Hadoop 2 vs Hadoop 3 – Why You Should Work on Hadoop Latest Version
In the year 2011 Hadoop was launched for common use. Since then it has undergone many changes in three different versions. Hadoop 3 combines the efforts of hundreds of contributors over the last six years since Hadoop 2 launched. In this tutorial, we will see how Hadoop 3.x adds value over Apache Hadoop 2.x. So, let’s start the Hadoop 2 vs Hadoop 3 comparison and find why you should use Hadoop 3.
Hadoop 2 vs Hadoop 3 – Why You Should Work on Hadoop Latest Version
Hadoop 2 vs Hadoop 3 – Feature-wise Comparison
Below is a feature-wise comparison of Hadoop 2 vs Hadoop 3, this will tell you what’s new in Hadoop 3. So, let’s discuss Hadoop 2 vs Hadoop 3 comparison in detail –
1. Minimum Supported Java Version
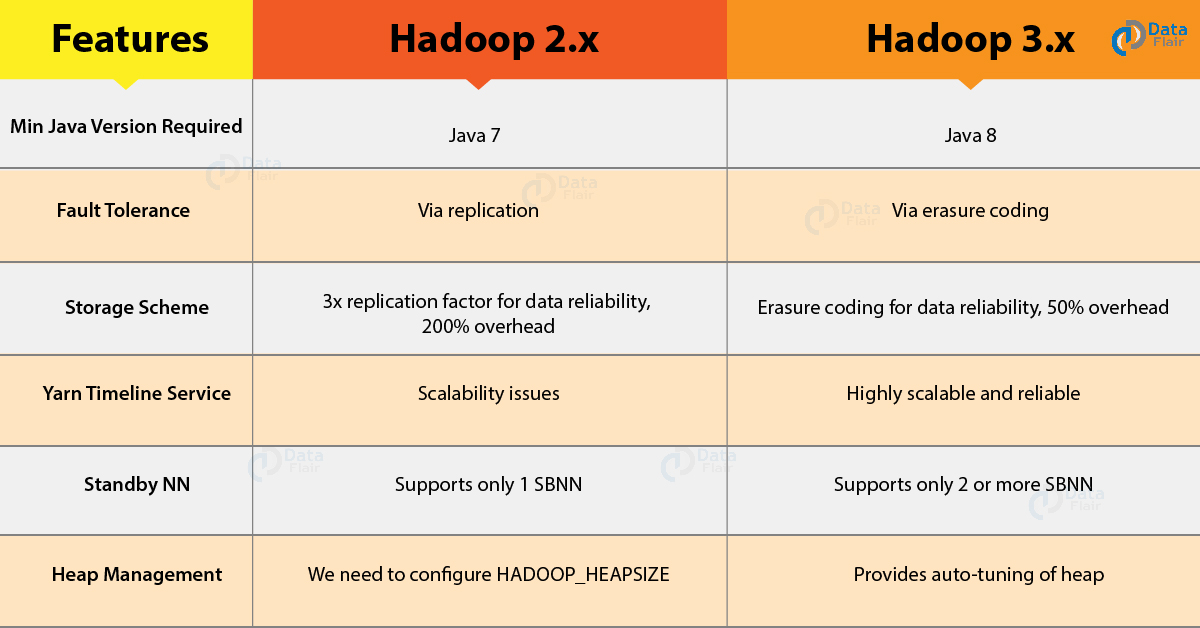
Hadoop 2.x: For Hadoop 2.x to work minimum version of Java required is Java 7
Hadoop 3.x: If you want to run jar files in Hadoop 3.x, the minimum version of Java required is version 8. Most of the libraries in Hadoop 3.x supports Java 8. To take advantage of the enhanced features in Hadoop 3.x we need to upgrade to JDK 8.
2. Fault Tolerance
Hadoop 2.x: Replication technique provides for fault tolerance in Hadoop 2.x. We can configure the replication factor as per the requirement. Its default value is three. In the event of loss of any file block, Hadoop recovers it from the existing replicated blocks.
Hadoop 3.x: This version of Hadoop provides the technique of Erasure Coding for Fault Tolerance. Under erasure coding the blocks are not replicated in fact HDFS calculates the parity blocks for all file blocks. Now whenever the file blocks get corrupted, the Hadoop framework recreates using the remaining blocks along with the parity blocks.
