Data locality in Hadoop: The Most Comprehensive Guide
1. Data Locality in Hadoop – Objective
In Hadoop, Data locality is the process of moving the computation close to where the actual data resides on the node, instead of moving large data to computation. This minimizes network congestion and increases the overall throughput of the system. This feature of Hadoop we will discuss in detail in this tutorial. We will learn what is data locality in Hadoop, data locality definition, how Hadoop exploits Data Locality, what is the need of Hadoop Data Locality, various types of data locality in Hadoop MapReduce, Data locality optimization in Hadoop and various advantages of Hadoop data locality.

Data locality in Hadoop: The Most Comprehensive Guide
2. The Concept of Data locality in Hadoop
Let us understand Data Locality concept and what is Data Locality in MapReduce?
The major drawback of Hadoop was cross-switch network traffic due to the huge volume of data. To overcome this drawback, Data Locality in Hadoop came into the picture. Data locality in MapReduce refers to the ability to move the computation close to where the actual data resides on the node, instead of moving large data to computation. This minimizes network congestion and increases the overall throughput of the system.
In Hadoop, datasets are stored in HDFS. Datasets are divided into blocks and stored across the datanodes in Hadoop cluster. When a user runs the MapReduce job then NameNode sent this MapReduce code to the datanodes on which data is available related to MapReduce job.
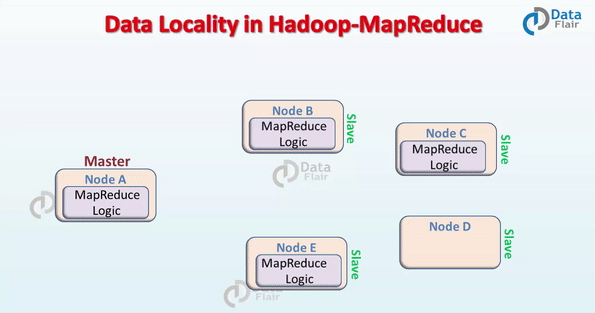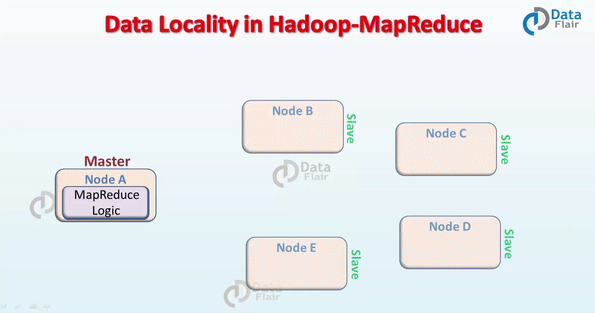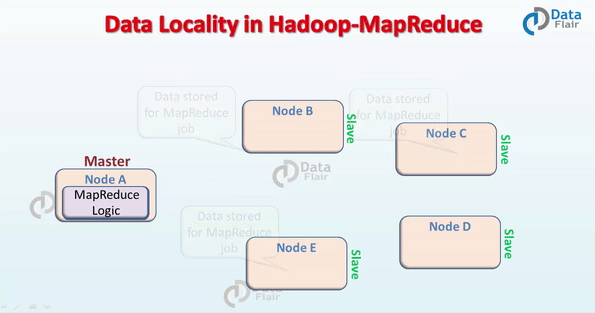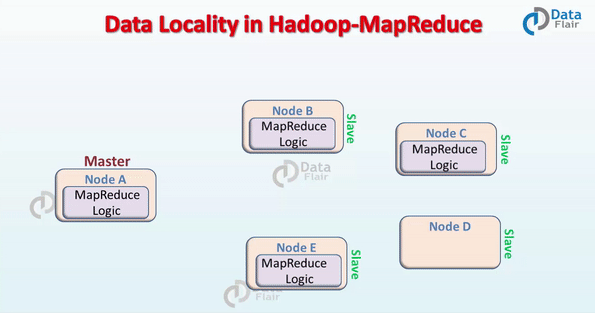
Data Locality in Hadoop – MapReduce
3. Requirements for Data locality in MapReduce
Our system architecture needs to satisfy the following conditions, in order to get the benefits of all the advantages of data locality:
- First of all the cluster should have the appropriate topology. Hadoop code must have the ability to read data locality.
- Second, Hadoop must be aware of the topology of the nodes where tasks are executed. And Hadoop must know where the data is located.
4. Categories of Data Locality in Hadoop
Below are the various categories in which Data Locality in Hadoop is categorized:
i. Data local data locality in Hadoop
When the data is located on the same node as the mapper working on the data it is known as data local data locality. In this case, the proximity of data is very near to computation. This is the most preferred scenario.
ii. Intra-Rack data locality in Hadoop
It is not always possible to execute the mapper on the same datanode due to resource constraints. In such case, it is preferred to run the mapper on the different node but on the same rack.
iii. Inter-Rack data locality in Hadoop
Sometimes it is not possible to execute mapper on a different node in the same rack due to resource constraints. In such a case, we will execute the mapper on the nodes on different racks. This is the least preferred scenario.
5. Hadoop Data Locality Optimization
Although Data locality in Hadoop MapReduce is the main advantage of Hadoop MapReduce as map code is executed on the same data node where data resides. But this is not always true in practice due to various reasons like speculative execution in Hadoop, Heterogeneous cluster, Data distribution and placement, and Data Layout and Input Splitter.
Challenges become more prevalent in large clusters, because more the number of data nodes and data, less will be the locality. In larger clusters, some nodes are newer and faster than the other, creating the data to compute ratio out of balance thus, large clusters tend not to be completely homogenous. In speculative execution even though the data might not be local, but it uses the computing power. The root cause also lies in the data layout/placement and the used Input Splitter. Non-local data processing puts a strain on the network which creates problem to scalability. Thus the network becomes the bottleneck.
We can improve data locality by first detecting which jobs has the data locality problem or degrade over time. Problem-solving is more complex and involves changing the data placement and data layout, using a different scheduler or by simply changing the number of mapper and reducer slots for a job. Then we have to verify whether a new execution of the same workload has a better data locality ratio.
6. Advantages of Hadoop Data locality
There are two benefits of data Locality in MapReduce. Let’s discuss them one by one-
i. Faster Execution
In data locality, the program is moved to the node where data resides instead of moving large data to the node, this makes Hadoop faster. Because the size of the program is always lesser than the size of data, so moving data is a bottleneck of network transfer.
ii. High Throughput
Data locality increases the overall throughput of the system.
7. Data Locality in Hadoop – Conclusion
In conclusion, we can say that, Data locality improves the overall execution of the system and makes Hadoop faster. It reduces the network congestion. Hope this blog helped you to understand the core concept of Hadoop, which empowers the Hadoop functionality. Now we hope you are clear with the Data locality concept. If you find any question related to Hadoop Data Locality, So feel free to share with us. Hope we will help you.
See Also-
In case of any queries or feedback feel free to drop a comment in the comment section below and we will get back to you.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





HEY
hey
HEY