Hadoop Mapper – 4 Steps Learning to MapReduce Mapper
1. Hadoop Mapper Tutorial – Objective
Mapper task is the first phase of processing that processes each input record (from RecordReader) and generates an intermediate key-value pair. Hadoop Mapper store intermediate-output on the local disk. In this Hadoop mapper tutorial, we will try to answer what is a MapReduce Mapper how to generate key-value pair in Hadoop, what is InputSplit and RecordReader in Hadoop, how mapper works in Hadoop.
We will also discuss the number of mapper in Hadoop MapReduce for running any program and how to calculate the number of Hadoop mappers required for a given data. After this tutorial you can refer our tutorial on MapReduce Reducer to gain complete insights on both mapper and reducer in Hadoop. It is really fun to understand mapper and reducer in Hadoop.
We will also discuss the number of mapper in Hadoop MapReduce for running any program and how to calculate the number of mappers required for a given data.
Hadoop Mapper – 4 Steps Learning to MapReduce Mapper
2. What is Hadoop Mapper?
Hadoop Mapper task processes each input record and it generates a new <key, value> pairs. The <key, value> pairs can be completely different from the input pair. In mapper task, the output is the full collection of all these <key, value> pairs. Before writing the output for each mapper task, partitioning of output take place on the basis of the key and then sorting is done. This partitioning specifies that all the values for each key are grouped together.
MapReduce frame generates one map task for each InputSplit (we will discuss it below.) generated by the InputFormat for the job.
Mapper only understands <key, value> pairs of data, so before passing data to the mapper, data should be first converted into <key, value> pairs.
Read: What is MapReduce?
3. How is key value pair generated in Hadoop?
Let us now discuss the key-value pair generation in Hadoop.
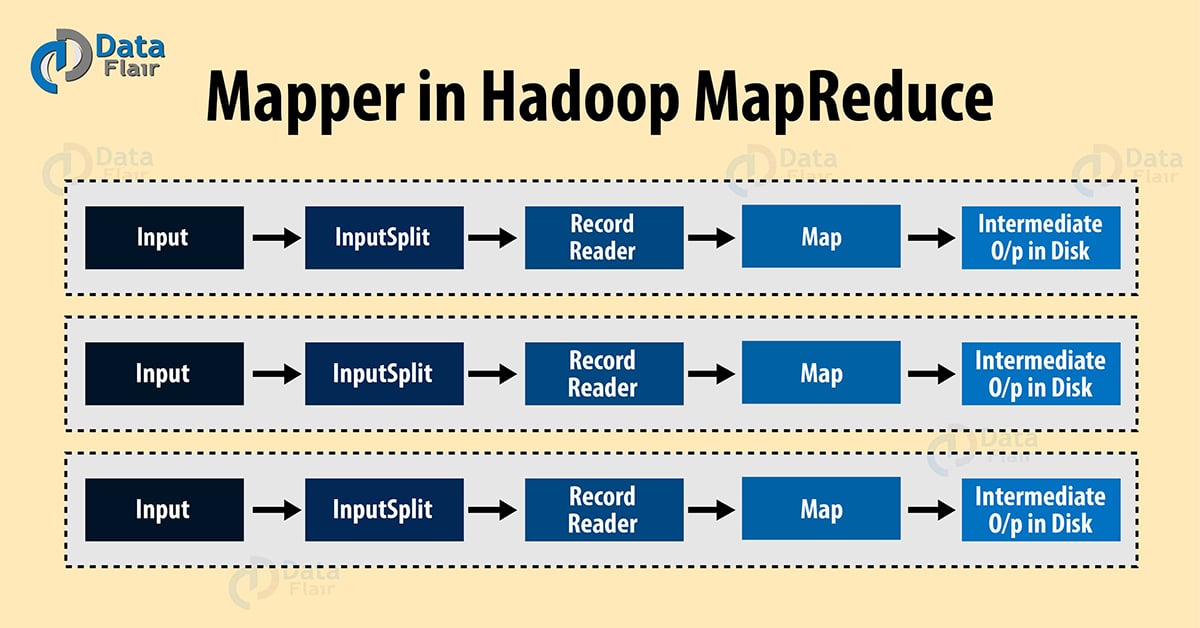
- InputSplit – It is the logical representation of data. It describes a unit of work that contains a single map task in a MapReduce program. Learn about InputSplit in detail.
- RecordReader – It communicates with the InputSplit and it converts the data into key-value pairs suitable for reading by the Mapper. By default, it uses TextInputFormat for converting data into the key-value pair. RecordReader communicates with the Inputsplit until the file reading is not completed. Learn about RecordReader in detail.
Read Reducer in Hadoop to have the knowledge of both mapper and reducer in hadoop.
4. How does Hadoop Mapper work?
Let us now see the mapper process in Hadoop.
InputSplits converts the physical representation of the block into logical for the Hadoop mapper. To read the 100MB file, two InputSlits are required. One InputSplit is created for each block and one RecordReader and one mapper are created for each InputSplit.
InputSpits do not always depend on the number of blocks, we can customize the number of splits for a particular file by setting mapred.max.split.size property during job execution.
RecordReader’s responsibility is to keep reading/converting data into key-value pairs until the end of the file. Byte offset (unique number) is assigned to each line present in the file by RecordReader. Further, this key-value pair is sent to the mapper. The output of the mapper program is called as intermediate data (key-value pairs which are understandable to reduce).
Read: MapReduce DataFlow
5. How many map tasks in Hadoop?
In this section of this Hadoop mapper tutorial, we are going to discuss the number of mapper in Hadoop MapReduce for running any program and how to calculate the number of mappers required for a given data?
The total number of blocks of the input files handles the number of map tasks in a program. For maps, the right level of parallelism is around 10-100 maps/node, although for CPU-light map tasks it has been set up to 300 maps. Since task setup takes some time, so it’s better if the maps take at least a minute to execute.
For example, if we have a block size of 128 MB and we expect 10TB of input data, we will have 82,000 maps. Thus, the InputFormat determines the number of maps.
Hence, No. of Mapper= {(total data size)/ (input split size)}
For example, if data size is 1 TB and InputSplit size is 100 MB then,
No. of Mapper= (1000*1000)/100= 10,000
Read: Reducer in MapReduce
6. Hadoop Mapper – Conclusion
In conclusion to the Hadoop Mapper tutorial, Mapper takes the set of key-value pair generates by InputSplit and RecordReader and generate intermediate key-value pairs. Hence, in this phase, we specify all the complex logic/business rules/costly code. This was all about MapReduce Mapper. In our Next blog, we will discuss the next Phase- Hadoop Reducer in detail to understand both mapper and reducer in Hadoop.
See Also-
If you like this blog or have any query related to Hadoop Mapper, so please let us know by leaving a comment. Hope we will solve them.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





super tutorial ..very helpful.could you please provide video tutorial with hand on experiance
Mapper count formula is incorrect in the article.
Actually formula is below.
Number of mapper = (Total data size)/ (Block size)
Block Size is ideally 128 MB.
Note: We will not have InputSplit size as it just a logical partition.
Number of mapper depend on input spilt default input spilt is block size , we can customize the number of splits using “mapred.max.split.size” property configuration in mared-ste.xml file.