Hadoop Partitioner – Internals of MapReduce Partitioner
1. Hadoop Partitioner / MapReduce Partitioner
In this MapReduce Tutorial, our objective is to discuss what is Hadoop Partitioner. The Partitioner in MapReduce controls the partitioning of the key of the intermediate mapper output. By hash function, key (or a subset of the key) is used to derive the partition. A total number of partitions depends on the number of reduce task. Here we will also learn what is the need of Hadoop partitioner, what is the default Hadoop partitioner, how many practitioners are required in Hadoop and what do you mean by poor partitioning in Hadoop along with ways to overcome MapReduce poor partitioning.
Hadoop Partitioner – Internals of MapReduce Partitioner
2. What is Hadoop Partitioner?
Before we start with MapReduce partitioner, let us understand what is Hadoop mapper, Hadoop Reducer, and combiner in Hadoop?
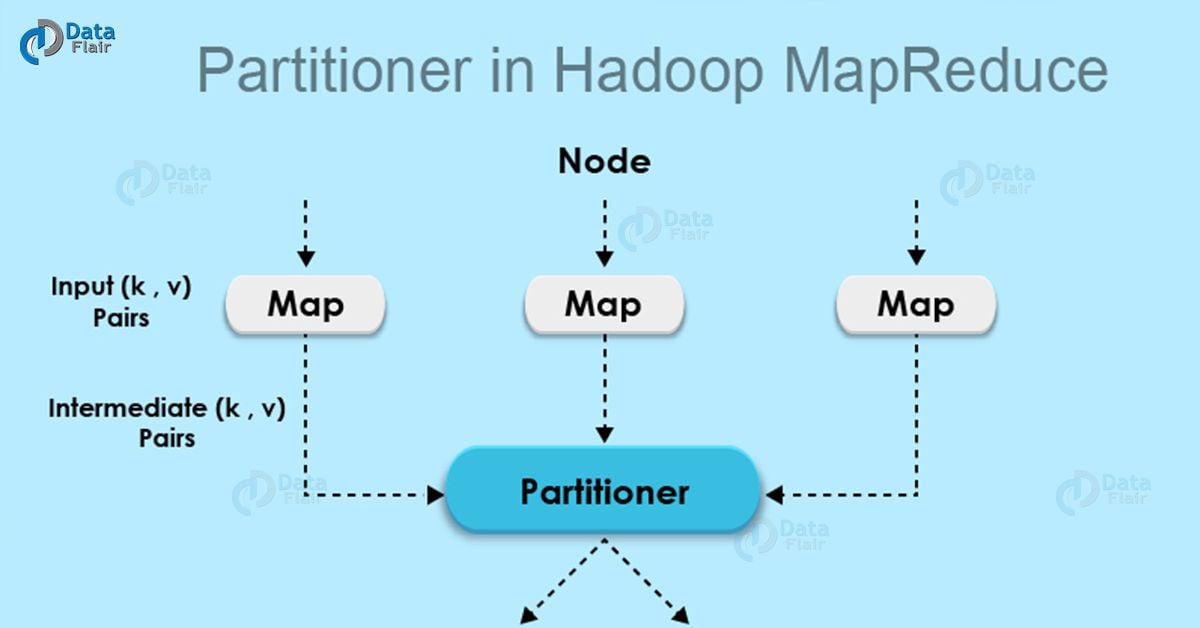
Partitioning of the keys of the intermediate map output is controlled by the Partitioner. By hash function, key (or a subset of the key) is used to derive the partition. According to the key-value each mapper output is partitioned and records having the same key value go into the same partition (within each mapper), and then each partition is sent to a reducer. Partition class determines which partition a given (key, value) pair will go. Partition phase takes place after map phase and before reduce phase. Lets move ahead with need of Hadoop Partitioner and if you face any difficulty anywhere in Hadoop MapReduce tutorial, you can ask us in comments.
Read: A Guide on Big Data Hadoop for beginners
3. Need of Hadoop MapReduce Partitioner?
Let’s now discuss what is the need of Mapreduce Partitioner in Hadoop?
MapReduce job takes an input data set and produces the list of the key-value pair which is the result of map phase in which input data is split and each task processes the split and each map, output the list of key-value pairs. Then, the output from the map phase is sent to reduce task which processes the user-defined reduce function on map outputs. But before reduce phase, partitioning of the map output take place on the basis of the key and sorted.
This partitioning specifies that all the values for each key are grouped together and make sure that all the values of a single key go to the same reducer, thus allows even distribution of the map output over the reducer.
Partitioner in Hadoop MapReduce redirects the mapper output to the reducer by determining which reducer is responsible for the particular key.
Read: Hadoop MapReduce tutorial
4. Default MapReduce Partitioner
The Default Hadoop partitioner in Hadoop MapReduce is Hash Partitioner which computes a hash value for the key and assigns the partition based on this result.
5. How many Partitioners are there in Hadoop?
The total number of Partitioners that run in Hadoop is equal to the number of reducers i.e. Partitioner will divide the data according to the number of reducers which is set by JobConf.setNumReduceTasks() method. Thus, the data from single partitioner is processed by a single reducer. And partitioner is created only when there are multiple reducers.
6. Poor Partitioning in Hadoop MapReduce
If in data input one key appears more than any other key. In such case, we use two mechanisms to send data to partitions.
- The key appearing more will be sent to one partition.
- All the other key will be sent to partitions according to their hashCode().
But if hashCode() method does not uniformly distribute other keys data over partition range, then data will not be evenly sent to reducers. Poor partitioning of data means that some reducers will have more data input than other i.e. they will have more work to do than other reducers. So, the entire job will wait for one reducer to finish its extra-large share of the load.
How to overcome poor partitioning in MapReduce?
To overcome poor partitioner in Hadoop MapReduce, we can create Custom partitioner, which allows sharing workload uniformly across different reducers.
Read: MapReduce DataFlow
This was all on Hadoop Mapreduce Partitioners.
7. Hadoop MapReduce – Conclusion
In conclusion, Hadoop Partitioner allows even distribution of the map output over the reducer. In Partitioner, partitioning of map output take place on the basis of the key and sorted.
See Also-
I hope this post has helped you in understanding the actual need of Hadoop partitioner. If you have any questions related to Mapreduce Partitioner, please drop me a comment below.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





Which is the fastest phase in map reduce job: mapper, combiner, record reader, reducer?
what is the position of partitioner? is it after combiner?
before combiner
Partitioner should be placed after the combiner.
There is no use in partitioning key-values before combining .
What are the differences between partitioner and Multiple Outputs?
How to choose the right one?
Thanks
hello,
in the content you mentioned that the number of partitioners is equal to the number of reducers. But, that’s not correct. Number of partitions (not partitioners) is equal to number of reducers. Please correct
I’ve two files in HDFS.
File1.txt has two line (this is first line,this is second line), File2.txt had one line (this is third line) and i’m using two reducers . can you please explain how partitioner distribute data .