Hadoop vs MongoDB – 7 Reasons to Know Which is Better for Big Data?
Job-ready Online Courses: Click for Success - Start Now!
Hope, you are enjoying MongoDB tutorials. Today, we will discuss a trending question Hadoop Vs MongoDB: Which is a better tool for Big Data?
Today, all the industries, such as retail, healthcare, telecom, social media are generating a tremendous amount of data. By the year 2020, the data available will reach 44 zettabytes.
CAP Theorem
CAP Theorem states that distributed computing cannot achieve simultaneous Consistency, Availability, and Partition Tolerance while processing data. This theory can be related to Big Data, as it helps visualize bottlenecks that any solution will reach; only two goals can be achieved by the system.
So, when the CAP Theorem’s “pick two” methodology is being taken into consideration, the choice is really about picking the two options that the platform will be more capable of handling.
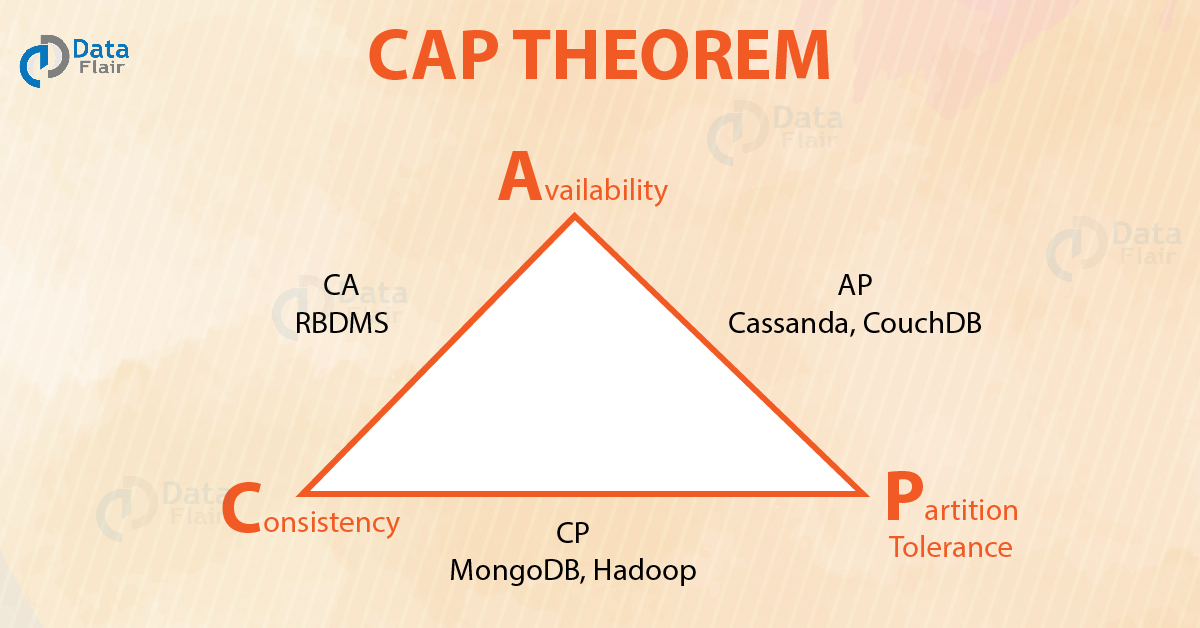
Traditional RDBMS provide consistency and availability but fall short on partition tolerance. Big Data provides either partition tolerance and consistency or availability and partition tolerance.
Hadoop vs MongoDB
Let’s start the comparison between Hadoop and MongoDB for Big Data:
a. What is MongoDB?
MongoDB was developed by 10 gen company in 2007 as a cloud-based app engine, which was intended to run assorted software and services. They had developed Babble(the app engine) and MongoDB(the database).
The idea didn’t work properly so they released MongoDB as open source. We can consider MongoDB as a Big data solution, it’s worth noting that it’s really a general-purpose platform, design to replace or enhance existing RDBMS systems, giving it a healthy variety of use cases.
Working of MongoDB
As MongoDB is document-oriented database management system it stores data in collections. Here different data fields can be queried once, versus multiple queries required by RDBMS’ that allocate data across multiple tables in columns and rows.
We can deploy MongoDB on either Windows or Linux. But as we consider MongoDB for real-time low latency projects Linux is an ideal choice for that point.
Benefits of MongoDB for Big Data
MongoDB’s greatest strength is its robustness, capable of far more flexibility than Hadoop, including potential replacement of existing RDBMS. Also, MongoDB is inherently better at handling real-time data analytics.
