Hadoop Schedulers Tutorial – Job Scheduling in Hadoop
Explore the Hadoop scheduler and their different pluggable Scheduling Policies.
In this article, we will study Hadoop Scheduler in detail. The article begins by explaining what Hadoop Scheduler is. Then we will see the different types of Hadoop Schedulers like FIFO, FairScheduler, and CapacityScheduler along with their advantages and disadvantages.
Let us first start with an introduction to Hadoop Scheduler.
Introduction to Hadoop Scheduler
Prior to Hadoop 2, Hadoop MapReduce is a software framework for writing applications that process huge amounts of data (terabytes to petabytes) in-parallel on the large Hadoop cluster. This framework is responsible for scheduling tasks, monitoring them, and re-executes the failed task.
In Hadoop 2, a YARN called Yet Another Resource Negotiator was introduced. The basic idea behind the YARN introduction is to split the functionalities of resource management and job scheduling or monitoring into separate daemons that are ResorceManager, ApplicationMaster, and NodeManager.
ResorceManager is the master daemon that arbitrates resources among all the applications in the system. NodeManager is the slave daemon responsible for containers, monitoring their resource usage, and reporting the same to ResourceManager or Schedulers. ApplicationMaster negotiates resources from the ResourceManager and works with NodeManager in order to execute and monitor the task.
The ResourceManager has two main components that are Schedulers and ApplicationsManager.
Schedulers in YARN ResourceManager is a pure scheduler which is responsible for allocating resources to the various running applications.
It is not responsible for monitoring or tracking the status of an application. Also, the scheduler does not guarantee about restarting the tasks that are failed either due to hardware failure or application failure.
Confused with YARN? Refer Hadoop YARN architecture to learn YARN in detail.
The scheduler performs scheduling based on the resource requirements of the applications.
It has some pluggable policies that are responsible for partitioning the cluster resources among the various queues, applications, etc.
The FIFO Scheduler, CapacityScheduler, and FairScheduler are such pluggable policies that are responsible for allocating resources to the applications.
Let us now study each of these Schedulers in detail.
TYPES OF HADOOP SCHEDULER
1. FIFO Scheduler
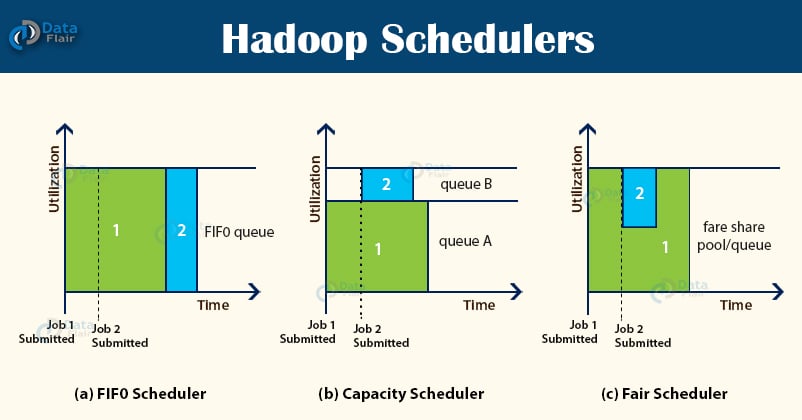
First In First Out is the default scheduling policy used in Hadoop. FIFO Scheduler gives more preferences to the application coming first than those coming later. It places the applications in a queue and executes them in the order of their submission (first in, first out).
Here, irrespective of the size and priority, the request for the first application in the queue are allocated first. Once the first application request is satisfied, then only the next application in the queue is served.
Advantage:
- It is simple to understand and doesn’t need any configuration.
- Jobs are executed in the order of their submission.
Disadvantage:
- It is not suitable for shared clusters. If the large application comes before the shorter one, then the large application will use all the resources in the cluster, and the shorter application has to wait for its turn. This leads to starvation.
- It does not take into account the balance of resource allocation between the long applications and short applications.
2. Capacity Scheduler
The CapacityScheduler allows multiple-tenants to securely share a large Hadoop cluster. It is designed to run Hadoop applications in a shared, multi-tenant cluster while maximizing the throughput and the utilization of the cluster.
