Hadoop Reducer – 3 Steps learning for MapReduce Reducer
1. Hadoop Reducer Tutorial – Objective
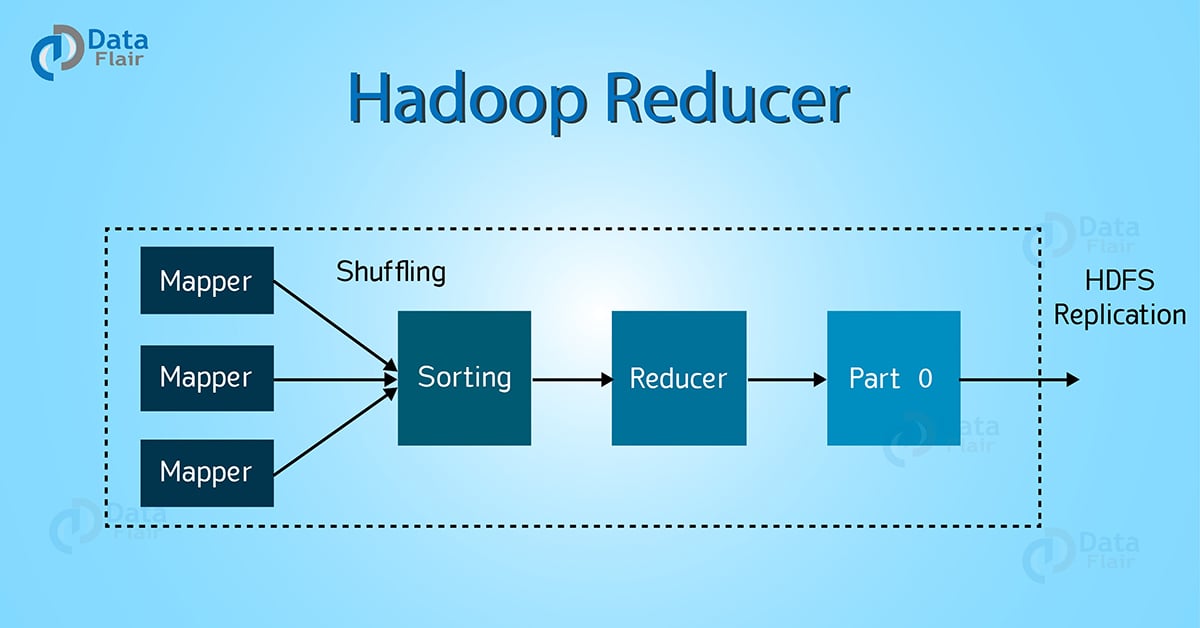
In Hadoop, Reducer takes the output of the Mapper (intermediate key-value pair) process each of them to generate the output. The output of the reducer is the final output, which is stored in HDFS. Usually, in the Hadoop Reducer, we do aggregation or summation sort of computation.
In this Hadoop Reducer tutorial, we will answer what is Reducer in Hadoop MapReduce, what are the different phases of Hadoop MapReduce Reducer, shuffling and sorting in Hadoop, Hadoop reduce phase, functioning of Hadoop reducer class. We will also discuss how many reducers are required in Hadoop and how to change the number of reducers in Hadoop MapReduce.
Hadoop Reducer – 3 Steps learning for MapReduce Reducer
2. What is Hadoop Reducer?
Let’s now discuss what is Reducer in MapReduce first.
The Reducer process the output of the mapper. After processing the data, it produces a new set of output. At last HDFS stores this output data.
Hadoop Reducer takes a set of an intermediate key-value pair produced by the mapper as the input and runs a Reducer function on each of them. One can aggregate, filter, and combine this data (key, value) in a number of ways for a wide range of processing. Reducer first processes the intermediate values for particular key generated by the map function and then generates the output (zero or more key-value pair).
One-one mapping takes place between keys and reducers. Reducers run in parallel since they are independent of one another. The user decides the number of reducers. By default number of reducers is 1.
Read: HDFS Combiner Tutorial
3. Phases of MapReduce Reducer
As you can see in the diagram at the top, there are 3 phases of Reducer in Hadoop MapReduce. Let’s discuss each of them one by one-
3.1. Shuffle Phase of MapReduce Reducer
In this phase, the sorted output from the mapper is the input to the Reducer. In Shuffle phase, with the help of HTTP, the framework fetches the relevant partition of the output of all the mappers.
3.2. Sort Phase of MapReduce Reducer
In this phase, the input from different mappers is again sorted based on the similar keys in different Mappers. The shuffle and sort phases occur concurrently.
Learn Mapreduce Shuffling and Sorting Phase in detail.
Read: Features of HDFS
3.3. Reduce Phase
In this phase, after shuffling and sorting, reduce task aggregates the key-value pairs. The OutputCollector.collect() method, writes the output of the reduce task to the Filesystem. Reducer output is not sorted.
4. MapReduce Number of Reducers
In this section of Hadoop Reducer, we will discuss how many number of Mapreduce reducers are required in MapReduce and how to change the Hadoop reducer number in MapReduce?
With the help of Job.setNumreduceTasks(int) the user set the number of reducers for the job. The right number of reducers are 0.95 or 1.75 multiplied by (<no. of nodes> * <no. of the maximum container per node>).
With 0.95, all reducers immediately launch and start transferring map outputs as the maps finish. With 1.75, the first round of reducers is finished by the faster nodes and second wave of reducers is launched doing a much better job of load balancing.
Increasing the number of MapReduce reducers:
- Increases the Framework overhead.
- Increases load balancing.
- Lowers the cost of failures.
Read: HDFS NameNode High Availability
5. Hadoop Reducer – Conclusion
In conclusion, Hadoop Reducer is the second phase of processing in MapReduce. Hadoop Reducer does aggregation or summation sort of computation by three phases(shuffle, sort and reduce). Thus, HDFS Stores the final output of Reducer. Learn How to Read or Write data to HDFS?
If you find this blog on Hadoop Reducer helpful or you have any query for Hadoop Reducer, so feel free to share with us.
See Also-
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




