What is New in Hadoop 3? Explore the Unique Hadoop 3 Features
The release of Hadoop 3.x is the next big milestone in the line of Hadoop releases. Many people have a question in mind about what feature enhancement does Hadoop 3.x gives over Hadoop 2.x. So in this blog, we will take a look at what is new in Hadoop 3 and how it differs from the old versions.
What is New in Hadoop 3? Explore the Unique Hadoop 3 Features
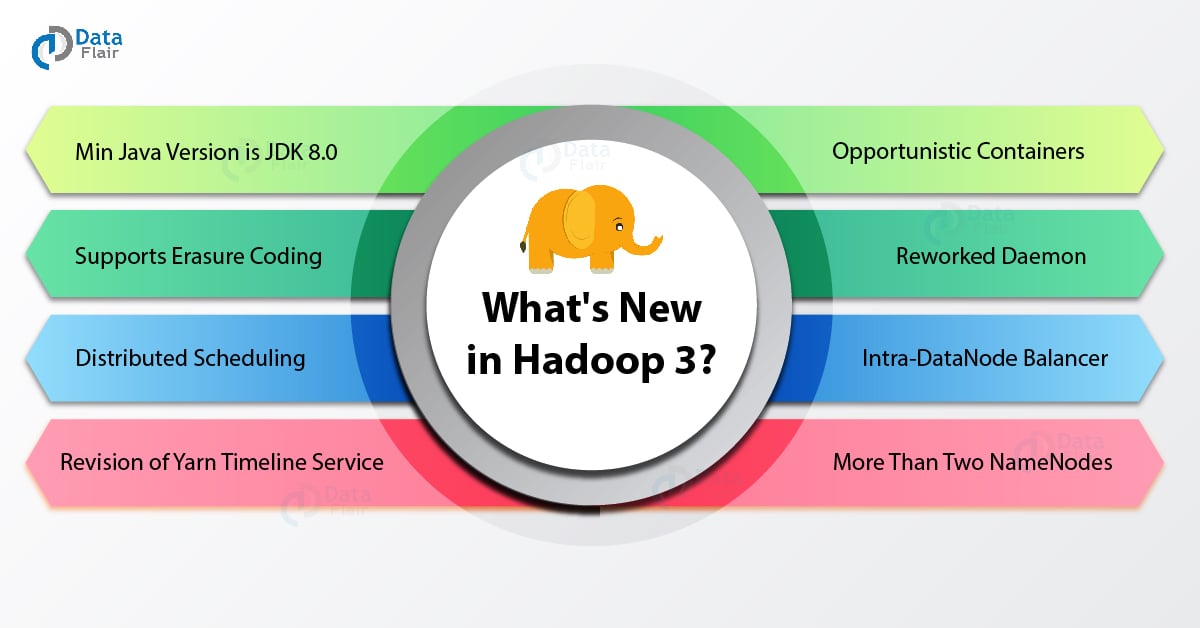
What’s New in Hadoop 3?
Below are the 10 changes which are done in Hadoop 3 and that makes it unique and fast. Have a look the What’s new in Hadoop 3.x –
You must check – The Essential Guide to Learn Hadoop 3
1. The minimum version of Java supported in Hadoop 3.0 is JDK 8.0
They have compiled all the Hadoop jar files using Java 8 run time version. The user now has to install Java 8 to use Hadoop 3.0. And user having JDK 7 has to upgrade it to JDK 8.
