How Hadoop Works Internally – Inside Hadoop
Apache Hadoop is an open source software framework that stores data in a distributed manner and process that data in parallel. Hadoop provides the world’s most reliable storage layer – HDFS, a batch processing engine – MapReduce and a resource management layer – YARN. In this tutorial on ‘How Hadoop works internally’, we will learn what is Hadoop, how Hadoop works, different components of Hadoop, daemons in Hadoop, roles of HDFS, MapReduce, and Yarn in Hadoop and various steps to understand How Hadoop works.
How Hadoop Works Internally – Inside Hadoop
What is Hadoop?
Before learning how Hadoop works, let’s brush the basic Hadoop concept. Apache Hadoop is a set of open-source software utilities. They facilitate usage of a network of many computers to solve problems involving massive amounts of data. It provides a software framework for distributed storage and distributed computing. It divides a file into the number of blocks and stores it across a cluster of machines. Hadoop also achieves fault tolerance by replicating the blocks on the cluster. It does distributed processing by dividing a job into a number of independent tasks. These tasks run in parallel over the computer cluster.
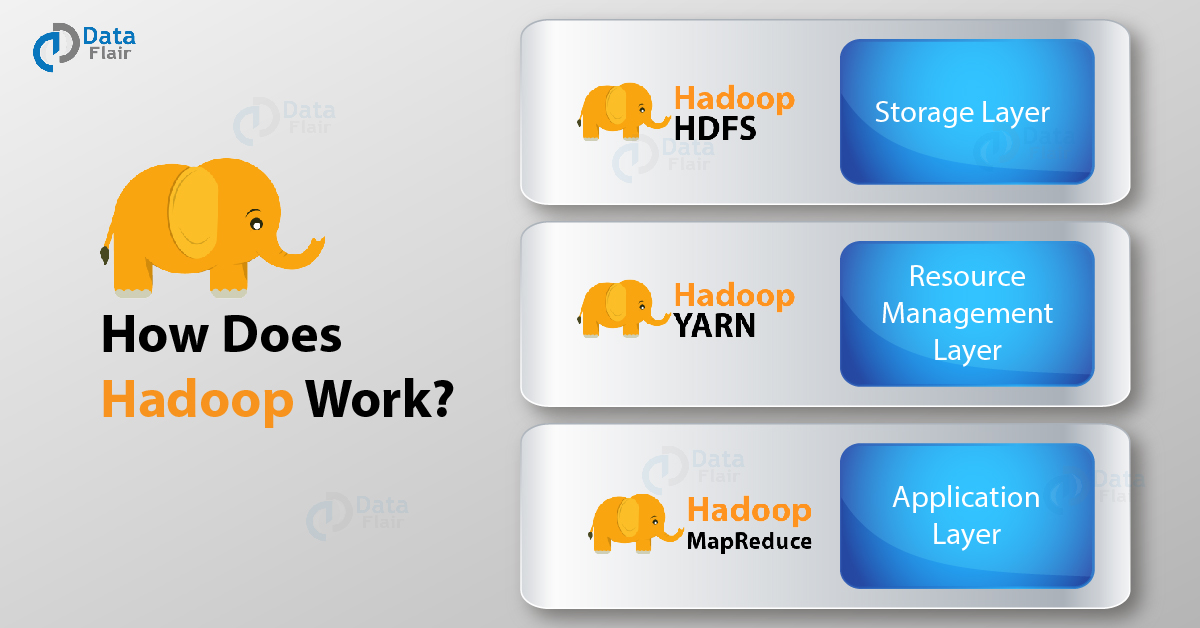
Hadoop Components and Domains
You can’t understand the working of Hadoop without knowing its core components. So, Hadoop consists of three layers (core components) and they are:-
HDFS – Hadoop Distributed File System provides for the storage of Hadoop. As the name suggests it stores the data in a distributed manner. The file gets divided into a number of blocks which spreads across the cluster of commodity hardware.
MapReduce – This is the processing engine of Hadoop. MapReduce works on the principle of distributed processing. It divides the task submitted by the user into a number of independent subtasks. These sub-task executes in parallel thereby increasing the throughput.
