Hadoop RecordReader – How RecordReader Works in Hadoop?
1. Hadoop RecordReader Tutorial – Objective
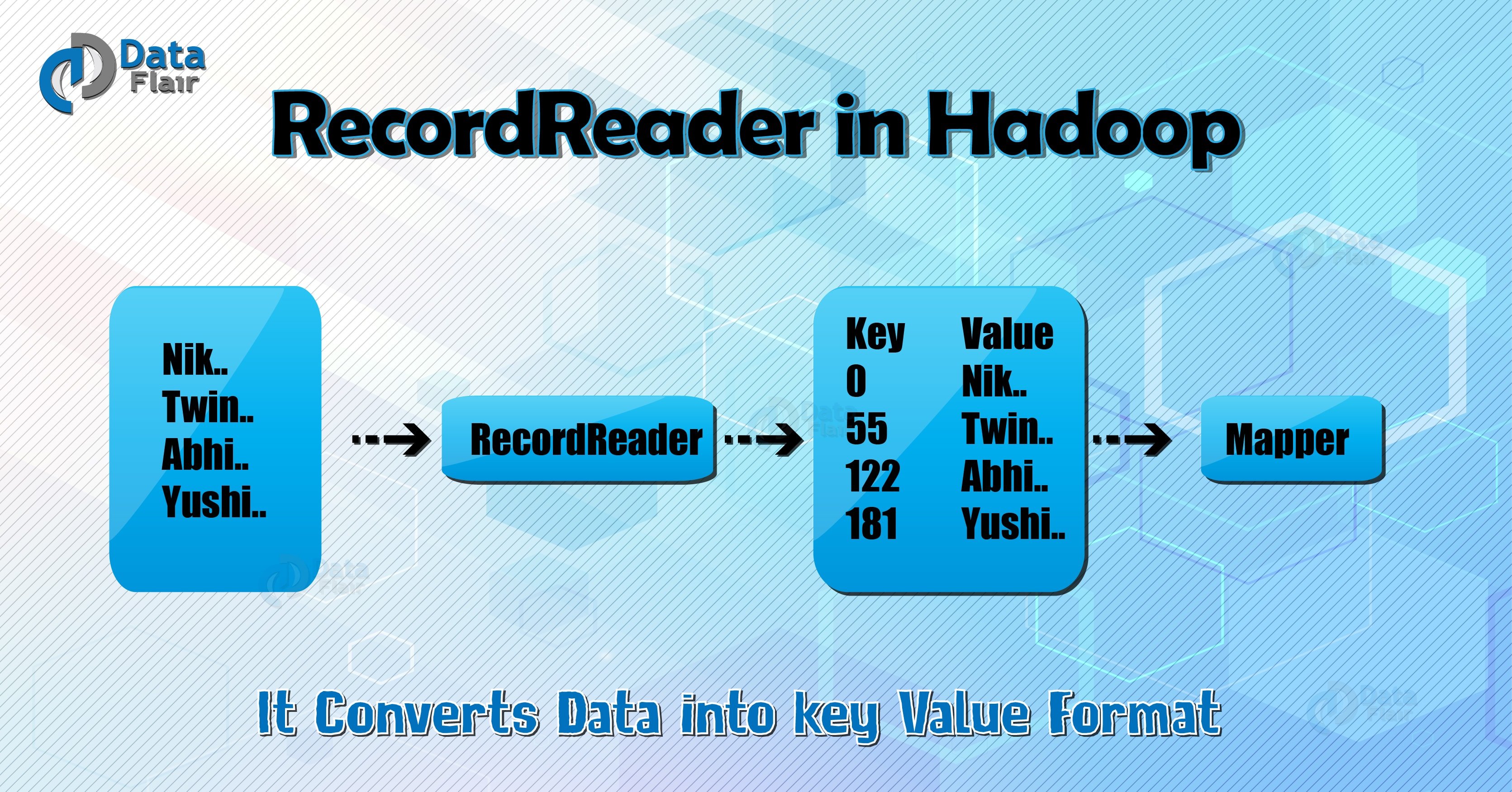
In this Hadoop RecordReader Tutorial, We are going to discuss the important concept of Hadoop MapReduce i.e. RecordReader. The MapReduce RecordReader in Hadoop takes the byte-oriented view of input, provided by the InputSplit and presents as a record-oriented view for Mapper. It uses the data within the boundaries that were created by the InputSplit and creates Key-value pair.
This blog will answer what is RecordReader in Hadoop, how Hadoop RecordReader works and types of Hadoop RecordReader – SequenceFileRecordReader and Line RecordReader, the maximum size of a record in Hadoop.
Learn How to Install Hadoop on Single Machine. and Hadoop Installation on a multi-node cluster.