2. HDFS Supports Erasure Coding
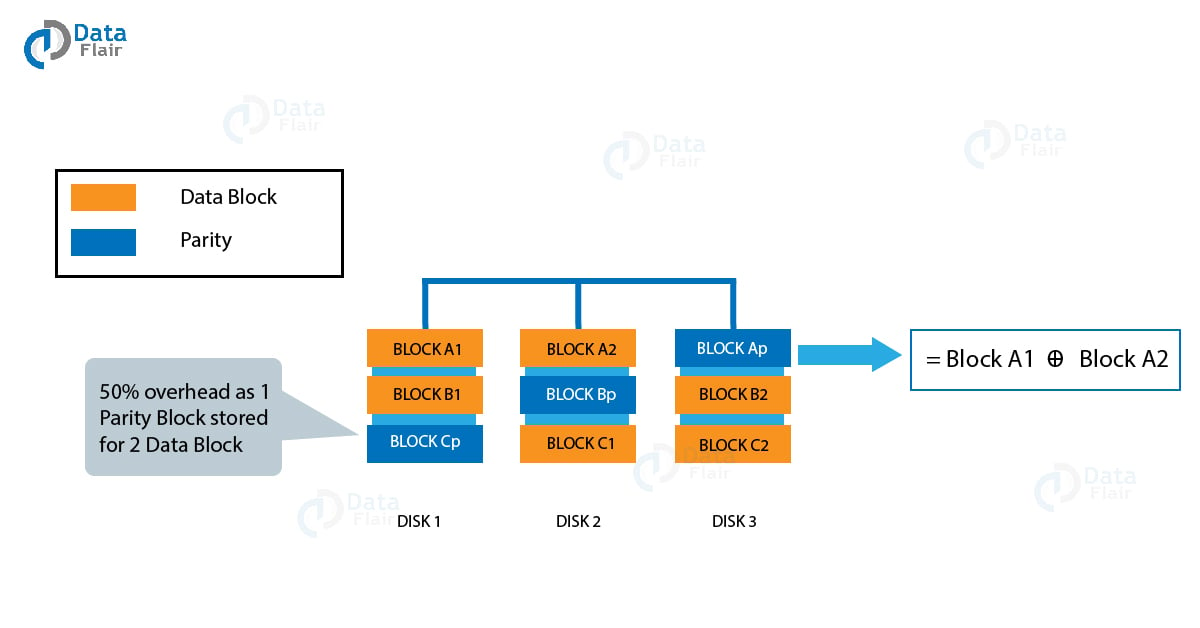
Hadoop 3.x uses erasure coding for providing fault tolerance. Hadoop 2.x uses a replication technique to provide the same level of fault tolerance. Let us explore the difference between the two.
First, we will look at replication. Let us take the default replication factor of 3. In this, for 6 blocks we have to store a total of 6*3 i.e. 18 blocks. For every block replicated the storage overhead is 100%. Hence in our case, the storage overhead will be 200%.
Let us see what happens in Erasure Coding. For 6 blocks, 3 parity blocks get calculated. We call this process as encoding. Now whenever a block gets missing or corrupted, it gets calculated from the remaining blocks and parity blocks. We call this process as decoding. In this case, we have a total of 9 blocks stored for 6 blocks making 50% storage overhead. Hence we can achieve the same amount of fault tolerance with much lesser storage. But there always overhead in terms of CPU and network for the process of encoding and decoding. Thus it uses for rarely access data.
Recommended Reading – Hadoop Master-Slave Architecture
3. YARN Timeline Service v.2
Yarn Timeline Service is new in Hadoop 3. Timeline server is responsible for storage and retrieval of the application’s current and historical information. This information is of two types –
Generic information of the completed application
- Name of the queue
- User information
- Number of attempts per application
- Information about containers which ran for each attempt
- Generic data stored by ResourceManager about a completed application which is accessed by web UI.
Per framework information about running and completed application
- Number of map tasks
- Number of reduce task
- Counters
- Information published by application developers to TimeLine Server via Timeline client.
This data gets queried by REST API for rendering by application or framework specific UI.