Yarn – Yet Another Resource Manager provides resource management for Hadoop. There are two daemons running for Yarn. One is NodeManager on the slave machines and other is the Resource Manager on the master node. Yarn looks after the allocation of the resources among various slave competing for it.

Learn about all the Hadoop Ecosystem Components in just 7 mins.
Daemons are the processes that run in the background. The Hadoop Daemons are:-
a) Namenode – It runs on master node for HDFS.
b) Datanode – It runs on slave nodes for HDFS.
c) Resource Manager – It runs on YARN master node for MapReduce.
d) Node Manager – It runs on YARN slave node for MapReduce.
These 4 daemons run for Hadoop to be functional.
Read: Distributed Chace in Hadoop
How Hadoop Works?
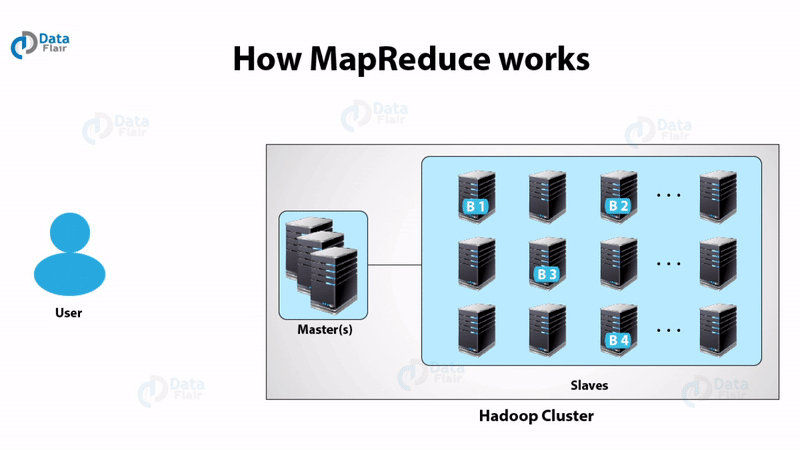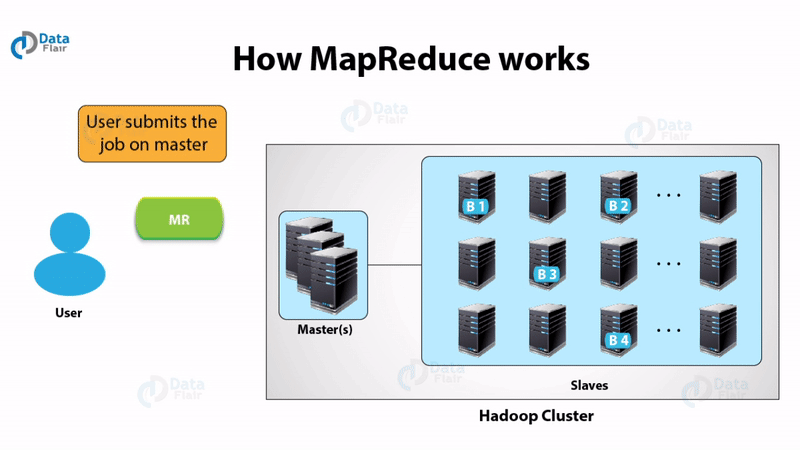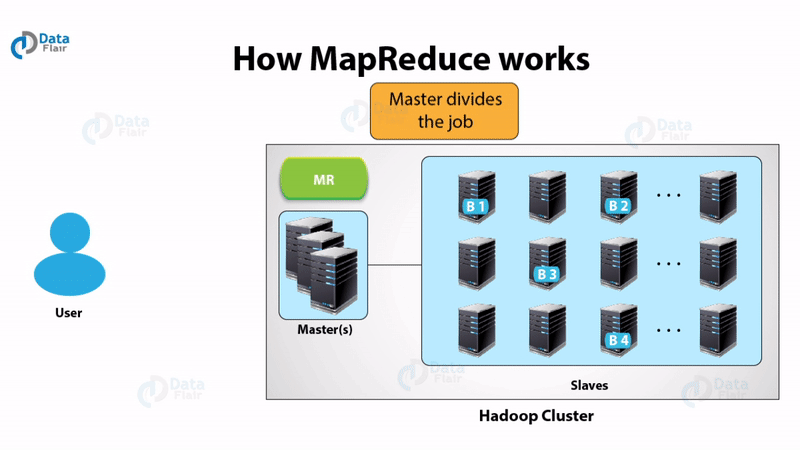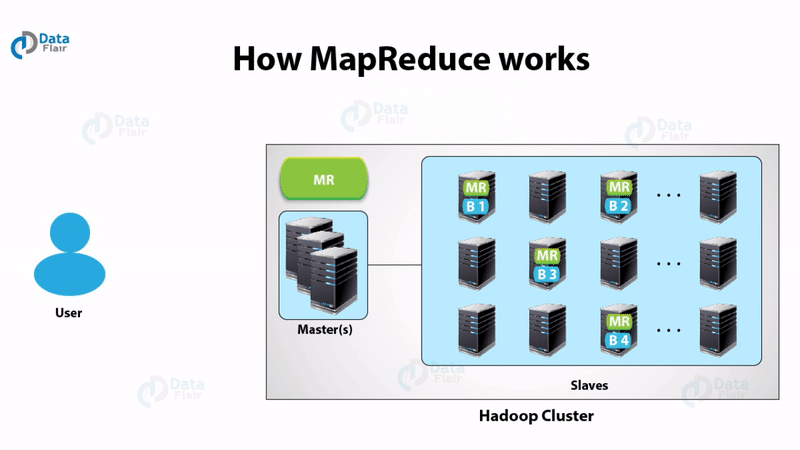
Hadoop does distributed processing for huge data sets across the cluster of commodity servers and works on multiple machines simultaneously. To process any data, the client submits data and program to Hadoop. HDFS stores the data while MapReduce process the data and Yarn divide the tasks.
Let’s discuss in detail how Hadoop works –
i. HDFS
Hadoop Distributed File System has master-slave topology. It has got two daemons running, they are NameNode and DataNode.
NameNode
NameNode is the daemon running of the master machine. It is the centerpiece of an HDFS file system. NameNode stores the directory tree of all files in the file system. It tracks where across the cluster the file data resides. It does not store the data contained in these files.
When the client applications want to add/copy/move/delete a file, they interact with NameNode. The NameNode responds to the request from client by returning a list of relevant DataNode servers where the data lives.
Recommended Reading – NameNode High Availability
DataNode
DataNode daemon runs on the slave nodes. It stores data in the HadoopFileSystem. In functional file system data replicates across many DataNodes.
