How Hadoop automatically triggers NameNode Failover?
Want to study how Hadoop triggers the failover from active NameNode to Standby NameNode?
In the Hadoop HDFS NameNode High Availability article, we had seen how the High availability feature introduced in Hadoop 2 solves the NameNode Single Point Of Failure problem. That article describes the manual failover, where when the active node fails, then the standby node takes over the responsibility of the active NameNode. But in manual failover, the system will not automatically trigger the failover from active NameNode to the standby NameNode.
In this article, we will study Hadoop Automatic Failover. We will first see what failover is? And different types of failover. The main objective of this article is to explain how HDFS achieves high availability through automatic failover. The article explains the components, that is, ZooKeeper quorum and the ZKFailoverController, deployed on Hadoop HDFS for achieving automatic failover.
Let us now first see what is Failover.
What is Failover And Types of Failover
Failover refers to the procedure of transferring control to a redundant or standby system upon the failure of the previously active system.
There are two types of failover, that is, Graceful Failover and Automatic Failover.
1. Graceful Failover
Graceful Failover is initiated by the Administrator manually. In Graceful Failover, even when the active NameNode fails, the system will not automatically trigger the failover from active NameNode to standby Namenode. The Administrator initiates Graceful Failover, for example, in the case of routine maintenance.
2. Automatic Failover
In Automatic Failover, the system automatically triggers the failover from active NameNode to the Standby NameNode.
Introduction to Hadoop NameNode Automatic Failover
Hadoop Automatic Failover ensures Hadoop HDFS NameNode High Availability. It automatically triggers the failover from active Namenode to the standby NameNode. The default implementation uses ZooKeeper to achieve Automatic Failover.
The two new components are deployed to Hadoop HDFS for implementing Automatic Failover. These two components are-
- ZooKeeper quorum
- ZKFailoverController process(ZKFC)
Let us now study each of these components in detail.
1. ZooKeeper quorum
Apache ZooKeeper quorum is a highly available service for maintaining little amounts of coordination data. It notifies the clients about the changes in that data. It monitors clients for the failures.
The HDFS implementation of automatic failover depends on ZooKeeper for the following things:
a. Failure detection
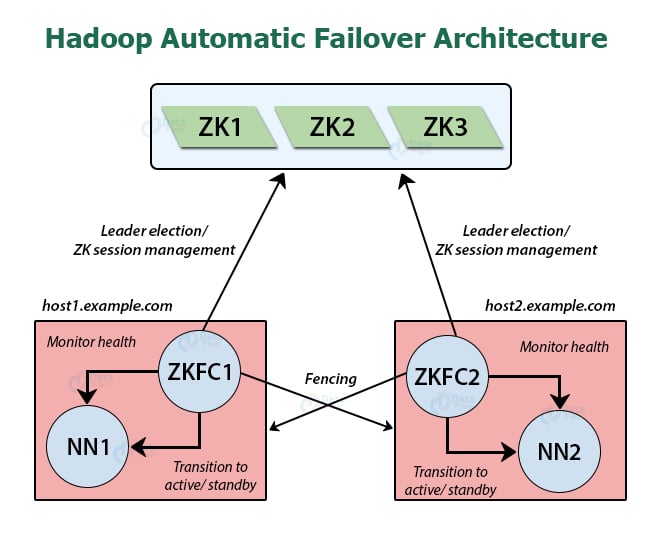
Each NameNode machine in the Hadoop cluster maintains a persistent session in the ZooKeeper. If any of the machines crashes, then the ZooKeeper session maintained will get expire—zooKeeper than reveal to all the other NameNodes to start the failover process.
b. Active NameNode election
To exclusively select the active NameNode, ZooKeeper provides a simple mechanism. In the case of active NameNode failure, another standby NameNode may take the special exclusive lock in the ZooKeeper, stating that it should become the next active NameNode.
2. ZKFailoverController(ZKFC)
The ZKFC is the ZooKeeper client, who is also responsible for managing and monitoring the NameNode state. ZKFC runs on every machine on the Hadoop cluster, which is running NameNode.
It is responsible for:
- Health monitoring – ZKFC is accountable for health monitoring. It pings its local NameNode with health-check commands periodically. As long as the NameNode responds with a healthy status timely, it considers the NameNode as healthy. In the case, if the NameNode got crashed, froze, or entered an unhealthy state, then it marks the NameNode as unhealthy.
- ZooKeeper session management – It is also responsible for the session management with ZooKeeper. The ZKFC maintains a session open in the ZooKeeper when the local Namenode is healthy. Also, if the Local NameNode is the active NameNode, then with the session, it also holds a special lock “znode”. This lock uses ZooKeeper support for the ”ephemeral” nodes. Thus, if the session gets expires, the lock node will be deleted automatically.
- ZooKeeper-based election – When the local Namenode is healthy and ZKFC founds that no other NameNode acquires the lock “znode”, then it will try by itself to acquire the lock. If it gets successful in obtaining the lock, then ZKFC has won the election, and now it is responsible for running the failover to make it’s local NameNode active. The failover process run by the ZKFC is similar to the failover process run by the manual failover described in the NameNode High Availability article.
Configuring automatic failover
When the cluster is running, it is not possible to transfer from a manual failover setup to an automatic failover setup. So, before configuring automatic failover, the Hadoop cluster should be shut down.
For configuring automatic failover, we need to add two new parameters.
1. In hdfs-site.xml file, add:
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
This parameter specifies that the cluster is now set for automatic failover.
2. In core-site.xml file, add:
<property> <name>ha.zookeeper.quorum</name> <value>zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181</value> </property>
This parameter lists the host-port pairs which are running the ZooKeeper service.
After adding the configuration keys, we have to initialize required state in ZooKeeper using below command from one of the NameNode hosts:
[hdfs]$ $HADOOP_HOME/bin/zkfc -formatZK
It will create a lock “znode” in the ZooKeeper inside which the automatic failover system stores its data.
Now, start the cluster with start-dfs.sh that will automatically start a ZKFC daemon on any machine that runs a NameNode.
ZKFCs now automatically selects one of the NameNodes to become active.
Summary
In this article, we have studied the automatic failover that automatically triggers the NameNode failure. The two new components that are ZooKeeper quorum and ZKFCAutomatic failover are deployed on HDFS for implementing automatic failure. The article also describes the steps for configuring Automatic failure.
Now its time to explore Top 50 Hadoop Interview Questions and Answers.
If you like this post or have any query about Hadoop NameNode Automatic Failover, so please leave a comment.
Keep Learning!!
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





useful article
Tell me about what happens when znode gets deleted… I mean Failover will happen or not… N if not happen… Then why ( reason)