Distributed Cache in Hadoop – Most Comprehensive Guide
Explore the Hadoop Distributed Cache mechanism provided by the Hadoop MapReduce Framework.
In this article, we will study the Hadoop DistributedCache. The article explains what we mean by the Hadoop DistributedCache and the type of files cached by the Hadoop DistributedCache. The article also describes how Hadoop DistributedCache works, how to implement DistributedCache and the types of DistributedCache files. We will also see the advantages and disadvantages of Hadoop DistributedCache.
Let us now first start with an introduction to Hadoop DistributedCache.
What is Distributed Cache in Hadoop?
Side data is the read-only data needed by a job to perform processing on the primary datasets. The main challenge is to make this side data available to all the tasks running across the cluster efficiently.
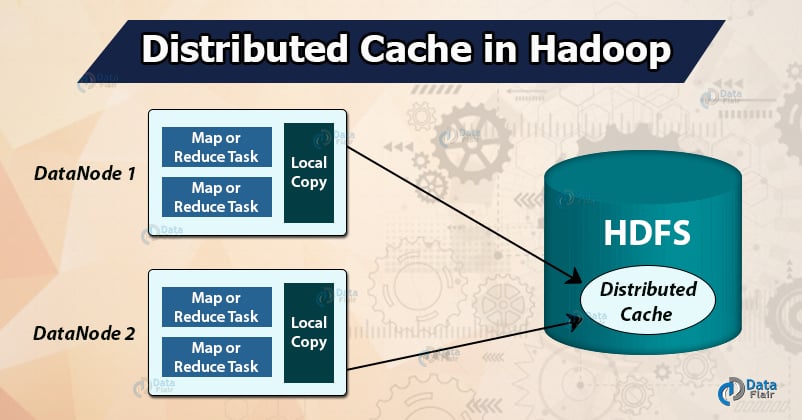
Hadoop DistributedCache is a mechanism provided by the Hadoop MapReduce Framework that offers a service for copying read-only files or archives or jar files to the worker nodes, before the execution of any tasks for the job on that node. Files get normally copied once per job to save the network bandwidth.
DistributedCache distributes read-only data/text files or archives, jars, etc.
How Hadoop DistributedCache works?
When we fire any job, Hadoop copies the files specified by the options -files, -archives, and -libjars to the HDFS. Before a task run, the YARN NodeManager copies the files from HDFS to a local disk, that is, cache, so that the task can access the files.
The file, at this point, gets tagged as localized. From the task’s point of view, the files are there linked from the tasks working directory.
Before launching, the files specified via -libjars were added to the task’s classpath.
Also, the YARN NodeManager maintains a reference count for the number of tasks using each file in the cache.
Before the task has run, it increments the file reference count by one. After the task has run, it decrements the file reference count by one.
Only when the count becomes 0, the file is eligible for deletion.
When nodes’ cache exceeds a specific size that is 10 GB by default, then to make room for new files, the files are deleted by using the least-recently-used policy.
We can change the size of the cache by setting the yarn.nodemanager.localizer.cache.target-size-mb configuration property.
How to implement Hadoop DistributedCache?
For implementing the DistributedCache, the applications specify the cached files via URLs in the form hdfs://in the Job.
The Hadoop DistributedCache presumes that the files specified through the URLs are present on the FileSystem at the path specified, and every node in the cluster has access permission to that file.
So for implementing the Hadoop DistributedCache, the application needs to make sure that:
- files should be specified via URL only ( hdfs://)
- files specified should be available.
The files or archives are distributed by setting the mapreduce.job.cache.{files | archives} property. If the files or archives which are to be distributed is more than one, then we can provide their paths separated by a comma.
The MapReduce framework will then copy the cache files on all the slave nodes before the execution of any tasks for the job on those nodes.
The process for implementing Hadoop DistributedCache is as follows:
1. Firstly, copy the required file to the Hadoop HDFS.
$ hadoop fs -copyFromLocal jar_file.jar /dataflair/jar_file.jar
2. Secondly, set up the application’s JobConf.
Configuration conf = getConf();
Job job = Job.getInstance(conf);
job.addCacheFile(new Path("hdfs://localhost:9000/dataflair/jar_file.jar").toUri());3. Use the cached files in the Mapper/Reducer.
URI[] files = context.getCacheFiles();
Types of DistributedCache Files
DistributedCache files are of two types that are private or public:
1. Private DistributedCache files
These files are:
- Cached in a local directory.
- Private to that user whose jobs need these files.
- Only the jobs and tasks of the specific user can use these files. It is not accessible by the jobs of other users.
- A DistributedCache file becomes private if it has no world read access, or the directory path where the file resides has no world access for lookup.
2. Public DistributedCache files
These files are :
- Cached in a global directory.
- Publicly visible to all users.
- The jobs and tasks of any user can use these files.
- A DistributedCache file becomes public if it has world-readable access, AND the directory path where the file resides has world executable access for lookup.
Do you know which service provides the automatic failover capability in HDFS?
Advantages of Hadoop DistributedCache
1. Distributes Complex data: The Hadoop DistributedCache can distribute complex data like jars and archives. The archive files such as zip, tgz, tar.gz files are un-archived at the worker nodes.
2. Track Modification Timestamp: The Hadoop DistributedCache tracks the modification timestamp of each cache file so that while the job is executing, no application or external factor should modify the cache file.
3. Consistent: Using the hashing algorithm, the cache engine always determines on which node a particular key-value pair resides. Thus, the cache cluster is always in a single state, which makes it consistent.
4. No Single Point of Failure: It runs as an independent unit across many nodes in the cluster. So, failure in any one DataNode doesn’t result in the failure of the entire cache.
Disadvantages of DistributedCache
Object Serialisation:
In Hadoop DistributedCache, objects need to be serialized. The major problem of DistributedCache lies in the serialization mechanism.
- Very slow – To inspect the type of information at runtime, it uses the Reflection technique, which is very slow as compared to the Pre-compiled code.
- Very Bulky – Serialisation is very bulky as it stores multiple data like class name, assembly, cluster details, and reference to other instances in member variables.
Summary
In short, we can say that DistributedCache is the facility provided by the MapReduce Framework, which distributes the files needed by the map/reduce jobs during task execution across the worker nodes. This decreases the latency. The article had explained how DistributedCache works. We had also seen how we could implement DistributedCache in our MapReduce program. The DistributeCache does not have Single Point of Failure, and it maintains data consistency as well.
Do you know How Hadoop works internally?
If you like this post or have any query in Hadoop Distributed Cache, do leave a comment.
Keep Learning!!
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




