Hadoop vs Cassandra – Which is Better| 15 Reasons to Learn
Placement-ready Courses: Enroll Now, Thank us Later!
Apache Cassandra Vs Hadoop
Today, we will take a look at Hadoop vs Cassandra. There is always a question occurs that which technology is the right choice between Hadoop vs Cassandra.
So, in this article, “Hadoop vs Cassandra” we will see the difference between Apache Hadoop and Cassandra. Although, to understand well we will start with an individual introduction of both in brief.
Apache Cassandra is based on a NoSQL database and suitable for high speed, online transactional data. On the other hand Hadoop concentrate on data warehousing and data lake use cases. It is a big data analytics system.
So, let’s start the Hadoop vs Cassandra.
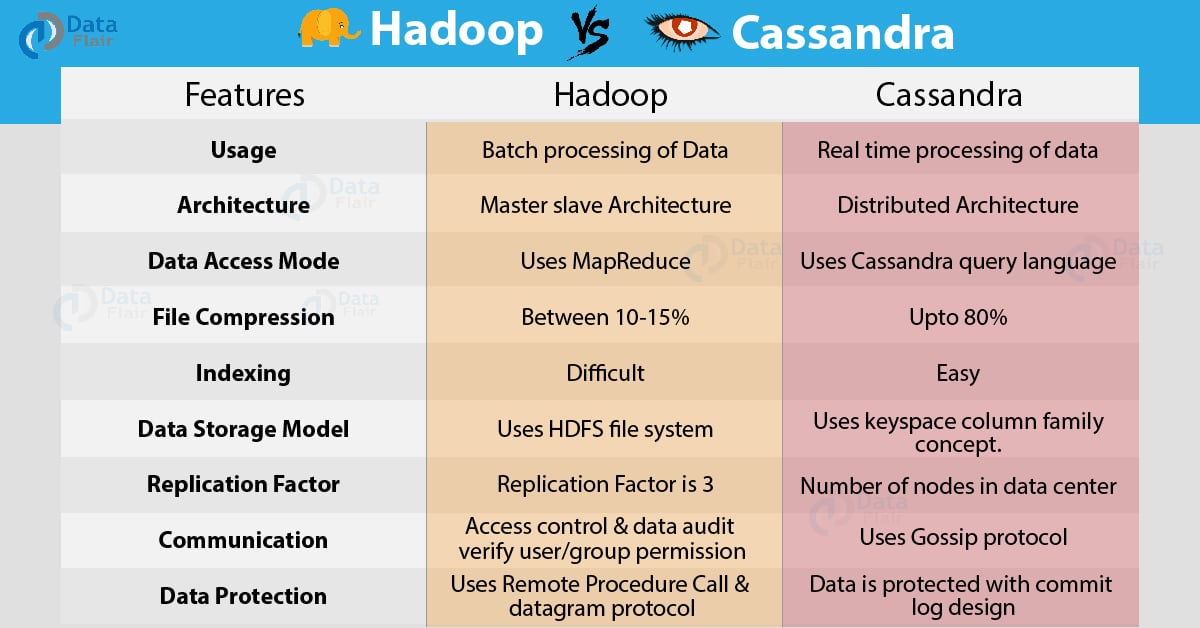
Difference Between Hadoop and Cassandra
We will see the Big Data Hadoop vs Cassandra difference by discussing the meaning of Hadoop and Cassandra:
a. What is Hadoop?
As we know an open-source software, especially, designed to handle parallel processing is what we call Hadoop. We also use it as a data warehouse for large volume data.
In other words, this is a framework that allows storing as well as processing big data in a distributed environment across clusters of computers by using simple programming models.
Basically, the main aim to design it is to scale up from single servers to thousands of machines. And, especially, to make each of them offering local computation as well as storage.
b. What is Cassandra?
Whereas, it is simply a NoSQL database, for the purpose of high speed, online transactional data. Well, its best feature is that it works without a single point of failure.
Moreover, it helps to keep the updated status of the surrounding nodes in the cluster with the help of the gossip protocol. There may be a time when one node goes down, at that time the other one takes its responsibility until the failed one is not fixed.
Although, when the nodes exchange the gossip, older information gets overwritten by a newer version of gossip, because all gossip messages possess a version associated with it.
In addition, it supports unstructured data along with a flexible schema.