On startup, a DataNode connects to the NameNode. It keeps on looking for the request from NameNode to access data. Once the NameNode provides the location of the data, client applications can talk directly to a DataNode, while replicating the data, DataNode instances can talk to each other.
Replica Placement
The placement of replica decides HDFS reliability and performance. Optimization of replica placement makes HDFS apart from other distributed system. Huge HDFS instances run on a cluster of computers spreads across many racks. The communication between nodes on different racks has to go through the switches. Mostly the network bandwidth between nodes on the same rack is more than that between the machines on separate racks.
The rack awareness algorithm determines the rack id of each DataNode. Under a simple policy, the replicas get placed on unique racks. This prevents data loss in the event of rack failure. Also, it utilizes bandwidth from multiple racks while reading data. However, this method increases the cost of writes.
Let us assume that the replication factor is three. Suppose HDFS’s placement policy places one replica on a local rack and other two replicas on the remote but same rack. This policy cuts the inter-rack write traffic thereby improving the write performance. The chances of rack failure are less than that of node failure. Hence this policy does not affect data reliability and availability. But, it does reduce the aggregate network bandwidth used when reading data. This is because a block gets placed in only two unique racks rather than three.
ii. MapReduce
The general idea of the MapReduce algorithm is to process the data in parallel on your distributed cluster. It subsequently combine it into the desired result or output.
Hadoop MapReduce includes several stages:
- In the first step, the program locates and reads the « input file » containing the raw data.
- As the file format is arbitrary, there is a need to convert data into something the program can process. The « InputFormat » and « RecordReader » (RR) does this job.