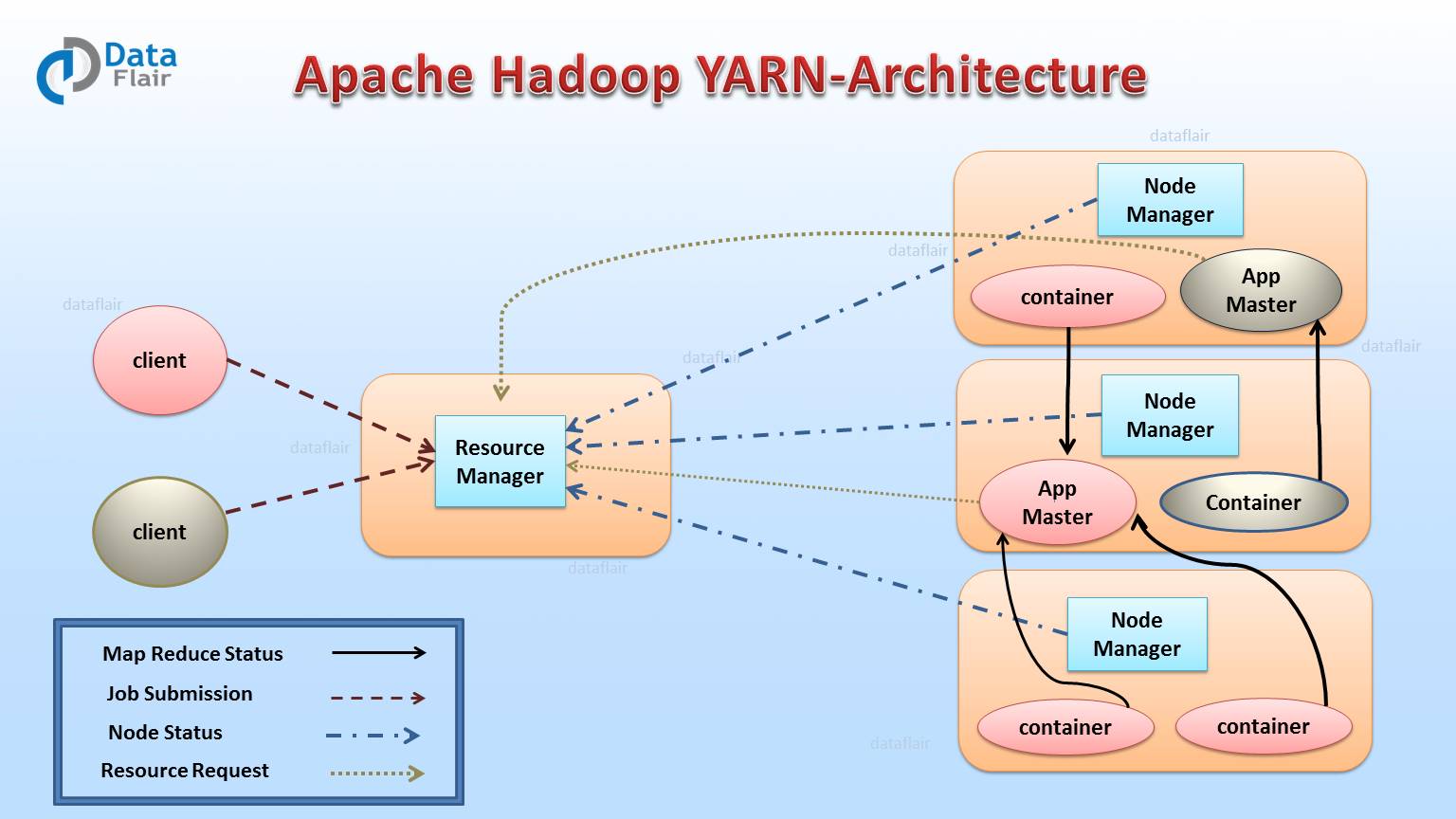
The TimeLine server v.2 addresses major shortcomings in version v.1. One of the issues is scalability. The TimeLine server v.1 has a single instance of reader/writer and storage. It is not scalable beyond a few numbers of nodes. Whereas in version v.2 Timeline server has a distributed writer architecture and scalable backend storage. It separates collection (writer) of data from serving (read) of data. Also, it uses one collector per YARN application. It has a reader as a separate instance which servers query request via REST API. Timeline server v.2 uses HBase for storage which can get scaled to huge size giving good response time for reads and writes.
4. Support for Opportunistic Containers and Distributed Scheduling
Hadoop 3 has introduced the concept of execution type. If there are no resources available at the moment then these containers wait at the NodeManager. Opportunistic containers have low priority than Guaranteed containers. If suppose Guaranteed containers arrive in the middle of the execution of opportunistic containers then later gets preempted. This happens to make room for Guaranteed containers.
5. Support for More Than Two NameNodes
Till now Hadoop supported single active NameNode and single standby NameNode. Having edits replicated to three journal nodes, this architecture allowed for the failure of one NameNode.