It supports hierarchical queues to reflect the structure of organizations or groups that utilizes the cluster resources. A queue hierarchy contains three types of queues that are root, parent, and leaf.
The root queue represents the cluster itself, parent queue represents organization/group or sub-organization/sub-group, and the leaf accepts application submission.
The Capacity Scheduler allows the sharing of the large cluster while giving capacity guarantees to each organization by allocating a fraction of cluster resources to each queue.
Also, when there is a demand for the free resources that are available on the queue who has completed its task, by the queues running below capacity, then these resources will be assigned to the applications on queues running below capacity. This provides elasticity for the organization in a cost-effective manner.
Apart from it, the CapacityScheduler provides a comprehensive set of limits to ensure that a single application/user/queue cannot use a disproportionate amount of resources in the cluster.
To ensure fairness and stability, it also provides limits on initialized and pending apps from a single user and queue.
Advantages:
- It maximizes the utilization of resources and throughput in the Hadoop cluster.
- Provides elasticity for groups or organizations in a cost-effective manner.
- It also gives capacity guarantees and safeguards to the organization utilizing cluster.
Disadvantage:
- It is complex amongst the other scheduler.
3. Fair Scheduler
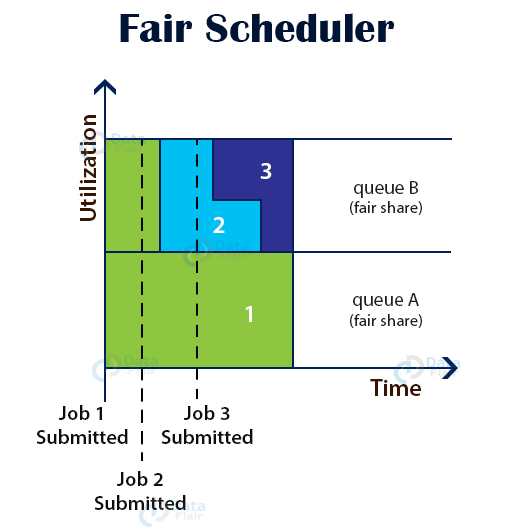
FairScheduler allows YARN applications to fairly share resources in large Hadoop clusters. With FairScheduler, there is no need for reserving a set amount of capacity because it will dynamically balance resources between all running applications.
It assigns resources to applications in such a way that all applications get, on average, an equal amount of resources over time.
The FairScheduler, by default, takes scheduling fairness decisions only on the basis of memory. We can configure it to schedule with both memory and CPU.
When the single application is running, then that app uses the entire cluster resources. When other applications are submitted, the free up resources are assigned to the new apps so that every app eventually gets roughly the same amount of resources. FairScheduler enables short apps to finish in a reasonable time without starving the long-lived apps.
Similar to CapacityScheduler, the FairScheduler supports hierarchical queue to reflect the structure of the long shared cluster.
Apart from fair scheduling, the FairScheduler allows for assigning minimum shares to queues for ensuring that certain users, production, or group applications always get sufficient resources. When an app is present in the queue, then the app gets its minimum share, but when the queue doesn’t need its full guaranteed share, then the excess share is split between other running applications.
Advantages:
- It provides a reasonable way to share the Hadoop Cluster between the number of users.
- Also, the FairScheduler can work with app priorities where the priorities are used as weights in determining the fraction of the total resources that each application should get.
Disadvantage:
- It requires configuration.
Summary
I hope after reading this article, you understand the different options of pluggable scheduling policies like FIFO, FairScheduler, and CapacityScheduler provided by Hadoop YARN ResourceManager for scheduling resources amongst the multiple applications running in the Hadoop cluster.
Having any confusion in Hadoop Schedulers?
Ask DataFlair experts in the comment section below.
Keep learning!!
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





In capacity scheduler queue is using resources more then minimum assigned when other queue resources are free. When submitted job in other queue, their resources used by other queue jobs will be killed right away? or wait to finish their job?