3. Storage Overhead
Hadoop 2.x: The storage overhead in Hadoop 2.x is 200% with the default replication factor of 3. Suppose a file “A” divides into 6 blocks in HDFS. With a replication factor of 3, we would be having 18 blocks for the file “A” stored in the system. From this, we can see
Storage overhead = No. Of Extra Blocks/No. of original blocks * 100
=12/6*100
= 200%
Hadoop 3.x: As Hadoop 3.x adopts Erasure Coding for fault tolerance, it minimizes the storage overhead of the data. Again take the example of a file with 6 blocks. Erasure Coding creates 3 more parity blocks.
Storage overhead = 3/6*100 = 50%
From the above example, we can see that storage overhead is drastically reduced.
4. YARN Timeline Service
Hadoop 2.x: Timeline service version v.1.x comes along with this Hadoop 2.x. This version of the Timeline is not scalable beyond small clusters. It has a single instance of writer and storage running.
Hadoop 3.x: In Hadoop 3.x we will be using Timeline service version v.2. This version of Timeline service provides for more scalability, reliability and enhanced usability by introducing flows and aggregation. This version of the Timeline is more scalable than its previous version. It has scalable back-end storage and distributed writer architecture.
5. Support for opportunistic containers
Hadoop 2.x: Hadoop 2.x works on the principle of guaranteed containers. In this, the container will start running immediately as there is a guarantee that the resources will be available. But it has two drawbacks
a) FeedBack Delays – Once the container finishes execution it notifies resource manager about the released resources. When the Resource Manager schedules a new container at that node, the application master gets notified. Then AM starts the new container. Hence there is a delay introduced because of these notifications given to RM and AM.
b) Allocated v/s utilized resources – The resources which RM allocates to the container can be under-utilized. For example, RM may allocate a container 4 GB of memory out of which it uses only 2GB. This lowers the effective resource utilization.
Hadoop 3.x: To eradicate the above drawbacks Hadoop 3.x implements opportunistic containers. In this case, containers wait in a queue if the resources are unavailable. The opportunistic containers have lower priority than guaranteed containers. Hence the scheduler preempts opportunistic containers to make room for guaranteed containers.
6. Support for Multiple Standby Node
Hadoop 2.x: This version of Hadoop supported a single active NameNode and a single standby NameNode. This architecture is capable of tolerating the failure of one NameNode
Hadoop 3.x: Hadoop 3.x has improved so that we can configure multiple standby Namenode. In a system having three NameNodes configured can tolerate the failure of two NameNodes.
In a typical Hadoop cluster, the administrator configures two or more machines as NameNodes. At any moment, exactly one of the NameNodes is in an active state, and the others are in a standby state. The active NameNode does work for all client operations in the cluster. While the standbys simply maintain enough state to provide a fast failover if necessary.
7. Default Port for Multiple services
Hadoop 2.x: Linux ephemeral port range (32768-61000) are the default ports for multiple services. They have a drawback. Other services in Linux use these ports as well hence they to conflict with Hadoop services. Therefore Hadoop services would fail to bind at startup.
Hadoop 3.x: To mitigate the above drawback this new version moves the default port out of Linux ephemeral port range. This has affected NameNode, secondary NameNode, and DataNode.
NameNode ports: 50470 –> 9871, 50070 –> 9870, 8020 –> 9820
Secondary NameNode ports: 50091 –> 9869, 50090 –> 9868
DataNode ports: 50020 –> 9867, 50010 –> 9866, 50475 –> 9865, 50075 –> 9864
8. New DataNode Balancer
Hadoop 2.x: A single DataNode manages many disks. These disks fill up evenly during a normal write operation. But, adding or replacing disks can lead to significant skew within a DataNode. Hadoop 2.x has HDFS balancer which cannot handle this situation. This is because it implements inter-, not intra-, DN skew.
Hadoop 3.x: The new intra-DataNode balancing functionality handles the above situation. The hdfs diskbalancer CLI invokes intra-DataNode balancer. For using this facility set dfs.disk.balancer.enabled configuration to true on all DataNodes.
So, this was all in Hadoop 2 vs Hadoop 3. Hope you like the above comparison.
Summary
Every firm big or small has understood the benefit of implementing Hadoop and harnessing the power of data. The new version provides better optimization and usability. It also provides certain architectural improvements. These improvements bring even more capabilities into the hands of the users as soon as possible. Before moving on, we recommend you to check the major limitations of Hadoop with their solutions.
Share your valuable feedback through comments, this means a lot to us.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





Well explained.
Hi Dilshad,
We are happy to help you. Refer to our sidebar for more Hadoop tutorials.
very well explaining.
Can we get architectural different between Hadoop2.x and Hadoop3.x ?