What is Hadoop Streaming? Explore How Streaming Works
Is it possible to write MapReduce jobs in languages other than Java?
Hadoop streaming is the utility that enables us to create or run MapReduce scripts in any language either, java or non-java, as mapper/reducer.
The article thoroughly explains Hadoop Streaming. In this article, you will explore how Hadoop streaming works. Later in this article, you will also see some Hadoop Streaming command options.
Introduction to Hadoop Streaming
By default, the Hadoop MapReduce framework is written in Java and provides support for writing map/reduce programs in Java only. But Hadoop provides API for writing MapReduce programs in languages other than Java.
Hadoop Streaming is the utility that allows us to create and run MapReduce jobs with any script or executable as the mapper or the reducer. It uses Unix streams as the interface between the Hadoop and our MapReduce program so that we can use any language which can read standard input and write to standard output to write for writing our MapReduce program.
Hadoop Streaming supports the execution of Java, as well as non-Java, programmed MapReduce jobs execution over the Hadoop cluster. It supports the Python, Perl, R, PHP, and C++ programming languages.
Syntax for Hadoop Streaming
You can use the below syntax to run MapReduce code written in a language other than JAVA to process data using the Hadoop MapReduce framework.
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc
Parameters Description
| Parameter | Description |
| -input myInputDirs \ | Input location for mapper |
| -output myOutputDir \ | Output location for reducer |
| -mapper /bin/cat \ | Mapper executable |
| -reducer /usr/bin/wc | Reducer executable |
How Streaming Works
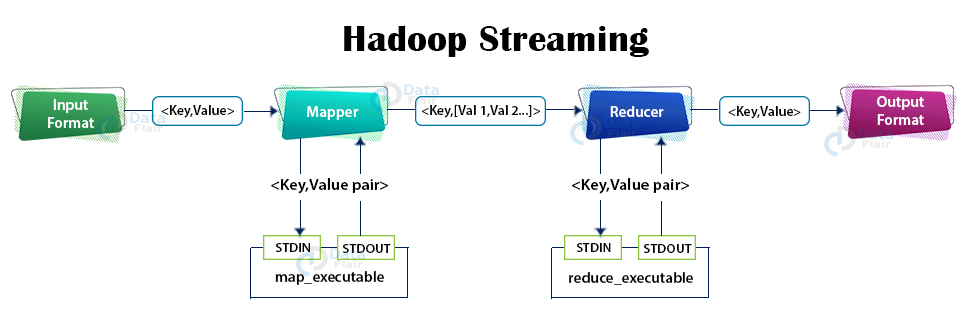
Let us now see how Hadoop Streaming works.
- The mapper and the reducer (in the above example) are the scripts that read the input line-by-line from stdin and emit the output to stdout.
- The utility creates a Map/Reduce job and submits the job to an appropriate cluster and monitor the job progress until its completion.
- When a script is specified for mappers, then each mapper task launches the script as a separate process when the mapper is initialized.
- The mapper task converts its inputs (key, value pairs) into lines and pushes the lines to the standard input of the process. Meanwhile, the mapper collects the line oriented outputs from the standard output and converts each line into a (key, value pair) pair, which is collected as the result of the mapper.
- When reducer script is specified, then each reducer task launches the script as a separate process, and then the reducer is initialized.
- As reducer task runs, it converts its input key/values pairs into lines and feeds the lines to the standard input of the process. Meantime, the reducer gathers the line-oriented outputs from the stdout of the process and converts each line collected into a key/value pair, which is then collected as the result of the reducer.
- For both mapper and reducer, the prefix of a line until the first tab character is the key, and the rest of the line is the value except the tab character. In the case of no tab character in the line, the entire line is considered as key, and the value is considered null. This is customizable by setting -inputformat command option for mapper and -outputformat option for reducer that we will see later in this article.
Let us now study some of the streaming command options.
Streaming Command Options
Hadoop Streaming supports some streaming command options. It also supports generic command option which we will see later in this article.
The general command line syntax is:
mapred streaming [genericOptions] [streamingOptions]
The Streaming command options are:
1. -input directoryname or filename (Required)
It specifies the input location for mapper.
2. -output directoryname (Required)
This streaming command option specifies the output location for reducer.
3. -mapper executable or JavaClassName (Optional)
It specifies the Mapper executable. If it is not specified then IdentityMapper is used as the default.
4. -reducer executable or JavaClassName (Optional)
It specifies the Reducer executable. If it is not specified then IdentityReducer is used as the default.
5. -inputformat JavaClassName (Optional)
The class you supply should return key/value pairs of Text class. If not specified then TextInputFormat is used as the default.
6. -outputformat JavaClassName (Optional)
The class you supply should take key/value pairs of Text class. If not specified then TextOutputformat is used as the default.
7. -numReduceTasks (Optional)
It specifies the number of reducers.
8. -file filename (Optional)
It makes the mapper, reducer, or combiner executable available locally on the compute nodes.
9. -mapdebug (Optional)
It is the script which is called when map task fails.
10. -reducedebug (Optional)
It is the script to call when reduce task fails.
11. -partitioner JavaClassName (Optional)
This option specifies the class that determines which reducer a key is sent to.
Thus these are some Hadoop streaming command options.
Summary
I hope after reading this article, you clearly understand Hadoop Streaming. Basically Hadoop Streaming allows us to write Map/reduce jobs in any languages (such as Python, Perl, Ruby, C++, etc) and run as mapper/reducer. Thus it enables a person who is not having any knowledge of Java to write MapReduce job in the language of its own choice.
The article has also described the basic communication protocol between the MapReduce Framework and the Streaming mapper/reducer. The article also explained some of the Hadoop streaming command options.
Now, its time to explore 10 Most Frequently Used Hadoop Commands.
If you still have any queries in the Hadoop streaming tutorial then do let us know.
Keep Learning!!
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





Can you provide some real life examples with explaination for hadoop streaming