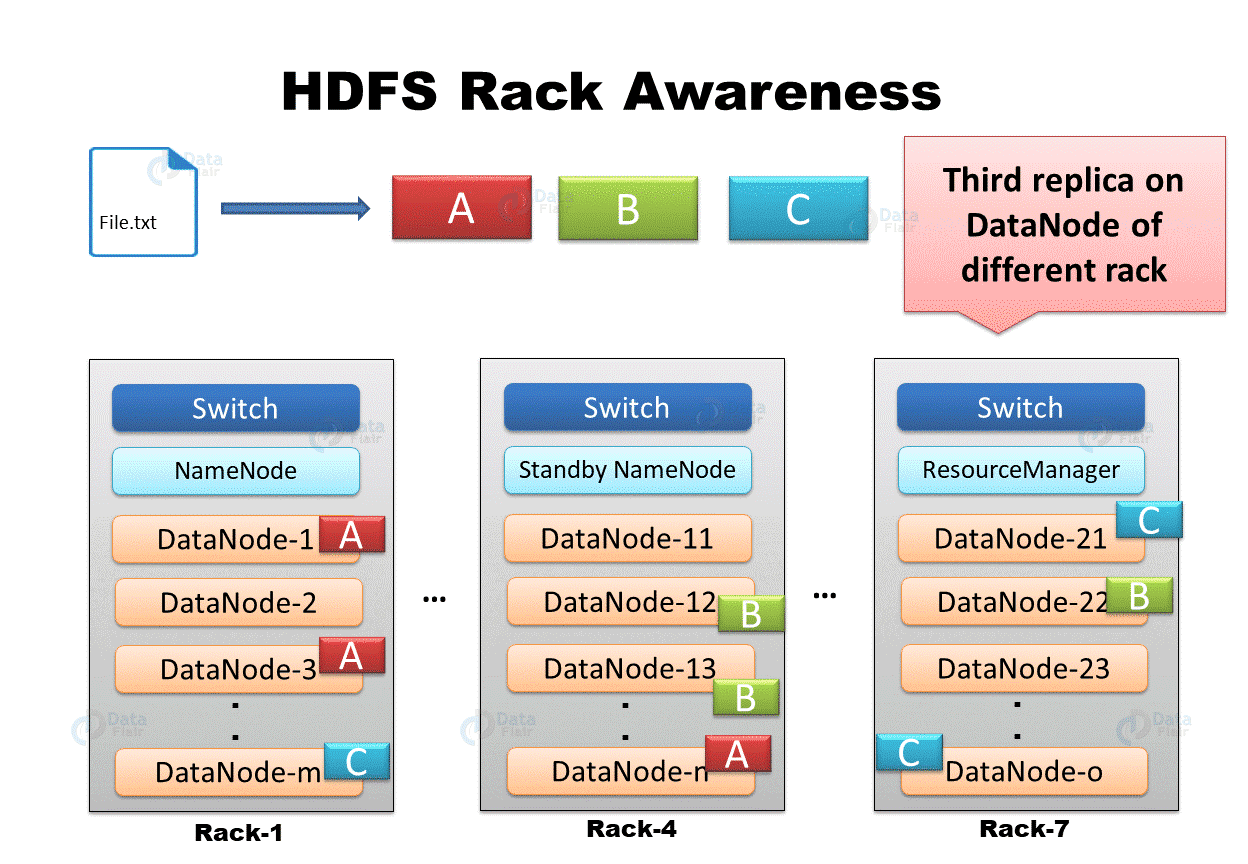
In the above GIF, we are having a file “File.txt” divided into three blocks A, B, and C. To provide fault tolerance, HDFS creates replicas of blocks. NameNode places the first copy of each block on the closest DataNode, the second replica of each block on different DataNode on the same rack, and the third replica on different DataNode on a different rack.
What about performance?
- Faster replication operation: Since the replicas are placed within the same rack it would use higher bandwidth and lower latency hence making it faster.
- If YARN is unable to create a container in the same data node where the queried data is located it would try to create the container in a data node within the same rack. This would be more performant because of the higher bandwidth and lower latency of the data nodes inside the same rack
Advantages of Implementing Rack Awareness
Some of the main advantages of Rack Awareness are:
1. Preventing data loss against rack failure
Rack Awareness policy puts replicas at different rack as well, thus ensures no data loss even if the rack fails.
2. Minimize the cost of write and maximize the read speed
Rack awareness reduces write traffic in between different racks by placing write requests to replicas on the same rack or nearby rack, thus reducing the cost of write. Also, using the bandwidth of multiple racks increases the read performance.
3. Maximize network bandwidth and low latency
Rack Awareness enables Hadoop to maximize network bandwidth by favoring the transfer of blocks within racks over transfer between racks. Especially with rack awareness, the YARN is able to optimize MapReduce job performance. It assigns tasks to nodes that are ‘closer’ to their data in terms of network topology. This is particularly beneficial in cases where tasks cannot be assigned to nodes where their data is stored locally.
Summary
In this article, you have studied the rack awareness concept, which is the selection of the closest node based on the rack information.
We have seen the reasons for introducing rack awareness in Hadoop like network bandwidth, high availability, etc.
We have also discussed the Rack awareness policy used by the NameNode to maintain block replication. The article also enlisted the advantages of Rack Awareness.
Now, its time to explore how Hadoop HDFS achieves High Availability
Any Doubt? Ask our DataFlair experts in the comment section.
Keep Learning
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





Nicely written and explained Rack awareness concept on Hadoop HDFS.
Hii Elma,
Thank you for reading the complete article on Rack Awareness in Hadoop HDFS and giving us a valuable feedback. Hope by reading the article, you got the reason to learn Rack Awareness and its Advantages also.
Keep visiting Data Flair for more such explanatory articles on Hadoop HDFS.
Great article for new users to understand rack awareness in HDFS. Thanks.
Glad to read your review, Florian.
This Rack Awareness Hadoop HDFS article is designed in such a way that not only professionals but the beginners of both Hadoop and HDFS technology can easily understand the topic. We have more such articles for you. You can check by clicking the link below:
https://data-flair.training/blogs/data-blocks-in-hadoop-hdfs/
How namenode choose datanodes which is closer to the same rack or different rack for read and write request….I cannot understand the line….can u explain in very detail
Its a client who request hdfs read/write operations, so name node will first check whether the hdfs client from which request came is part of cluster or not, if part of cluster it will try to find its rack and fetch data from the nearer rack as far as possible. Hope it clarifies.
great article.. very helpful.. I wish adding simple diagram to illustrate concept will be more helpful
Explained very nice.
I believe in cloud different subnets called racks.so I can deploy my data nodes between different nodes.do you think this is possible on cloud.
correct me if im wrong, in the example 1st block is stored in local node, second block stored in second node in second rack and third block in 2 rack 3rd node. But in actual
block1 – local node
block2 – 2nd node(2nd rack)
block3 – 2nd node(2nd rack)
block 1 – local node
block 2 – same rack
block 3 – other rack
I think it chooses by seeing the Rack Id. The Namenode checks if the Rack ID is same for 2 datanodes then the datanodes are closer to each other.
I have tried to answer Thayanban E’s question
Without RACK AWARENESS setup, how does the Namenode choose the datanode to perform the read/write operations? Would like to understand the difference. Another question is, Is it necessary to configure rack awareness if each datanode is created in different AZ or Availability Zone? Meaning datanode1 is in Zone1, datanode2 in Zone3, datanode3 in Zone2 etc.?
Is rack awareness relevant even in cloud deployment of Hadoop?
Great explanation .!!