InputFormat uses InputSplit function to split the file into smaller pieces
Then the RecordReader transforms the raw data for processing by the map. It outputs a list of key-value pairs.
Once the mapper process these key-value pairs the result goes to « OutputCollector ». There is another function called « Reporter » which intimates the user when the mapping task finishes.
- In the next step, the Reduce function performs its task on each key-value pair from the mapper.
- Finally, OutputFormat organizes the key-value pairs from Reducer for writing it on HDFS.
- Being the heart of the Hadoop system, Map-Reduce process the data in a highly resilient, fault-tolerant manner.
iii. Yarn
Yarn divides the task on resource management and job scheduling/monitoring into separate daemons. There is one ResourceManager and per-application ApplicationMaster. An application can be either a job or a DAG of jobs.
The ResourceManger have two components – Scheduler and AppicationManager.
The scheduler is a pure scheduler i.e. it does not track the status of running application. It only allocates resources to various competing applications. Also, it does not restart the job after failure due to hardware or application failure. The scheduler allocates the resources based on an abstract notion of a container. A container is nothing but a fraction of resources like CPU, memory, disk, network etc.
Following are the tasks of ApplicationManager:-
- Accepts submission of jobs by client.
- Negotaites first container for specific ApplicationMaster.
- Restarts the container after application failure.
Below are the responsibilities of ApplicationMaster
- Negotiates containers from Scheduler
- Tracking container status and monitoring its progress.
Yarn supports the concept of Resource Reservation via ReservationSystem. In this, a user can fix a number of resources for execution of a particular job over time and temporal constraints. The ReservationSystem makes sure that the resources are available to the job until its completion. It also performs admission control for reservation.