Hadoop MapReduce RecordReader
2. What is Hadoop RecordReader?
To understand recordreader in Hadoop, we need to understand the Hadoop data flow. So, Let’s see how the data flow in Hadoop?
MapReduce has a simple model of data processing. Inputs and Outputs for the map and reduce functions are key-value pairs. The map and reduce functions in Hadoop MapReduce have the following general form:
Hadoop RecordReader and its types.
- map: (K1, V1) → list(K2, V2)
- reduce: (K2, list(V2)) → list(K3, V3)
Now before processing, it needs to know on which data to process, this is achieved with the InputFormat class. InputFormat is the class which selects the file from HDFS that should be input to the map function. An InputFormat is also responsible for creating the InputSplits and dividing them into records. The data is divided into the number of splits(typically 64/128mb) in HDFS. This is called as inputsplit which is the input that is processed by a single map.
InputFormat class calls the getSplits() function and computes splits for each file and then sends them to the JobTracker, which uses their storage locations to schedule map tasks to process them on the TaskTrackers. Map task then passes the split to the createRecordReader() method on InputFormat in task tracker to obtain a RecordReader for that split. The RecordReader load’s data from its source and converts into key-value pairs suitable for reading by the mapper.
Hadoop RecordReader uses the data within the boundaries that are being created by the inputsplit and creates Key-value pairs for the mapper. The “start” is the byte position in the file where the RecordReader should start generating key/value pairs and the “end” is where it should stop reading records. In Hadoop RecordReader, the data is loaded from its source and then the data is converted into key-value pairs suitable for reading by the Mapper. It communicates with the inputsplit until the file reading is not completed.
Read: Mapper in Mapreduce
3. How Hadoop RecordReader works?
Let us now see the working of RecordReader in Hadoop.
A RecordReader is more than iterator over records, and map task uses one record to generate key-value pair which is passed to the map function. We can see this by using mapper’s run function:
[php]public void run(Context context) throws IOException, InterruptedException{
<pre>setup(context);
while(context.nextKeyValue())
{
map(context.setCurrentKey(),context.getCurrentValue(),context)
}
cleanup(context);
}[/php]
After running setup(), the nextKeyValue() will repeat on the context, to populate the key and value objects for the mapper. The key and value is retrieved from the record reader by way of context and passed to the map() method to do its work. An input to the map function, which is a key-value pair(K, V), gets processed as per the logic mentioned in the map code. When the record gets to the end of the record, the nextKeyValue() method returns false.
A RecordReader usually stays in between the boundaries created by the inputsplit to generate key-value pairs but this is not mandatory. A custom implementation can even read more data outside of the inputsplit, but it is not encouraged a lot.
Read: Reducer in MapReduce
4. Types of Hadoop RecordReader in MapReduce
The RecordReader instance is defined by the InputFormat. By default, it uses TextInputFormat for converting data into a key-value pair. TextInputFormat provides 2 types of RecordReaders:
i. LineRecordReader
Line RecordReader in Hadoop is the default RecordReader that textInputFormat provides and it treats each line of the input file as the new value and associated key is byte offset. LineRecordReader always skips the first line in the split (or part of it), if it is not the first split. It read one line after the boundary of the split in the end (if data is available, so it is not the last split).
ii. SequenceFileRecordReader
It reads data specified by the header of a sequence file.
Read: Partitioner in MapReduce
5. Maximum size for a Single Record
There is a maximum size allowed for a single record to be processed. This value can be set using below parameter.
[php]conf.setInt(“mapred.linerecordreader.maxlength”, Integer.MAX_VALUE);[/php]
A line with a size greater than this maximum value (default is 2,147,483,647) will be ignored.
Read: Combiner in MapReduce
6. Hadoop RecordReader Tutorial – Conclusion
Hence, we have discussed RecordReader in Hadoop in detail. In our next blog, we will provide you the end to end job execution flow of Hadoop MapReduce. If you have any query related to Hadoop RecordReader, you can share with us in a comment section given below. We will be happy to solve them.
See Also-
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





This is excellent post
1.Is Mapreduce platform independent?
2.Is Mapreduce Language specific?
I guess not for both of your questions.
Map Reduce is just a programming model and a processing technique.
But Hadoop has created a well coupled pack of services to make it easier to process and manipulate high volumes of data.
and Java because of its robustness and flexibility has been choice of many big data companies and individuals.
We have a record data present in multiple lines like below. Can you please suggest me a good way to read it in spark.
Schema:
District, SchoolId, SchoolName
StudentId, maths^science^language
File Data:
Chennai, 154678, SRM School
Student1, 80^90^65
Student2, 90^75^89
What we need is a dataset with data like below
154678, Student1, 80^90^65
154678, Student2, 90^75^89