Due to readily available data also it is capable of client-side data delivery, which is not as common with Hadoop configurations. One more strength of MongoDB is its geospatial indexing abilities, making an ideal use case for real-time geospatial analysis.
Limitations of MongoDB for Big Data
When we are discussing Hadoop vs MongoDb, the limitations of Mongo are must: MongoDB is subject to most criticism because it tries to be so many different things, although it seems to have just as much approval. A major issue with MongoDB is fault tolerance, which can cause data loss.
Lock constraints, poor integration with RDBMS and many more are the additional complaints against MongoDB. MongoDB also can only consume data in CSV or JSON formats, which may require additional data transformation.
Up to now, we only discuss MongoDB for Hadoop vs MongoDB. Now, its time to disclose the Hadoop.
b. What is Hadoop?
Hadoop was an open source project from starting only. It was originally stemmed from a project called Nutch, an open-source web crawler created in 2002. After that in 2003, Google released a white paper on its Distributed File System(DFS) and Nutch referred same and developed its NDFS.
After that in 2004 Google introduced the concept of MapReduce which was adopted by Nutch in 2005. Hadoop development was officially started in 2006.
Hadoop became a platform for processing mass amounts of data in parallel across clusters of commodity hardware. It has become synonymous to Big Data, as it is the most popular Big Data tool.
Working of Apache Hadoop
Hadoop has two primary components: the Hadoop Distributed File System(HDFS) and MapReduce. Secondary components include Pig, Hive, HBase, Oozie, Sqoop, and Flume. Hadoop’s HBase database accomplishes horizontal scalability through database sharding just like MongoDB.
Hadoop runs on clusters of commodity hardware. HDFS divides the file into smaller chunks and stores them distributedly over the cluster. MapReduce processes the data which is stored distributedly over the cluster.
MapReduce utilizes the power of distributed computing, where multiple nodes work in parallel to complete the task.
Strength Related to Big Data Use Cases
On the other hand, Hadoop is more suitable at batch processing and long-running ETL jobs and analysis. The biggest strength of Hadoop is that it was built for Big Data, whereas MongoDB became an option over time.
While Hadoop may not handle real-time data as well as MongoDB, ad-hoc SQL-like queries can be run with Hive, which is touted as being effective as a query language than JSON/BSON.
Hadoop’s MapReduce implementation is also much more efficient than MongoDB’s, and it is an ideal choice for analyzing massive amounts of data. Finally, Hadoop accepts data in any format, which eliminates data transformation involved with the data processing.
Weakness Related to Big Data Use Cases
Difference Between Hadoop and MongoDB
This is a concise way of Hadoop Vs MongoDB:
i. Language
Hadoop is written in Java Programming.
On the other hand, C++ used in MongoDB.
ii. Open Source
Hadoop is open source.
MongoDB is open source.
iii. Scalability
Hadoop is scalable.
MongoDB is scalable.
iv. NoSQL
Hadoop does not support NoSQL, though HBase on the top of Hadoop can support NoSQL
MongoDB supports NoSQL.
v. Data Structure
Hadoop has a flexible data structure.
vi. Cost
Hadoop is costlier than MongoDB as it is a collection of software.
MongoDB is cost-effective as it is a single product.
vii. Application
Hadoop is having large scale processing.
Whereas, MongoDB has real-time extraction and processing.
viii. Low latency
Hadoop focuses more on high throughput rather than low-latency
MongoDB can handle the data at very low-latency, it supports real-time data mining
ix. Frameworks
Hadoop is a Big Data framework, which can handle a wide variety of Big Data requirements.
MongoDB is a NoSQL DB, which can handle CSV/JSON.
x. Data Volumes
Hadoop can handle huge volumes of data, in the range of 1000s of PBs.
MongoDB can handle the moderate size of data, in the range of 100s of TBs.
xi. Data Format
Hadoop can handle any format of data structured, semi-structured or unstructured.
MongoDB can handle only CSV and JSON data.
xii. Geospatial Indexing
Hadoop can’t handle geospatial data efficiently.
MongoDB can analyze geospatial data with its ability of geospatial indexing.
Summary of Hadoop Vs MongoDB
Hence, we have seen the complete Hadoop vs MongoDB with advantages and disadvantages to prove the best tool for Big Data.
A primary difference between MongoDB and Hadoop is that MongoDB is actually a database, while Hadoop is a collection of different software components that create a data processing framework.
Both of them are having some advantages which make them unique but at the same time, both have some disadvantages.
So, this was all about the difference between Hadoop and MongoDB. Hope, you like it.
Share your feedback in the comment section!
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google