Yarn can scale beyond a few thousand nodes via Yarn Federation. YARN Federation allows to wire multiple sub-cluster into the single massive cluster. We can use many independent clusters together for a single large job. It can be used to achieve a large scale system.
Let us summarize how Hadoop works step by step:
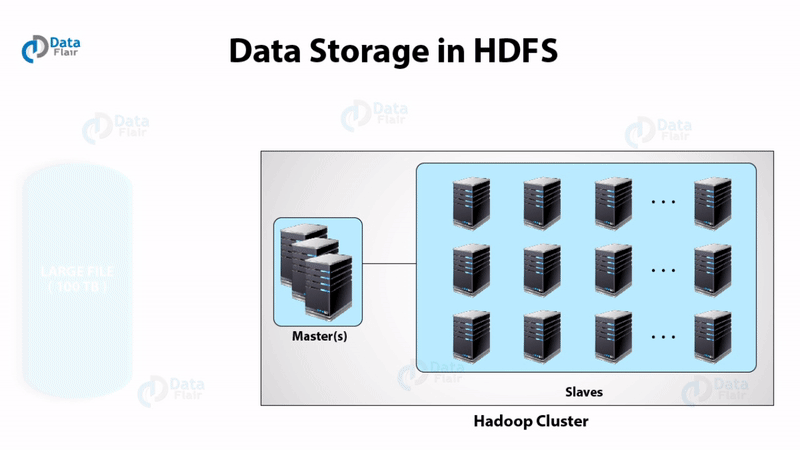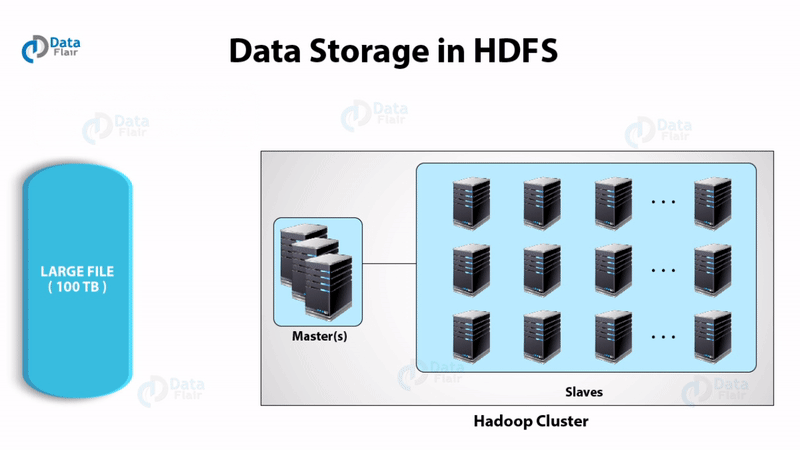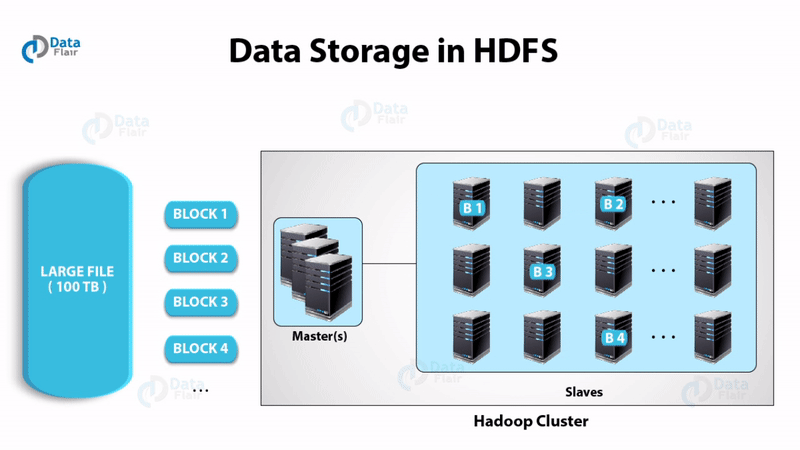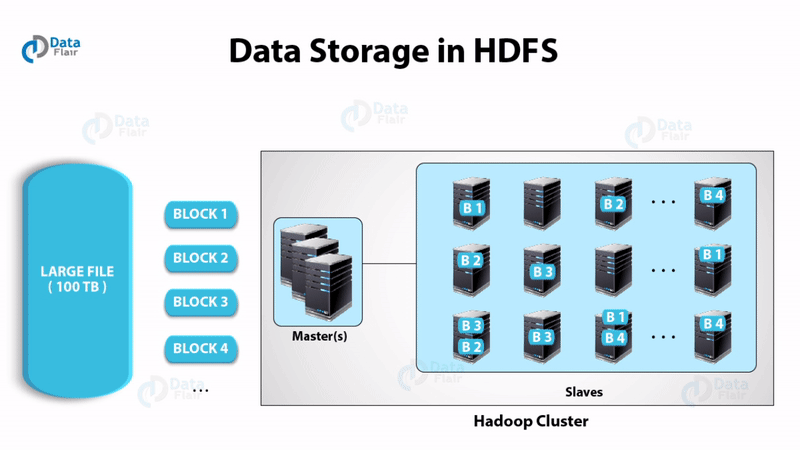
- Input data is broken into blocks of size 128 Mb and then blocks are moved to different nodes.
- Once all the blocks of the data are stored on data-nodes, the user can process the data.
- Resource Manager then schedules the program (submitted by the user) on individual nodes.
- Once all the nodes process the data, the output is written back to HDFS.
So, this was all on How Hadoop Works Tutorial.
Conclusion
In conclusion to How Hadoop Works, we can say, the client first submits the data and program. HDFS stores that data and MapReduce processes that data. So now when we have learned Hadoop introduction and How Hadoop works, let us now learn how to Install Hadoop on a single node and multi-node to move ahead in the technology.
Drop a comment if you like the tutorial or have any queries and feedback on ‘How Hadoop Works’ we will get back to you.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





I just want to point out that the fifth daemon (secondary namenode) is not a backup by any means as Hadoop does not support a backup for the master node. The secondary namenode only serves as a state serializer as it stores the state of the underlying file system to disk in case of namenode failures and never acts as a backup.
Good explanation.
Hi,
I would like to know if hadoop works only with a supplied mapreduce provided program written in python or java, or hadoop supply itself mapreduce programs out of the box??
Regards.
This simple methods of breaking down individual data elements is the fundamental for most emerging solutions of a data dependent elements.
Good overview but please fix grammatical errors. In parts its just unreadable.
NICE EXPLIANNATION