But some situation requires a high level of fault tolerance. By configuring five journal nodes we can have a system of three NameNodes. Such a system would tolerate the failure of two NameNodes. Thus by introducing support for more than two NameNode Hadoop 3.0 has made the system more highly available.
6. Default Ports of Multiple Services Changes
Previous to Hadoop 3.0 many Hadoop services had their default port in Linux ephemeral port range (32768-61000). Due to this, many times these services would fail to bind at startup. As they would conflict with other application.
They have moved the default port of these services out of ephemeral range. The services include NameNode, Secondary NameNode, DataNode, and KeyManagementServer.
7. Intra-DataNode Balancer
A DataNode Manges many disks. During a write operation, these disks get filled evenly. But when we add or remove the disk it results in a significant skew. The HDFS balancer addresses internode data skew and not intra node.
Intra-node balancer addresses this situation. The CLI – hdfs diskbalancer invokes this balancer.
8. Daemon and Task Heap Management Reworked
There are a number of changes in the Heap management of daemons and Map-Reduce tasks:
There are new ways to configure daemon heap sizes. The system auto-tunes based on the memory of the host. HADOOP_HEAPSIZE variable is no longer used. In its place, we have HEAP_MAX_SIZE and HEAP_MIN_SIZE variables. Also, they have removed the internal variable JAVA_HEAP_SIZE . They have also removed default heap sizes which allows for auto-tuning by JVM. All the variables of global and daemon heap size support units. If the variable is only a number then it expects the size to be in megabytes. Also, if you want to enable the old default then configure HADOOP_HEAPSIZE_MAX in hadoop-env.sh.
If the value for mapreduce.map/reduce.memory.mb is set to the default of -1. Then it will automatically infer the value from Xmx variable specified for mapreduce.map/reduce.java.opts. Xmx is nothing but heap size value system property. This reverse is also possible. Suppose Xmx value is not specified for mapreduce.map/reduce.java.opts keys. The system derives its value from mapredcue.map/reduce.memory.mb keys. If we don’t specify either value then the default is 1024MB. For configuration and job code which specify this value explicitly will not get affected.
Have a look at Hadoop Ecosystem and its Components
9. Generalization of Yarn Resource Model
They have generalized the Yarn resource model to include user-defined resources apart from CPU and memory. These user-defined resources can be software licenses, GPU or locally attached storage. Yarn tasks gets scheduled on the basis of these resources.
We can extend the Yarn resource model to include arbitrary “countable” resources. A countable resource is one which gets consumed by the container and the system releases it after completion. Both CPU and memory are countable resources. Likewise, GPUs or Graphics Processing Unit and software licenses are countable resources too. Yarn tracks CPU and memory for each node, application, and queue by default. Yarn can extend to track other user-defined countable resources like GPUs and software licenses. The integration of GPUs with containers has enhanced the performance of Data Science and AI use cases.
10. Consistency and Metadata Caching for S3A Client
S3A client of now has the capability to store metadata for files and directories in a fast and consistent way. It does this by using a DynamoDB table. We can refer to this new feature as S3GUARD. It caches the directory information so that S3Aclient can get faster lookups. Also, it provides resilience to inconsistencies between S3 list operations and status of the object. When the files get created using S3GUARD we can always find it. S3GUARD is experimental and we can consider it as unstable.
So, we have explored many new features of Hadoop 3 that makes it unique and popular.
Summary
As we have progressed along different versions of Hadoop, it gets better and better. The developers have incorporated many changes to fix bugs, make it more user-friendly and give it enhanced features. The changes made in default ports of various Hadoop services has made it more convenient to use. Hadoop includes various feature enhancements like erasure coding, the introduction of timeline service v.2, adoption of the intra-node balancer and so on. These changes have increased the chances of use of Hadoop by the industry. You must read top Hadoop questions related to the latest version of Hadoop.
Share your feedback of reading what’s new in Hadoop 3 via comments.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





i have 3 blocks size is 4oomb(for both 3 blocks), in erasure coding parity x,y,z are data cell and parity bit is being calculated for that data cells then what is the size of the parity bit. For my assumption it is 200 MB right. why because the data memory consumption is reduced from 200% to 50% (from hadoop 2.x to hadoop 3.x)
Nice