Feature Wise Comparison of Hadoop vs Cassandra
Now, let’s begin the comparison of Cassandra Vs Hadoop:
- Supported Format
- Usage
- Working
- CAP Parameters
- Communication
- Architecture
- Data Access Mode
- Fault Tolerance
- Data Compression
- Data Protection
- Latency
- Indexing
- Data Flow
- Data Storage Model
- Replication Factor
a. Supported format
- Apache Hadoop
Hadoop handles several types of data such as – structured, semi-structured, unstructured or images.
- Cassandra
However, rather than Images, Cassandra handles almost all structured, semi-structured, unstructured datasets. In addition, we can say Cassandra is best to perform on a semi-structured dataset.
b. Usage
- Apache Hadoop
Especially, we use Hadoop for batch processing of data.
- Cassandra
Whereas, it is mostly used for real-time processing.
c. Work
- Apache Hadoop
Hadoop’s core is HDFS, which is a base for other analytical components especially for handling big data.
- Cassandra
Well, it works on top HDFS.
d. CAP Parameters(consistency, availability and partition tolerance )
- Apache Hadoop
It supports consistency and partition tolerance.
- Cassandra
But it supports availability and partition tolerance.
e. Communication
- Apache Hadoop
For communication among nodes in a cluster, Hadoop uses RPC/TCP and UDP.
- Cassandra
And, it uses gossip protocol, for communication between nodes. Basically, this protocol helps by broadcasting the node status to its peer nodes in the cluster.
f. Architecture
- Apache Hadoop
It has a master-slave architecture. Where master is Namenode and Slave is data node.
- Cassandra
But it has a distributed architecture. Although, here is a peer to peer communication between all the nodes.
g. Data Access Mode
- Apache Hadoop
Basically, to read/write, it uses map-reduce.
- Cassandra
Well, it uses Cassandra query language.
h. Fault tolerance
- Apache Hadoop
Everything goes for a toss if the master node goes down. Hence, we can say, Hadoop is not good with failure.
- Cassandra
But Cassandra is good with it, because when one node goes down, at that time the other one takes its responsibility until the failed one is not fixed.
i. Data Compression
- Apache Hadoop
It compresses files 10-15 % by using best available techniques.
- Cassandra
Whereas, it compresses files up to 80% even without any overhead.
j. Data Protection
- Apache Hadoop
Access control & Data audit, verify the appropriate user/group permission, in Hadoop.
- Cassandra
Whereas, in Cassandra, Data is protected with commit log design. Moreover, backup and restore mechanism (Build in security) plays a vital role here.
k. Latency
- Apache Hadoop
While it comes to Hadoop’s latency, its write latency is comparatively less than reading, due to the huge number of nodes.
- Cassandra
Its latency is less since it is based on NoSQL. It read/write functions are fast.
l. Indexing
- Apache Hadoop
It is difficult in Hadoop.
- Cassandra
In Cassandra, it is quite simple due to its data storage in a key-value pair.
m. Data Flow
- Apache Hadoop
Here, data is directly written to the data node.
- Cassandra
But here, data is written to memory first, in memory structure format that we call as mem-table. And, it is written to disk, once that is full.
n. Data Storage Model
- Apache Hadoop
While it comes to data storage, HDFS is the file system here. Basically, all Large files are broken into chunks and further get replicated to multiple nodes.
- Cassandra
However, to store data Cassandra uses a Keyspace column family concept. Basically, it offers primary as well as secondary indexes for the high availability of data.
o. Replication Factor
- Apache Hadoop
By default, Hadoop has a replication factor of 3.
- Cassandra
But in Cassandra, the number of nodes in a data center is the value of replication factor, by default.
So, this was all in Apache Hadoop vs Cassandra. Hope you liked our explanation.
Summary of Hadoop vs Cassandra
Although both Hadoop and Cassandra are potent big data technologies, they each offer unique advantages and applications. A distributed data processing platform called Hadoop was created for big data analysis and batch processing. It is frequently used for data warehousing and log analysis and is ideally suited for managing both organised and unstructured data. Contrarily, Cassandra is a distributed NoSQL database designed for high-velocity data storage and real-time data processing.
It is great at handling high-performance, high-velocity workloads, which makes it the best choice for applications that need to get and analyse data in real-time, including IoT data and user activity tracking. With Hadoop being better for batch processing and complicated analytical jobs and Cassandra being better for real-time, high-velocity data workloads, the decision between the two relies on the precise requirements of the data processing operations.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




